Beginner
Karpathy: 'Coding' Is No Longer the Right Verb
Karpathy: 'Coding' Is No Longer the Right Verb
Karpathy: "Coding" Is No Longer the Right Verb#
Andrej Karpathy says he has barely written a single line of code by hand since December 2024.
This OpenAI founding member, former Tesla AI Director, and now independent AI researcher and founder of Eureka Labs has 1.9 million followers on X, and every post he makes sends ripples through the AI community. Recently, he did two things that shook the scene: open-sourced AutoResearch (letting AI Agents automatically run experiments to optimize model training) and released MicroGPT (a full GPT implementation in just 200 lines of pure Python).
He recently appeared on Sarah Guo's No Priors podcast, discussing how coding Agents are changing engineers' daily routines, AutoResearch and recursive self-improvement, the "jaggedness" of AI, the power balance between open and closed source, the pace difference between the physical and digital worlds, and the future of education in the Agent era.
Note: Sarah Guo is the founder of AI investment fund Conviction and a former Greylock partner. No Priors is the AI podcast she co-hosts with Elad Gil; this episode was a solo interview by Sarah.
Original video link: https://www.youtube.com/watch?v=kwSVtQ7dziU

Key Takeaways#
- Karpathy has barely written code by hand since December 2024. His workflow has shifted from "coding" to "directing Agents," with multi-Agent parallelism becoming the norm. His core anxiety has shifted from GPU utilization to Token throughput.
- He let AutoResearch run overnight and discovered optimizations he had missed after two years of manual tuning—validating the core idea of "removing the human from the loop."
- AI models are advancing rapidly in verifiable domains (code, math) but are almost stagnant in non-verifiable domains—the jokes ChatGPT told three years ago are still the same today.
- The gap between open-source models and the closed-source frontier has narrowed from 18 months to 6-8 months. He believes "centralization has a poor historical record" and hopes for more labs and open platforms.
- The digital space will undergo massive transformation first, followed by digital/physical interfaces, and finally the physical world—"atoms are a million times harder than bits."
- The future of education is not explaining to people, but explaining to Agents. His MicroGPT Agent fully understands it but couldn't have invented it. "What the Agent cannot do is your job."
"Coding" Is No Longer the Right Verb#
Sarah Guo said she once walked into an office and saw Karpathy completely immersed in work. She asked what he was doing, and he said: "I have to spend 16 hours a day directing my Agents."
> Coding is not even the right verb anymore. I have to spend 16 hours a day directing my Agents.
> ("Code's not even the right verb anymore. I have to express my will to my agents for 16 hours a day.")
Karpathy says he has been in a state he calls "AI psychosis." December 2024 was the turning point when he flipped from "writing 80% himself, Agent writes 20%" to "writing 20% himself, Agent writes 80%." He says the ratio is likely even more extreme now; since December, he has barely written a single line of code by hand.
He tried explaining this to his parents but felt ordinary people have no idea how drastic this change is. If you look at any software engineer's workstation, you'll see their default workflow has been completely different since December 2024.

Sarah added a scene: the engineering team at Conviction where she works, none of them write code by hand. The engineers all wear microphones, whispering to their Agents. She said at first she thought they were crazy, then realized they were just ahead of the curve.
So what's the bottleneck for projects now? Karpathy says everything feels like a "skill issue"—not a lack of capability, but you haven't figured out how to chain existing capabilities together. The Agent instructions aren't good enough, the memory tools aren't mature enough—when things go wrong, it always feels like you didn't get it right.
He mentioned a famous photo by Peter Steinberger: a screen densely tiled with windows of Codex Agents.
Note: Peter Steinberger is an Austrian developer and founder of the OpenClaw open-source Agent project. OpenClaw is an autonomous AI agent controllable via messaging platforms like WhatsApp and Telegram. It gained over 240k stars on GitHub in early 2026, after which Steinberger joined OpenAI in February 2026. Codex is OpenAI's programming Agent product.
Peter's working style: each Agent in high-effort mode takes about 20 minutes to complete a task. He switches between a dozen code repositories simultaneously, assigning work to different Agents. The unit of operation is no longer "write a line of code" or "add a function," but "assign this feature to Agent 1, that non-conflicting feature to Agent 2," then review the results based on how much you care about code quality.
Karpathy used an analogy. During his PhD, he would get anxious if a GPU was idle and not running experiments—that meant wasted compute. Now it's not GPUs; it's Tokens.
> What is your Token throughput? What Token throughput do you command?
> ("What is your token throughput and what token throughput do you command?")
He made an interesting observation: For at least the past decade, in many engineering tasks, people didn't feel constrained by compute. But with this capability leap, you suddenly realize the constraint is no longer compute resources, but yourself. Sarah said this is actually exciting—because you can get better, it becomes addictive.
The Soul of an Agent—Why Personality Design Matters#
Sarah asked: If everyone spends 16 hours honing their skills with programming Agents, what would "mastery" look like a year from now?
Karpathy said everyone is moving to a higher level. It's not about single Agents anymore—it's about how multiple Agents collaborate and team up. He introduced a concept called a Claw, something more "persistent" than a regular Agent: it has its own sandbox, a more mature memory system, and runs in a loop even when you're not watching.
He thinks OpenClaw's memory system is much more mature than default Agent tools. The default memory mechanism just compresses when the context window is full, while OpenClaw has a more refined scheme.
Then Karpathy discussed a topic many are interested in: Agent personality design.
He said Peter Steinberger innovated in at least five directions simultaneously with OpenClaw—memory system, tool access, persistent looping, WhatsApp unified interface—and one particularly important but often overlooked aspect is the "SOUL.md document" that defines the Agent's personality.
He compared the personalities of several Agents:
Claude Code feels like a teammate; it gets excited with you. Karpathy said Anthropic has a good handle on the "degree of flattery": when he proposes a half-baked idea, Claude isn't overly enthusiastic, just says "Okay, we can do that." But when he thinks he's proposed a genuinely good idea, Claude does give more positive feedback. He found himself trying to "win Claude's praise."
> When Claude praises me, I do feel like I slightly deserve it... I'm trying to earn its praise, which is really weird.
> ("When Claude gives me praise I do feel like I slightly deserve it... I'm trying to earn its praise which is really weird.")
In contrast, OpenAI's Codex Agent is cold. ChatGPT's Codex is lively, but the programming Agent version of Codex is very dry—it doesn't care what you're doing, just "Oh, I implemented it." You ask, "Do you understand what we're building?" and it has no reaction.
Karpathy believes many tools underestimate the importance of personality design.

Dobby the Elf—Three Prompts Took Over an Entire House#
Sarah asked if Karpathy had done anything interesting with Claw outside of programming.
He said in January this year, he went through a "Claw psychosis period" and built a home automation Agent called Dobby the Elf Claw.
The process: He told the Agent, "I think I have Sonos speakers in my house, can you find them?" The Agent scanned all devices on the local network, found the Sonos system—discovered it had no password protection. The Agent logged in, found the API via search, reverse-engineered the entire control flow. Then asked if he wanted to try it. He said, "Can you play some music in the study?" and music started playing. Three prompts.
Lights followed the same process. Agent scanned, discovered, reverse-engineered the API, created a control panel. He said "bedtime," and all the lights in the house turned off. Eventually, Dobby could control his home's lighting, HVAC, curtains, pool, and spa equipment, and even took over the security system.
The security part was interesting: He has an external camera; the system first does change detection (something moved), then sends the image to the Qwen vision model for analysis, and finally sends him a message via WhatsApp—with a picture and description of the outside, like "A FedEx truck just stopped, you might have received a package."
Note: Qwen is a series of multimodal AI models developed by Alibaba Cloud, supporting image understanding and text generation.
Karpathy said Dobby now manages the entire house, and he communicates with it via WhatsApp. Previously, he needed six different apps to control these smart home devices; now he needs none. Dobby handles everything in natural language.
He admitted he hasn't pushed this paradigm to the limit—some people have done crazier things—but just the home automation scenario alone is "extremely helpful and also very illuminating."

Agent-First Internet—Apps Shouldn't Exist#
Sarah posed a sharp question: Is what Karpathy did—using an Agent to unify six smart home apps—evidence that people don't actually want the software we have today?
Karpathy said there's a feeling that those smart home apps in the App Store "shouldn't exist" in a sense. There should just be APIs, and Agents call them directly. An LLM can drive tools, call all interfaces, and do quite complex things—while any single app can't achieve the cross-system integration an Agent can.
He used a treadmill as another example. He wanted to track his cardio frequency but didn't want to log into some web UI and go through a bunch of steps. All these things should just expose APIs, and Agents do the intelligent gluing.
He made a judgment: The industry must reconfigure in many ways. The customer is no longer a human; it's an Agent acting on behalf of humans. This refactoring will be substantial.
Some might argue: Do you expect ordinary people to program by feel like this? Karpathy admitted that today it still requires some摸索 (exploration), and you have to make some design decisions. But he thinks within a year or two, these things will become basic, free, and even open-source models can do it. It will become "ephemeral software"—the Claw has a machine, it will handle all the details, you don't need to be involved. You just need to talk.
AutoResearch—Removing Yourself from the Loop#
Sarah asked Karpathy why he hasn't pushed Claw into more scenarios. He gave two reasons: first, it's too distracting, new things are happening everywhere; second, security and privacy concerns—he hasn't given Agents access to email and calendar because "still a bit uneasy, the tech is too new and rough."
Then the topic shifted to AutoResearch. Sarah asked about the motivation.
Karpathy said he previously tweeted something like: To fully utilize existing tools, you must remove yourself as the bottleneck. You can't be there waiting to prompt the next step. You set everything up so the system runs fully autonomously.
> To get the most out of the tools that have become available now, you have to remove yourself as the bottleneck.
> ("To get the most out of the tools that have become available now you have to remove yourself as the bottleneck.")
He said this is the essence of competition now: increase your leverage. You occasionally invest a few Tokens, and a massive amount of work happens on your behalf.
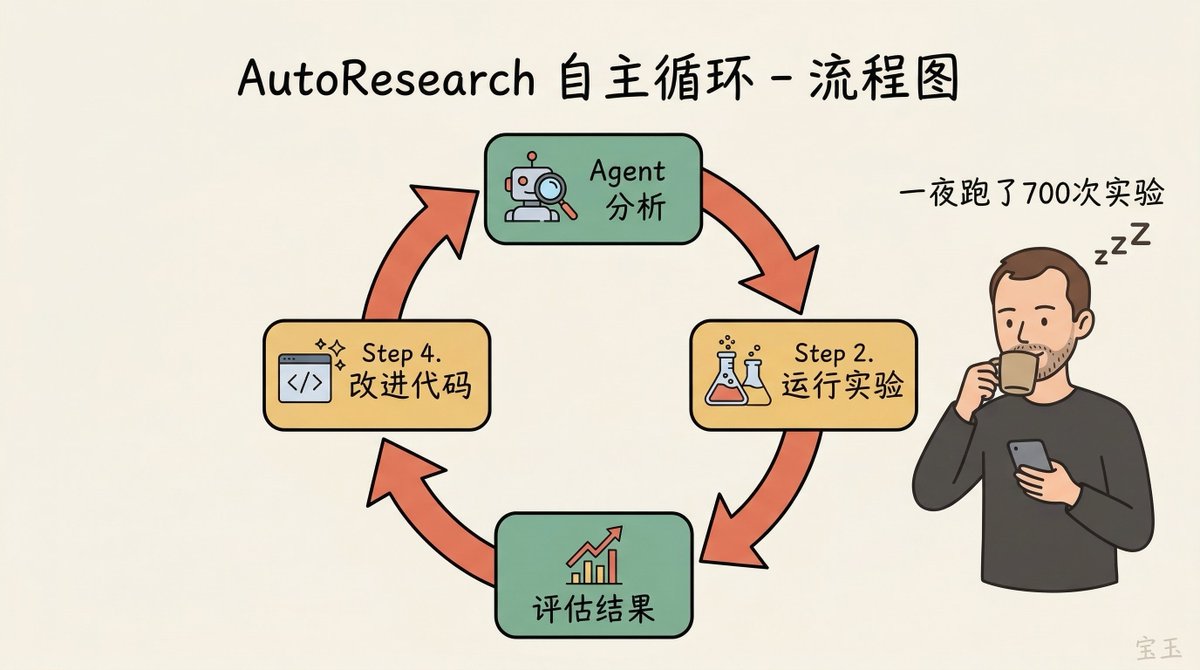
AutoResearch is a concrete implementation of this idea. He has a project called nanochat, which he's been using as a small playground for training LLMs. Many are puzzled by his obsession with training GPT-2 level models, but for him, it's a testbed for recursive self-improvement—exactly what all frontier labs are pursuing.
Note: nanochat is a minimal LLM training framework maintained by Karpathy. AutoResearch was open-sourced on March 7, 2026. Its core is a ~630-line Python script that lets an AI Agent autonomously run experiments in a loop on a single GPU.
He said he had tuned nanochat quite well the "old-school" way—twenty years of research, extensive hyperparameter searches and experiments. Then he let AutoResearch run overnight.
The Agent came back with optimizations he hadn't discovered: weight decay on value embeddings was missing, Adam optimizer's beta parameters weren't tuned enough. And these parameters had joint interaction effects—tuning one changed the optimal values of others.
The public data was even more staggering: two days of continuous runs, ~700 experiments, discovered ~20 stacking improvements, reducing the "Time to GPT-2" leaderboard metric from 2.02 hours to 1.80 hours—an 11% efficiency gain on a project he thought was already well-tuned. Shopify CEO Tobias Lütke used the same method on his company's internal data, ran 37 experiments, and achieved a 19% performance gain.
He emphasized this is currently just a "single loop"—one Agent optimizing one codebase. Frontier labs have clusters of tens of thousands of GPUs and can run this kind of automated exploration at scale on smaller models, then extrapolate findings to larger models. He said all frontier labs are doing this.
Sarah asked if it could be recursed another level: When will models be able to write a better program.md than you?
Karpathy expanded on this with a framework. He said every research organization can be described by a set of Markdown files—roles, processes, connections.
> Every research organization is described by program.md. A research organization is a set of markdown files.
> ("Every research organization is described by program.md. A research organization is a set of markdown files.")
Different program.md files produce different research progress. One organization can have fewer morning meetings (because they're useless), another can take more risks. You can imagine having multiple "research organizations" compete, then analyze where improvements come from, and use that analysis to have the model generate a better program.md.
He said it's like layers of an onion: LLMs taken for granted → Agents taken for granted → Claw entities taken for granted → can have multiple → can have instructions → can optimize instructions. Each layer extends infinitely.
"That's why it gets to the point of psychosis—it's infinite, everything is a skill issue."
Genius PhD and 10-Year-Old—The Jaggedness of AI#
Sarah asked about the constraints of this autonomous looping.
Karpathy mentioned two important caveats.
First, this approach is extremely suitable for tasks with objectively measurable metrics. For example, writing more efficient CUDA kernels: you have inefficient code, want efficient code, behavior identical but faster—perfect fit. But many things can't be evaluated, so you can't do AutoResearch.
Second, the whole system currently "bursts at the seams." If you try to go too far, the overall value becomes negative.
He used an extremely precise analogy:
> I simultaneously feel like I'm talking to an extremely brilliant PhD student who's been a systems programmer for their entire life and a 10-year-old. It's so weird because humans don't come in that combination.
> ("I simultaneously feel like I'm talking to an extremely brilliant PhD student who's been a systems programmer for their entire life and a 10-year-old.")
Human abilities are more "coupled"—levels are roughly similar across aspects. But Agents have far greater jaggedness than humans. Sometimes you ask it to implement a feature, and what comes back is completely off, then you get stuck in an erroneous loop, which is maddening.

Sarah said what annoys her most is when an Agent wastes a lot of compute on an obvious problem.
Karpathy analyzed the reason: Models are trained via reinforcement learning (RL), so they can only improve on verifiable things—is the program correct? Do unit tests pass? But "softer" abilities, like understanding your intent, knowing when to ask for clarification, these aren't within RL's optimization scope.
You're either on the rails—in a super-intelligent circuit—or off the rails, outside the verifiable domain, and everything starts to drift.
He gave an intuitive example. Ask the most advanced ChatGPT to tell a joke. Do you know what joke you'll get?
Sarah laughed and said ChatGPT seems to have only three jokes.
Karpathy said the most common one is "Why don't scientists trust atoms? Because they make up everything"—this joke was the same three or four years ago, and it's still the same now. Models can now run for hours on Agent tasks, completing massive amounts of work, but their jokes are still the same as five years ago. Because jokes are outside the optimization scope of RL.
This challenges a popular hypothesis: getting stronger in verifiable domains (programming, math) leads to strength in all domains. Karpathy said he doesn't think this is happening, or it's happening a bit, but not to a satisfying degree.
Sarah pointed out this is actually similar to humans—you can be great at math but terrible at jokes. Karpathy agreed but said this means the mainstream narrative that "we get intelligence and capability for free in all domains" doesn't hold. Some domains are being optimized, some aren't,