初級
0から1へ:Claude Codeのようなエージェントを再現する
0から1へ:Claude Codeのようなエージェントを再現する
DBA運用エージェントの実践的な開発プロセスに基づき、ReAct論文の原理と組み合わせることで、Claude Codeのようなエージェントの動作の本質を理解し、独自の専門エージェントを構築する能力を身につけるためのガイドです。
なぜエージェントを理解する必要があるのか#
Claude Codeのようなツールを日常的に使用していると、まるで魔法のように感じられるかもしれません。問題を投げかけると、問題の特定、コードの修正、さらにはサーバー操作まで手伝ってくれます。しかし、その背後にある原理を理解していなければ、AIを実際のワークフローに統合することは困難です。
エージェントを理解することには、2つの重要な意義があります:
- 原理を理解して使用効率を向上させる:Claude Codeがどのように動作するかを知ることで、より効果的に協力し、何を委任し、何を自分で制御する必要があるかを理解できます。
- 独自のカスタマイズされた専門ツールを構築する:エージェントの本質を理解すれば、自社が提供するAPIやモデルに基づいて、ビジネスシナリオに特化したエージェント(例えば、MySQL運用エージェントや監視アラート分析エージェント)を完全に開発できます。
この記事の目標は次の通りです:最小限のMySQL運用エージェントを開発することで、Claude Codeのようなツールがどのように動作するかを徹底的に理解する。将来、Xiaolongxia/Claude code/kiroのようなエージェント/インテリジェンスを見たとき、まるで牛を解体するように、その内部構造を見通せるようになることです。
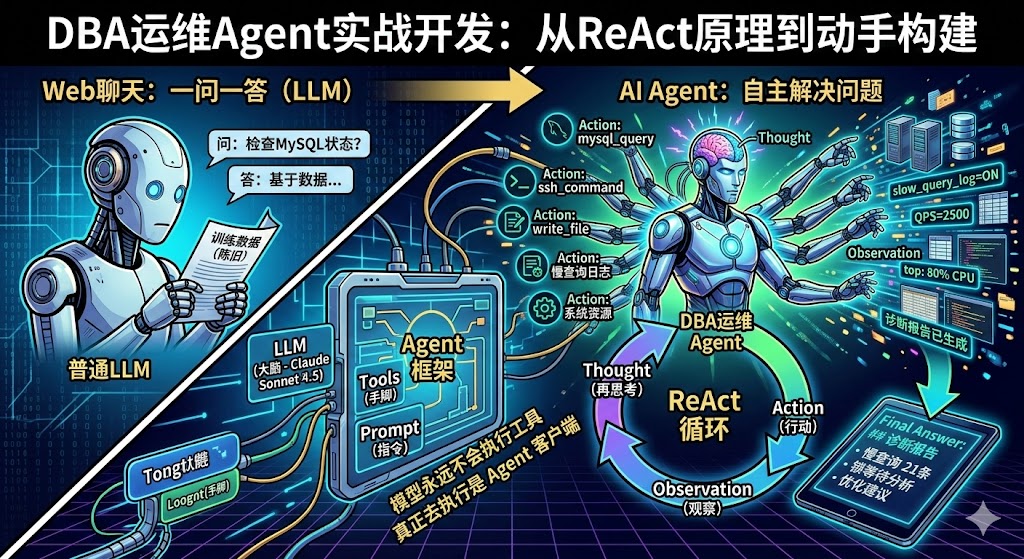
1. 「Q&A」から「自律的に問題を解決する」へ#
Webチャットとエージェントの本質的な違い#
以前、Webページで大規模言語モデルを使用していたとき、インタラクションはQ&A形式でした。質問を投げると、モデルは学習データに基づいて答えを吐き出し、それで終わりです。モデルはあなたのサーバー状態やデータベース設定を知らず、あなたのためにコマンドを実行することもできません。
Claude Codeのアプローチは全く異なります。質問を受け取った後、一連のツール(bashコマンドの実行、ファイルの読み書き、CPUチェックなど)を備え、大規模言語モデルと繰り返し対話します:
- あなたの質問とツールリストを大規模言語モデルに送信します。
- 大規模言語モデルが分析し、「
topコマンドを実行して」と言います。 - Claude Codeが
topを実行し、結果をフィードバックします。 - 大規模言語モデルが結果を見て、「ディスクもチェックして」と言います。
- 実行を続け、結果をフィードバックし続けます。
- 数十回繰り返し、大規模言語モデルが「十分な情報が得られた、これが最終的な結論だ」と言うまで続けます。
ユーザーにとっては、一文を入力して待つだけです。 しかし、その裏側では、エージェントはモデルと何十回もやり取りしているかもしれません。
なぜ2025年にAIが突然「強力」になったのか#
多くの人が、2025年後半以降、AIツールが突然非常に実用的になったと感じています。コードを書くのを手伝い、サービスをデプロイし、障害を特定してくれます。しかし、ここにはよくある誤解があります:モデル自体が大幅に強くなったわけではなく、エージェントの「クライアント」が強くなったのです。
以前のモデルは、学習データに基づいて質問に答えることしかできませんでした。現在のエージェントは、モデルに新しい情報(リアルタイムのシステム状態、データベースクエリ結果、ログ内容)を継続的に「供給」できます。モデルはもはや閉じた本での試験ではなく、「開いた本+本をめくって手伝ってくれるアシスタント」モードになったのです。
2. 必ず覚えておくべき2つの基本原理#
原理1:モデルには記憶がない#
これは非常に重要です。多くの記事で見たことがあるかもしれませんが、深く理解していない人も多いでしょう。
大規模言語モデルには、一切の記憶がありません。 同じアカウントであろうと、同じセッションであろうと、連続する2つの質問の間で、モデルは以前の内容を覚えたり関連付けたりしません。あなたが以前の内容を「覚えている」と思うのは、エージェントが一つのことを行っているからです:これまでのすべての会話履歴とツール実行結果を巨大なプロンプトにパッケージ化し、毎回完全にモデルに送信します。
そのため、各ラウンドのインタラクションで、エージェントがモデルに送信する内容はどんどん長くなります。最初のラウンドは1000語かもしれませんが、5ラウンド目は5000語、10ラウンド目は数万語になることもあります。これが、トークン消費が非常に速い理由です。
原理2:モデルは決してツールを実行しない#
大規模言語モデル自体は、一切ツールを実行しませんし、できません。モデルが行うことは一つだけです:あなたの質問と既存の情報に基づいて、エージェントにどのツールを呼び出すか、パラメータは何かを伝えることです。
実際にSSHコマンドを実行し、MySQLクエリを実行するのは、エージェントプログラム自体です。実行後、エージェントはこれらの返却結果(成功した場合もエラーの場合も)を理解せず、単に結果をそのままモデルに投げ戻し、モデルに次に何をするかを決定させます。
3. エージェントとは何か#
エージェント(知的エージェント)= モデルに継続的に考えさせ、外部ツールを呼び出し続け、ユーザーの問題を解決するまで続けるプログラムです。
Claude Code、OpenCodeなどはすべてエージェントです。これらは単なるクライアントツールであり、その背後には推論作業を完了させるための大規模言語モデルが必要です。
図で理解しましょう:
あなたのコード(エージェントフレームワーク)
┌──────────────────────────────────────────┐
│ │
ユーザー ─►│ ループ { │
│ 1. 問題+ツールリストをLLMに送信 │
│ 2. LLMが返信:XXツールを呼び出したい │
│ 3. エージェントがツールを実行、結果を取得 │
│ 4. 結果をLLMにフィードバック │
│ 5. LLMが判断:情報は十分か? │
│ - 不十分 → 1に戻る │
│ - 十分 → 最終回答を出力 │
│ } │
└──────────────────────────────────────────┘核心的な違い:
- 通常のLLM呼び出し:Q&A、モデルは学習データに基づいてのみ回答可能。
- エージェントモード:モデルはツールを積極的に呼び出してリアルタイム情報を取得し、複数ラウンドの推論後に回答を提供可能。
もう一つ注意すべき詳細があります:エージェントが起動するとき、すべてのツール定義(名前、目的、パラメータ説明)を一度にモデルに送信します。例えば、GitHub、MCP、bashなど数十のツールを設定した場合、あなたの問題がどのツールに関連しているかに関わらず、すべて含まれます。これが、Claude Codeを開いた瞬間にコンテキスト消費がすでに高い理由です。ツール定義だけで数万語を占めるからです。
4. ReAct:エージェントの核心的な動作モード#
ReAct(Reasoning + Acting)は、現在エージェントで最も主流の動作モードであり、2022年の論文 ReAct: Synergizing Reasoning and Acting in Language Models に由来します。
核心ループ#
┌─────────────────────────────────────────────────────┐
│ ReAct ループ │
│ │
│ 思考 ──► 行動 ──► 観察 ──► 思考 │
│ (Think) (Act) (Observe) (Think) │
│ │ │ │
│ └─────── 情報不十分、ループ ◄──────────┘ │
│ │
│ 情報十分 ──► 最終回答 │
└─────────────────────────────────────────────────────┘核心的な考え方は:大規模言語モデルはまず思考(Thought)し、現在どの情報が必要かを考え、次にエージェントが実行すべき行動(Action)を決定します。エージェントが実行し、観察結果(Observation)を返した後、モデルは新しい情報に基づいて思考を続けます。このループには、if-elseロジックを一切書く必要はありません。モデル自体が、どのツールを何回呼び出すか、いつ停止するかを決定します。
以前、自動化プログラムを書くときは、テンプレートマッチングと条件判断に依存し、さまざまなシナリオを網羅する必要があったため、面倒で頻繁な変更が必要でした。現在、エージェントはすべての判断ロジックをモデルに委ね、モデルが次に何をするかを決定します。
実際の実行例#
「MySQLマスタースレーブレプリケーション状態をチェックする」を例に、エージェントの実際の思考プロセスを見てみましょう:
[LLM #1]
思考:マスタースレーブ状態をチェックする必要がある。まずSHOW SLAVE STATUSを見る
行動:mysql_query
行動入力:{"query": "SHOW SLAVE STATUS"}
→ ツール返却:[結果セットなし](スレーブでないことを示す)
[LLM #2]
思考:スレーブではない。マスターかどうか確認する
行動:mysql_query
行動入力:{"query": "SHOW MASTER STATUS"}
→ ツール返却:mysql-bin.000007 | 180681919 | ... | GTID:1-1833162
[LLM #3]
思考:マスターだ。スレーブが接続されているか確認する
行動:mysql_query
行動入力:{"query": "SHOW SLAVE HOSTS"}
→ ツール返却:[結果セットなし](スレーブ接続なし)
[LLM #4]
思考:マスターは正常だがスレーブなし。セミ同期状態とエラーログを確認する
行動:ssh_command
行動入力:{"command": "tail -50 /data0/mysql_3306/log/error.log"}
...
[LLM #6]
思考:最終的な答えがわかった
最終回答:## 診断レポート ...このプロセスで、モデル自体が判断しました:まずスレーブ状態をチェック → スレーブでないことを発見 → マスター状態をチェックに切り替え → マスターであることを確認 → スレーブ接続をチェック → ログをチェック。このロジックを事前に設定する必要は一切ありません。モデルが各ステップの返却に基づいて決定します。
5. エージェント開発の三要素#
┌────────────────────────────────────────────┐
│ エージェント = LLM + ツール + プロンプト │
│ │
│ ┌─────────┐ ┌─────────┐ ┌───────────┐ │
│ │ LLM │ │ ツール │ │ プロンプト │ │
│ │ 大規模 │ │ セット │ │ 役割 │ │
│ │ モデル │ │ (手) │ │ 定義 │ │
│ │ (脳) │ │ │ │ (命令) │ │
│ └─────────┘ └─────────┘ └───────────┘ │
└────────────────────────────────────────────┘| 要素 | あなたが行うこと | プロジェクト例 |
| --- | --- | --- |
| LLM | モデルを選択、APIアドレスを設定 | APIゲートウェイ経由のClaude Sonnet 4.5 |
| ツール | モデルが呼び出すPython関数を書く | ssh_command / mysql_query / write_file |
| プロンプト | モデルに自分が誰で、何ができるかを伝える | 「あなたはDBAエキスパートで、読み取り専用診断...」 |
開発作業の80%はツールを書くことです。 LLMとプロンプトは通常すぐに決定されます。
6. ステップバイステップの開発プロセス#
ステップ1:シナリオを定義し、ツールの境界を定義する#
まず3つの質問に答えます:
- エージェントはどの問題を解決するか?MySQL/Linuxリモート読み取り専用診断。
- どのツールが必要か?SSHコマンド実行、MySQLクエリ、レポートファイル書き込み。
- セキュリティ境界は何か?読み取り専用、書き込み操作は実行不可。
シナリオ:DBA日常診断
├── SSHでコマンド実行が必要 → ssh_commandツール
├── MySQLクエリが必要 → mysql_queryツール
└── レポート保存が必要 → write_fileツールツールコード内のコメント(説明)は非常に重要です。モデルはこれらの説明に依存して、いつどのツールを呼び出すか、どのパラメータを渡すかを決定します。これらのコメントは人間が読むためではなく、モデルのためのものです。
安全性のために、ツールに許可リスト/ブロックリストを追加する必要もあります。例えば、MySQLツールは
SHOW、SELECTなどの読み取り専用操作のみを許可し、DROP、DELETE、TRUNCATEなどの危険なコマンドを禁止します。ステップ2:プロジェクト構造を設定する#
mkdir -p ~/q/agent/tools
touch ~/q/agent/{config.yaml,main.py,crew.py,requirements.txt}
touch ~/q/agent/tools/{__init__.py,ssh_tool.py,mysql_tool.py,write_file_tool.py}ステップ3:ツールを書く(核心的な作業量)#
各ツールはPythonクラスで、
BaseToolを継承し、_runメソッドを実装します:from crewai.tools import BaseTool
from pydantic import BaseModel, Field
class MySQLQueryInput(BaseModel):
query: str = Field(description="実行するSQLクエリ文")
class MySQLQueryTool(BaseTool):
name: str = "mysql_query"
description: str = "MySQL読み取り専用クエリを実行する..." # モデルはこれを使用してこのツールを使うタイミングを決定
args_schema: Type[BaseModel] = MySQLQueryInput
def _run(self, query):
# 1. セキュリティチェック(読み取り専用許可リスト)
# 2. クエリを実行
# 3. フォーマットされた結果(文字列)を返す
return "結果テキスト"ツール開発のポイント:
descriptionを明確に書く。モデルはこれに依存して呼び出すタイミングを決定します。_runはプレーンテキストを返す。モデルはテキストのみ処理できます。- 優れたセキュリティインターセプトを実装する。モデルは危険な操作を試みる可能性があります。
- タイムアウト