初級
6つのアーキテクチャパターン+品質60%向上:このオープンソースプロジェクトがハーネスエンジニアリングを概念からツールへ
6つのアーキテクチャパターン+品質60%向上:このオープンソースプロジェクトがハーネスエンジニアリングを概念からツールへ
先週、AnthropicとOpenAIによるハーネスエンジニアリングの異なる解釈について議論し、9人のブロガーによる強い支持から懐疑論までの様々な立場をまとめました。概念的な議論は活発でしたが、重要な疑問が残っていました。それを具体的に実装するにはどうすればよいのか? 今、誰かが答えを提供しました。
開発者のrevfactoryが、HarnessというClaude Codeプラグインを作成しました。これはハーネスエンジニアリングの概念を、インストールして実行可能なツールに直接変換します。あなたがやりたいことを伝えると、自動的に完全なエージェントチームアーキテクチャを生成します。エージェント定義ファイル、スキルファイル、コラボレーションプロトコル、テストケースを含み、これらはすべて
.claude/agents/と.claude/skills/ディレクトリに配置されます。このプロジェクトが何をするのか、詳しく見ていきましょう。
6つのアーキテクチャパターン:圧倒的多数のコラボレーションシナリオをカバー#

Harnessには、6つの組み込みエージェントチームコラボレーションパターンが用意されており、それぞれが典型的なタスクタイプに対応しています。
パイプラインは、依存関係が強い順次タスクに適しています。あるエージェントの出力が次のエージェントに直接渡されます。例えば、小説を書く場合:世界観の構築はキャラクターデザインの前に行う必要があり、キャラクター設定はプロット作成の前に行う必要があります。ボトルネックは明らかで、どのリンクが詰まってもライン全体が停止します。
ファンアウト/ファンインは、最も自然なマルチエージェントパターンです。複数の専門家が同じ入力を並行して分析し、最後に結果が集約されます。業界調査に特に役立ちます。あるエージェントは公式ドキュメントを確認し、別のエージェントはメディアレポートを確認し、さらに別のエージェントはコミュニティの議論を確認し、また別のエージェントは競合の背景を確認し、最後に包括的なレポートを合成します。
エキスパートプールは、ルーターを介して入力タイプに基づいて動的に対応する専門家にタスクを割り当てます。コードレビューは典型的なシナリオです。セキュリティの問題はセキュリティ専門家に、パフォーマンスの問題はパフォーマンス専門家に割り当てられます。全員が同時にオンラインである必要はありません。
プロデューサー-レビュアーは、Anthropicの記事の中心的な発見を直接反映しています。エージェントが自身の作業を評価することはほとんど無意味であり、独立した生成者とレビュアーに分割する必要があります。Harnessはこのパターンを製品化し、無限ループを防ぐために組み込みのリトライ制限(最大2〜3ラウンド)を備えています。
スーパーバイザーは、動的割り当ての点でファンアウトとは異なります。ファンアウトは事前にタスクを割り当てますが、スーパーバイザーは実行時に実際の状況に基づいて動的にスケジュールします。大規模なコード移行はこのパターンに適しています。スーパーバイザーはファイルリストを分析し、複雑さに応じて動的にファイルをバッチ処理して、異なる移行エージェントに割り当てます。
階層的委任は、特に複雑な問題を処理し、大きなタスクを再帰的に小さなタスクに分割して下位に委任します。2レベルに制限されています。それ以上深くなると、レイテンシとコンテキスト損失が発生します。
これらの6つのパターンは恣意的に選ばれたわけではありません。第2フェーズ(チームアーキテクチャ設計)では、Harnessは専門化レベル、並列化の可能性、コンテキスト範囲、再利用性の4つの次元に基づいて自動的に評価します。
5つの実世界のチーム設定例#

パターン定義だけでは不十分です。Harnessには5つの完全なチーム設定テンプレートが含まれています。
リサーチチームは、ファンアウト/ファンインパターンを使用し、4人の専門研究者と1人のコーディネーターで構成されます。公式ドキュメント研究者、メディア研究者、コミュニティ研究者、背景研究者が並行して作業し、矛盾する情報が見つかった場合には
SendMessageを使用して相互検証を行います。SF小説チームは、パイプラインとファンアウトを混合し、4つのフェーズにわたって6人のエージェントで構成されます。フェーズ1では、世界観デザイナー、キャラクターデザイナー、プロットアーキテクトが並行して作業し、互いに通信します。フェーズ2:ライターがテキストを起草します。フェーズ3:科学コンサルタントと一貫性チェッカーが並行してレビューします。フェーズ4:ライターが最終稿を修正します。最も興味深いのは、各フェーズのチームは使用後に破棄され、次のフェーズのために新しいチームが作成されることです。
ウェブトゥーン制作チームは、プロデューサー-レビュアーパターンを使用し、2人のエージェントのみで構成されます。アーティストがストーリーボードを生成し、レビュアーがPASS、FIX、REDOの3つの結果のいずれかを返します。完璧主義の無限ループを防ぐために、最大2回のリトライが強制され、その後は強制的にパスされます。
コードレビューチームは、ファンアウト/ファンインにピアディベートメカニズムを加えたものを使用します。セキュリティレビュアー、パフォーマンスレビュアー、テストレビュアーが並行して作業します。重要な点は、レビュアーが
SendMessageを直接使用して相互検証できることです。例えば、セキュリティレビュアーがSQLインジェクションのリスクを発見した場合、関連するクエリを確認するためにパフォーマンスレビュアーに直接通知します。コード移行チームは、スーパーバイザーパターンを使用し、1人のスーパーバイザーが動的にN人の移行実行エージェントをスケジュールします。スーパーバイザーは複雑さに応じてファイルをバッチ処理して割り当て、実行エージェントはタスクを要求して進捗を報告し、失敗したタスクは自動的に再割り当てされます。
A/Bテストデータ:品質60%向上、勝率100%#
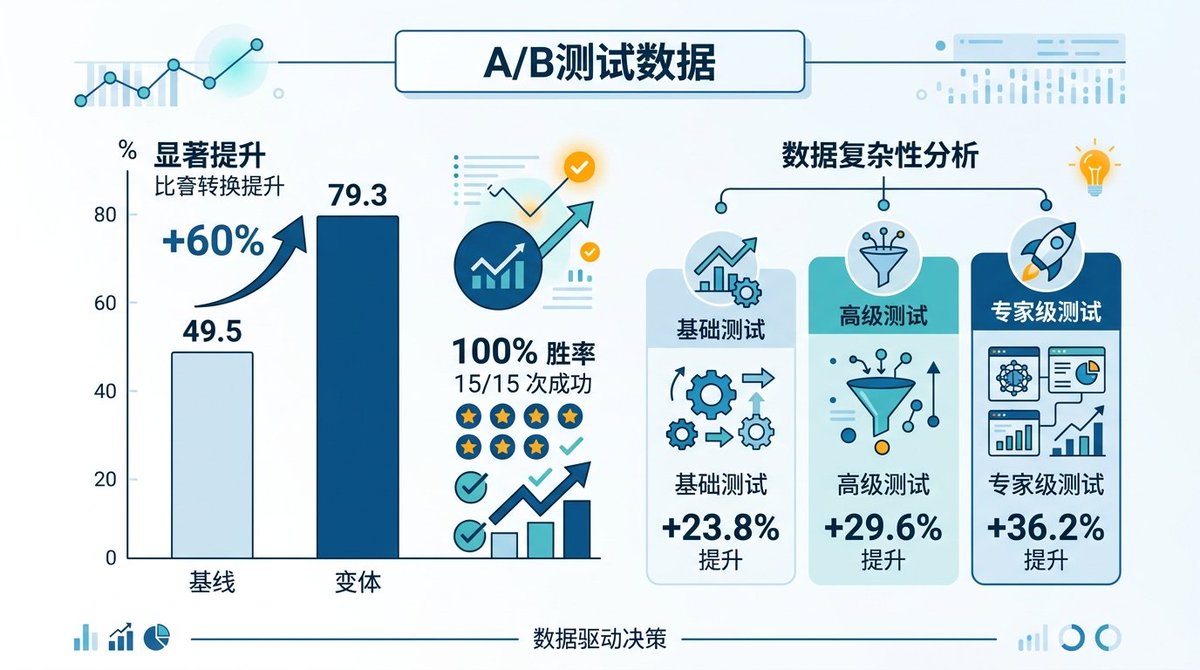
このプロジェクトで最も説得力があるのは、含まれている一連のA/Bテストデータです。
15のソフトウェアエンジニアリングタスクが、Harnessを使用した場合と使用しない場合の2つの方法で完了されました。結果:平均品質スコアが49.5から79.3に向上し、60%の改善となりました。Harnessは15のタスクすべてで勝利し、勝率100%でした。出力のばらつきは32%減少し、結果がより安定して予測可能であることを意味します。
さらに興味深いのは、タスクの複雑さによる内訳です。基本タスクは23.8%向上、中級タスクは29.6%向上、エキスパートレベルのタスクは36.2%向上しました。タスクが複雑になればなるほど、Harnessの価値は大きくなります。これはAnthropicの実験の結論と高度に一致しています。単一のエージェントは単純なことを処理できますが、複雑なタスクはハーネスなしでは基本的に不可能です。
プログレッシブディスクロージャー:スキルコンテキストの爆発を解決#
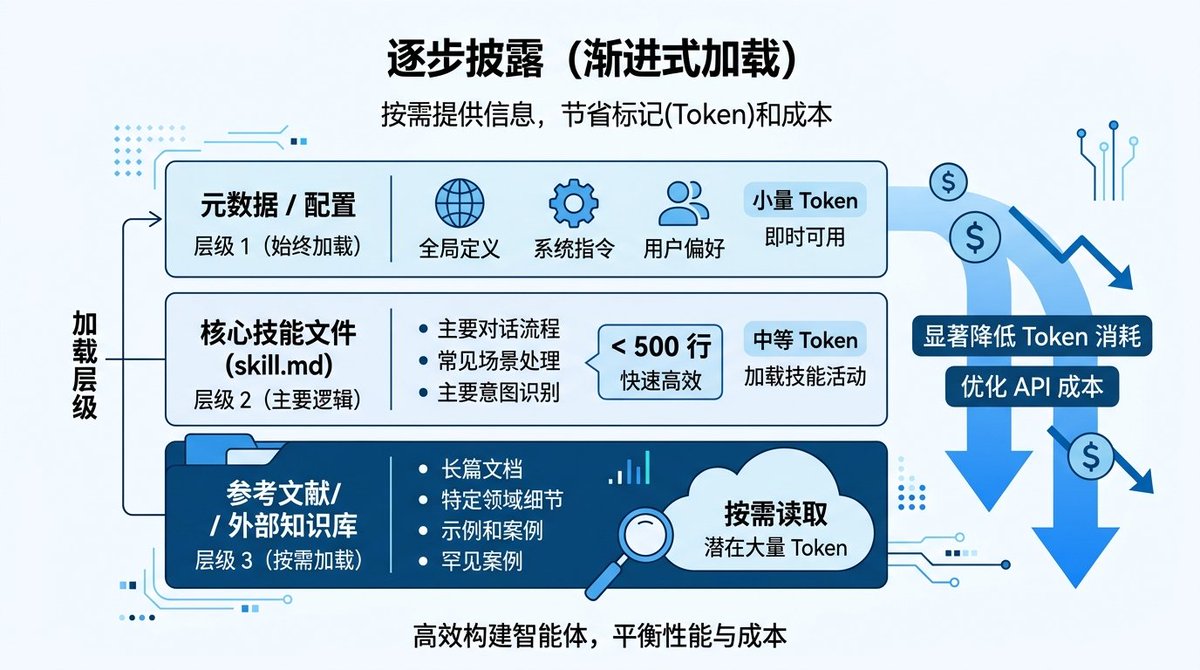
Harnessは、スキル生成にプログレッシブディスクロージャーと呼ばれる設計を使用しており、非常に実用的な問題を解決しています。スキルファイルが長すぎると、コンテキストウィンドウを大量に消費してしまうという問題です。
アプローチは3層構造です。メタデータ層は常にロードされ(名前、説明、トリガーワード)、メインの
skill.md本文は500行未満に保たれ、詳細な参考資料はreferences/ディレクトリに配置され、オンデマンドでロードされます。これにより、エージェントは通常、非常に少ないトークンを消費し、特定のドメインを深く掘り下げる必要がある場合にのみ、対応する参照ドキュメントをロードします。このアイデアは、Claude Codeスキルを作成するすべての人にとって価値があります。私たち自身の公開スキルはすでに600行を超えています。おそらく、トラブルシューティングとテンプレートの詳細を
referencesに移動することも検討すべきでしょう。コンセプトからツールへ:3つのシフト#

先に概観したパノラマを振り返ると、このプロジェクトはハーネスエンジニアリングを概念的な議論からツール化の段階へと前進させています。
第一のシフト: 「ハーネスを設計する必要がある」から「ハーネスを自動生成するのを支援する」へ。
AnthropicとOpenAIの記事は、基本的に「ハーネスは重要であり、しっかり設計すべきだ」と述べています。しかし、どのように設計するのか?どのようなパターンがあるのか?エージェントはどのように通信するのか?これらの疑問は読者自身が解決するために残されていました。Harnessプロジェクトは、選択と生成の両方を自動化します。要件を記述すれば、完全なアーキテクチャを出力します。
第二のシフト: 単一パターンからパターンライブラリへ。
以前の議論では、AnthropicはProducer-Reviewer(生成器+評価器)に焦点を当て、OpenAIはPipeline(階層型アーキテクチャ)に焦点を当てていました。しかし、実際のシナリオはこれら2つよりもはるかに多様です。6つのパターンを体系的にカバーすることで、単純なものから複雑なものまで、ほとんどのコラボレーションのニーズに対応します。
第三のシフト: 「私が良いと思う」から「データに語らせる」へ。
懐疑論者のChayenne Zhaoが正しかったのは、概念的な記事だけではハーネスエンジニアリングが実際に有用かどうかを判断するのが難しいということです。このプロジェクトは、15のタスクに対するA/Bテストにより定量的なエビデンスを提供します。60%の品質向上と100%の勝率は、概念ではなく数字です。
注目すべき設計の詳細#

見落とされがちないくつかの設計上の選択肢:
すべてのエージェント呼び出しは、
model: "opus" の指定を強制されます。エージェントチームのシナリオでは、推論の品質がコラボレーションの品質を直接決定します。弱いモデルを使用するとトークンは節約できますが、コラボレーションは容易に崩壊します。ファイルシステムをコラボレーション基盤として。 エージェント間の中間成果物は、
_workspace/ ディレクトリに統一して保存され、命名規則は {フェーズ}_{エージェント}_{成果物}.{拡張子} です。これは、コミュニティの議論でLeoが述べた点と完全に一致します。ファイルシステムは最も基本的なプリミティブであり、ファイルだけが永続性、セッションを超えたコラボレーション、マルチエージェントの共有状態を同時に解決できるからです。検証フレームワークは単なる形式的なものではない。 各スキルには、それをトリガーすべき8〜10のクエリと、トリガーすべきでない8〜10のクエリを作成する必要があり、特にニアミステストケースに重点が置かれています。このレベルの厳密さは、ほとんどのエージェントツールでは稀です。
チームサイズのハードリミット。 2〜7名のメンバーで、各メンバーは3〜6のタスクを持ちます。階層的な委任は2レベルに制限されています。これらの制約は実践から得られた教訓に基づいています。エージェントが多すぎると調整コストが指数関数的に増大し、階層が多すぎると深刻なコンテキスト損失が発生します。
制限事項と観察すべき点#

いくつかの制限事項も明確にしておく必要があります。
Agent Teams機能は、環境変数
CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 を手動で有効にする必要があり、この機能がClaude Code内ではまだ実験的であることを示しています。安定性とパフォーマンスは、より多くの実運用での使用を通じて検証する必要があります。A/Bテストの15タスクはすべてソフトウェアエンジニアリングのシナリオであり、他のドメイン(ライティング、リサーチ、デザイン)での有効性はデータで裏付けられていません。
6つのパターン間の選択に関するアドバイスは、依然として比較的粗い粒度です。実際には、混合使用が必要になる可能性が高いです。SF小説の例では、すでにPipelineとFan-outの両方が使用されていますが、このようなハイブリッドパターンのベストプラクティスはまだ模索中です。
しかし、ハーネスエンジニアリングをコンセプトからインストール可能なツールへと変えた最初のプロジェクトとして、方向性は正しいです。少なくとも、「ハーネスエンジニアリングは有用か?」という議論をやめ、「より良く使うにはどうすればよいか?」という研究を始めることができます。