初級
エージェント工学の8つのレベル [翻訳版]
エージェント工学の8つのレベル [翻訳版]
AIのプログラミング能力は、私たちがそれを活用する能力を上回る勢いで進化しています。だからこそ、SWE-benchのスコアを上げようとする慌ただしい努力のすべてが、エンジニアリングリーダーシップが実際に気にかける生産性指標には結びついていないのです。AnthropicチームはCoworkを10日でリリースしましたが、同じモデルを使っている別のチームはPOCすら立ち上げられません。その違いは、一方のチームが能力と実践のギャップを埋めたのに対し、もう一方は埋められなかったことにあります。
このギャップは一夜にして消えるものではありません。正確には、8つのレベルを経て埋まっていくのです。これを読んでいるほとんどの人は、最初の数レベルはすでに通過しているでしょう。そして、あなたは次のレベルに到達したいと切望しているはずです。なぜなら、レベルが上がるごとに出力が飛躍的に向上し、モデルの能力が向上するたびにその利益がさらに増幅されるからです。
もう一つ、あなたが気にかけるべき理由があります。それは「マルチプレイヤー効果」です。あなたの出力は、あなたが思っている以上にチームメイトのレベルに依存しています。例えば、あなたがレベル7の魔法使いで、バックグラウンドエージェントがあなたが寝ている間に複数のPRを提出しているとします。しかし、あなたのリポジトリがマージに同僚の承認を必要とし、その同僚がレベル2で手動でPRをレビューしている場合、あなたのスループットはボトルネックになります。つまり、チームメイトのレベルを上げることは、あなた自身の利益にもなるのです。
多くのチームや個人と、AIを活用したプログラミングの実践について話してきた中で、私が観察した進化の道筋は以下の通りです(順序は厳密に固定されているわけではありません)。
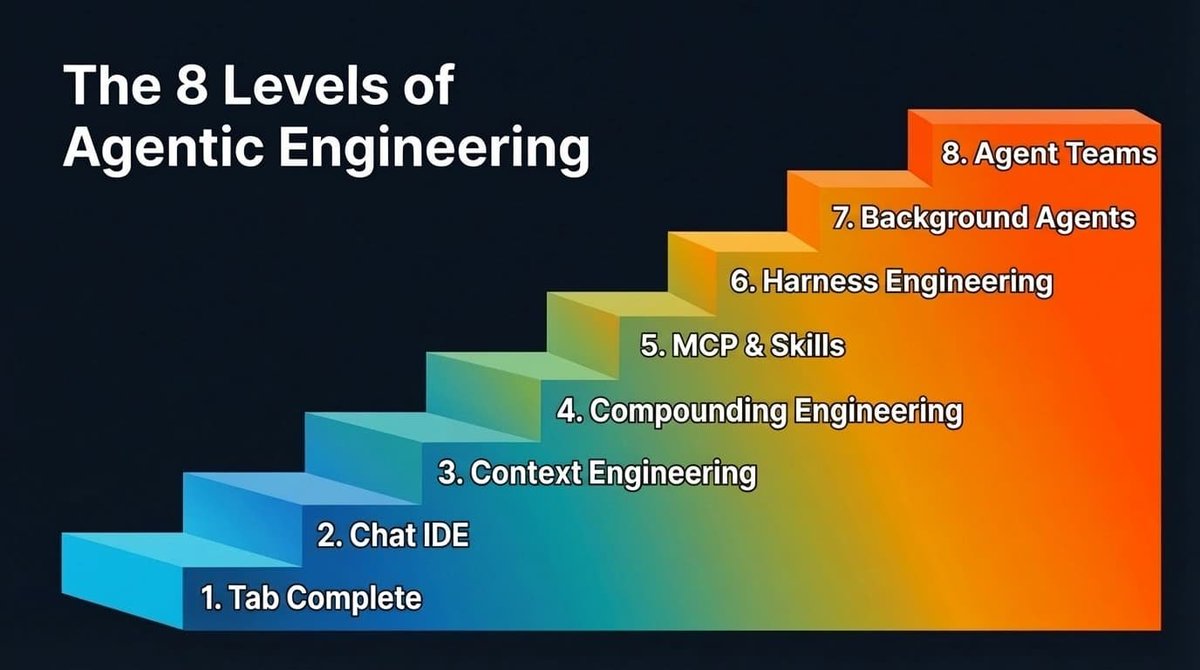
エージェント工学の8つのレベル
レベル1 & 2: タブ補完とエージェントIDE#
この2つのレベルについては、主に完全性のために手短に説明します。ざっと目を通す程度で構いません。
タブ補完は、すべてが始まった場所です。GitHub Copilotがこの動きを始めました。Tabを押すと、コードが得られます。多くの人はこの段階を忘れてしまったかもしれませんし、新参者は完全に飛ばしているかもしれません。これは、コードの骨組みを描き、AIに詳細を埋めさせることのできる経験豊富な開発者により適しています。
Cursorが牽引するAIネイティブIDEは、チャットをコードベースに接続することでゲームチェンジをもたらし、クロスファイル編集をはるかに容易にしました。しかし、常に限界となっていたのはコンテキストです。モデルは見えるものしか助けられず、適切なコンテキストが見えていないか、あるいは無関係なコンテキストが多すぎるというフラストレーションがありました。
このレベルのほとんどの人は、選択したプログラミングエージェントの「計画モード」も試しています。大まかなアイデアを構造化されたステップバイステップの計画に変え、その計画を繰り返し、実行をトリガーします。この段階ではうまく機能し、コントロールを維持するための合理的な方法です。しかし、後のレベルで見るように、計画モードへの依存は薄れていきます。
レベル3: コンテキストエンジニアリング#
ここからが面白い部分です。コンテキストエンジニアリングは2025年のバズワードでした。モデルが、適切なコンテキストだけで、合理的な数の指示を確実に従えるようになったために、重要なものとなりました。ノイズの多いコンテキストは、コンテキスト不足と同じくらい悪いため、核心となる作業はトークンあたりの情報密度を高めることです。「すべてのトークンはプロンプト内での居場所を勝ち取らなければならない」—これがマントラでした。
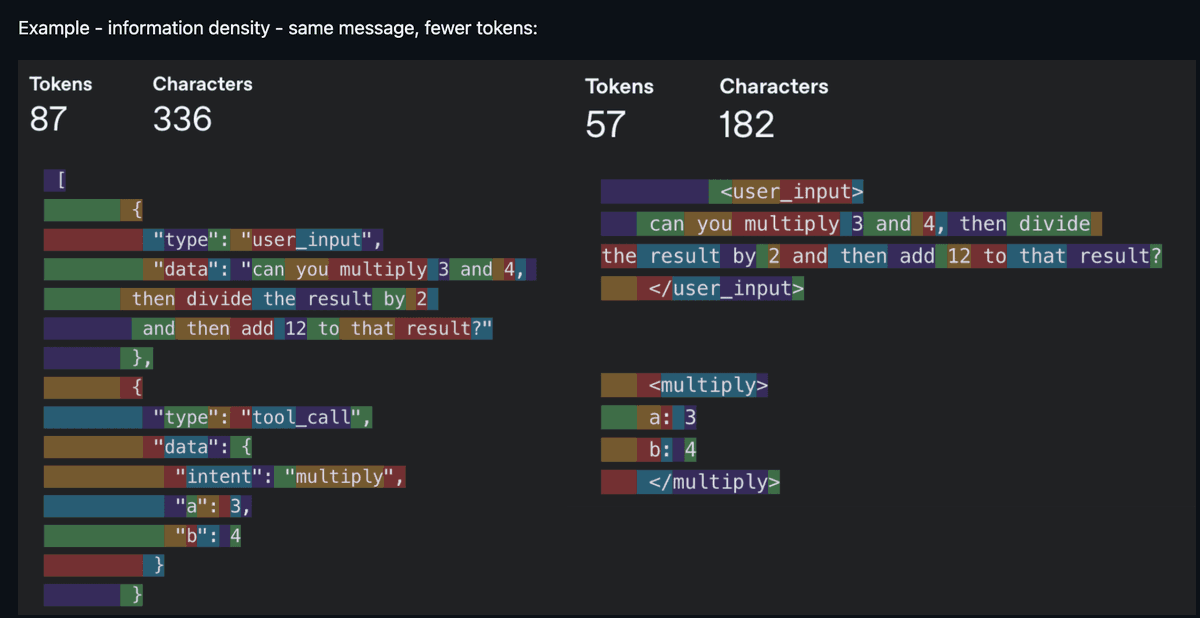
同じ情報、より少ないトークン—情報密度が王様 (出典: humanlayer/12-factor-agents)
実際には、コンテキストエンジニアリングはほとんどの人が認識しているよりも広範です。システムプロンプトやルールファイル (.cursorrules, CLAUDE.md) を含みます。ツールの記述方法も含まれます。なぜなら、モデルはどのツールを呼び出すかを決定するためにそれらの説明を読むからです。長期間実行されるエージェントが10ターン目以降に迷子にならないように、会話履歴を管理することも含まれます。また、各ターンでどのツールを公開するかを決定することも含まれます。なぜなら、選択肢が多すぎるとモデルは圧倒されてしまうからです—人間と同じように。
最近ではコンテキストエンジニアリングについてあまり聞かなくなりました。天秤は、よりノイズの多いコンテキストに耐え、より乱雑なシナリオでも推論できるモデル(より大きなコンテキストウィンドウも役立ちます)に傾いています。しかし、コンテキスト消費に注意を払うことは依然として重要です。いくつかのシナリオではボトルネックになります:
- 小さいモデルはコンテキストにより敏感です。 音声アプリケーションはしばしば小さいモデルを使用し、コンテキストサイズはファーストトークンレイテンシーとも相関し、応答速度に影響します。
- トークンの大食い。 Playwrightや画像入力のようなMCP (Model Context Protocol) は、すぐにトークンを消費し、Claude Codeで「圧縮セッション」に突入する時期を予想より早めます。
- 数十のツールを持つエージェント。 モデルが実際の作業よりもツール定義を解析するのに多くのトークンを費やしてしまう。
より広い教訓:コンテキストエンジニアリングは消えたのではなく、進化しているのです。焦点は、悪いコンテキストをフィルタリングすることから、適切なコンテキストが適切なタイミングで現れることを保証することに移りました。そして、このシフトがレベル4への道を開くのです。
レベル4: 複利エンジニアリング#
コンテキストエンジニアリングは「この」セッションを改善します。複利エンジニアリング (Kieran Klaassenによって造語) は「その後のすべての」セッションを改善します。この概念は、私や他の多くの人々にとって転換点でした。それは、「雰囲気でプログラミングすること」が単なるプロトタイピング以上のものであることに気づかせてくれました。
それは「計画、委任、評価、複利」のループです。タスクを計画し、LLMが成功するのに十分なコンテキストを与えます。委任します。出力を評価します。そして重要なステップ—学んだことを複利にします:何がうまくいったか、何が間違っていたか、次回に従うべきパターンは何か。
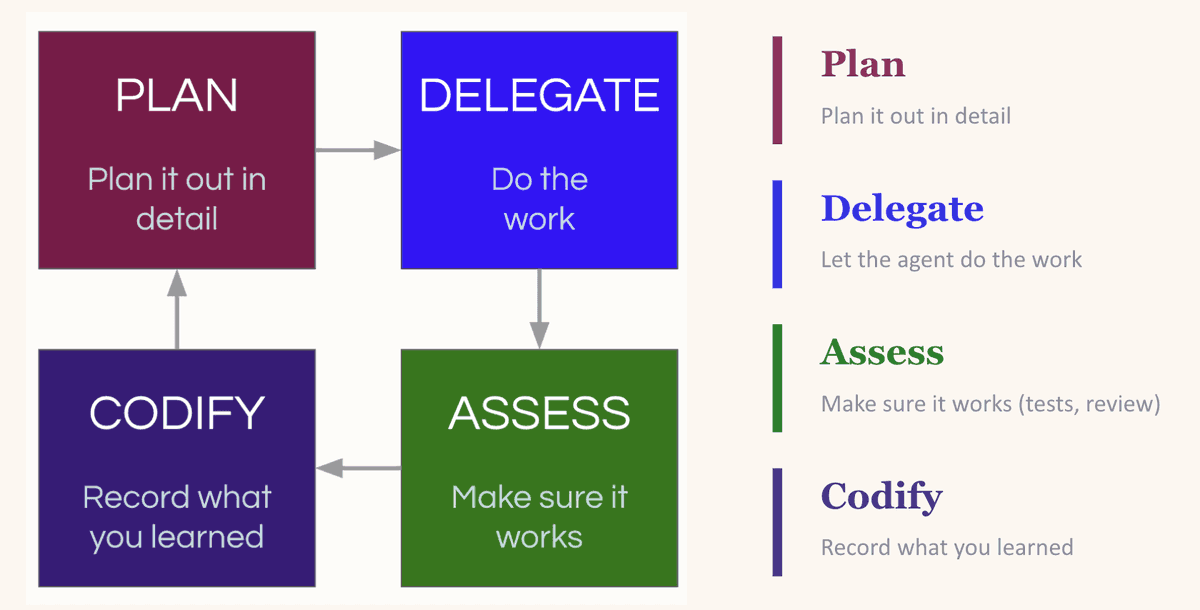
複利ループ: 計画、委任、評価、複利—各ラウンドが次をより良くする
魔法は「複利」ステップにあります。LLMはステートレスです。昨日明示的に削除した依存関係を再導入した場合、明日もまた同じことをします—それをしないように指示しない限り。最も一般的な修正は、CLAUDE.md(または同等のルールファイル)を更新し、学んだ教訓を将来のすべてのセッションに焼き付けることです。しかし注意:すべてをルールファイルにダンプしたい衝動は逆効果になる可能性があります(指示が多すぎることは無指示と同じです)。より良いアプローチは、LLMが有用なコンテキストを簡単に自分で発見できる環境を作ることです—最新の
docs/ フォルダを維持するなど(これについてはレベル7で詳しく説明します)。複利エンジニアリングを実践している人々は、通常、LLMに与えられるコンテキストに過敏です。LLMが間違いを犯したとき、彼らの直感は、まずモデルを責めるのではなく、何かがコンテキストから欠けていたのではないかと考えることです。この直感が、レベル5から8を可能にするのです。
レベル5: MCPとスキル#
レベル3と4はコンテキストを解決します。レベル5は能力を解決します。MCPとカスタムスキルは、あなたのLLMにデータベース、API、CIパイプライン、デザインシステム、ブラウザテスト用のPlaywright、通知用のSlackへのアクセスを与えます。モデルはもはやあなたのコードベースについて考えるだけではなく、直接それに対して操作できるようになります。
MCPとスキルが何であるかについては良い資料がたくさんあるので、ここでは繰り返しません。しかし、私の使用例からいくつか挙げます:私たちのチームは、全員が繰り返し改良してきた(そしてまだ改良中)PRレビュースキルを共有しています。それはPRの性質に基づいて条件付きでサブエージェントを起動します。1つはデータベース統合のセキュリティをチェックし、1つは冗長性や過剰設計にフラグを立てる複雑さ分析を行い、もう1つはプロンプトの健全性をチェックしてプロンプトがチームの標準フォーマットに従っていることを確認します。また、リンターやRuffも実行します。
なぜレビュースキルにこれほど投資するのか?エージェントが大量のPRを生成し始めると、人間のレビューが品質ゲートではなくボトルネックになるからです。Latent Spaceは説得力のあるケースを提示しました:私たちが知っているコードレビューは死んだ。その代わりに、自動化された、一貫性のある、スキル駆動のレビューがあるのです。
MCPの面では、Braintrust MCPを使用してLLMに評価ログをクエリさせ、直接編集を行わせています。DeepWiki MCPを使用して、エージェントがオープンソースリポジトリのドキュメントに、手動でコンテキストにドキュメントを取り込むことなくアクセスできるようにしています。
チーム内の複数の人が独立して類似のスキルを書き始めた場合、共有レジストリに統合する価値があります。Block(哀悼の意)は素晴らしい投稿をしました:彼らは100以上のスキルを持つ内部スキルマーケットプレイスを構築し、特定の役割やチーム向けにキュレーションされたスキルパッケージを作成しました。スキルはコードと同じ扱いを受けます:プルリクエスト、レビュー、バージョン履歴。
もう一つ注目すべきトレンド:LLMはMCPよりもCLIツールをますます使用するようになっています(そして、すべての会社が独自のものをリリースしているようです:Google Workspace CLI、Braintrustもまもなくリリース予定です)。その理由はトークン効率です。MCPサーバーは、エージェントがそれらを使用するかどうかに関わらず、すべてのターンで完全なツール定義をコンテキストに注入します。CLIは逆の方法で動作します:エージェントはターゲットを絞ったコマンドを実行し、関連する出力のみがコンテキストウィンドウに入ります。私はこの理由から、Playwright MCPの代わりにagent-browserを多用しています。
先に進む前に一呼吸。レベル3から5は、これに続くすべてのものの基礎です。LLMは、驚くほど得意なこともあれば、驚くほど苦手なこともあります。その境界線についての直感を養う必要があります。そうしないと、その上にさらに自動化を重ねることで問題が増幅されるだけです。コンテキストがノイズだらけで、プロンプトが不十分または不正確で、ツールの説明が曖昧であれば、レベル6から8はそれらの問題を増幅するだけです。
レベル6: ハーネスエンジニアリング#
ここからロケットが本当に飛び始めます。
コンテキストエンジニアリングは、モデルが「何を見るか」についてです。ハーネスエンジニアリングは、エージェントがあなたの介入なしに確実に作業できるようにする、ツール、インフラストラクチャ、フィードバックループを含む「環境全体」を構築することについてです。あなたはエージェントに単なるエディタではなく、完全なフィードバックループを与えます。
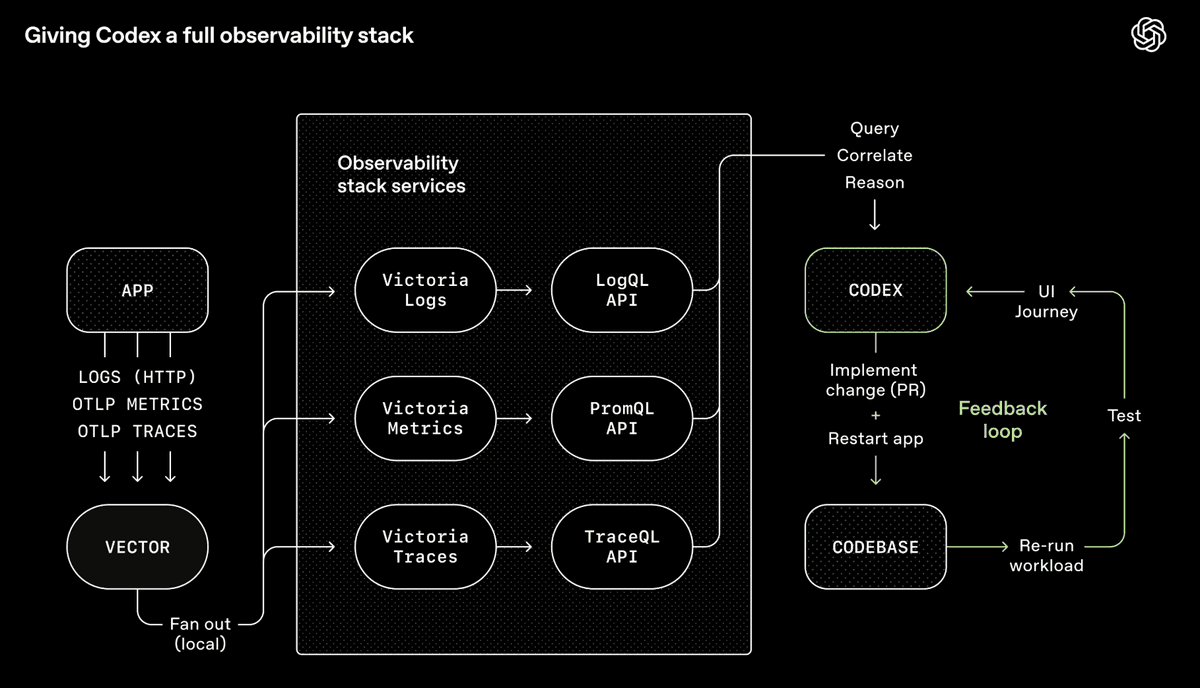
OpenAIのCodexツールチェーン—エージェントが自身の出力をクエリ、相関させ、推論することを可能にする完全なオブザーバビリティシステム (出典: OpenAI)
OpenAIのCodexチームは、Chrome DevTools、オブザーバビリティツール、ブラウザナビゲーションをエージェントランタイムに統合し、スクリーンショットを撮影し、UIフローを駆動し、ログをクエリし、自身の修正を検証できるようにしました。プロンプトを与えると、エージェントはバグを再現し、動画を記録し、修正を実装できます。その後、アプリを操作して検証し、PRを提出し、レビューフィードバックに対応し、マージします—判断を要する場合のみ人間にエスカレーションします。エージェントは単にコードを書いているのではなく、そのコードが何を生み出すかを「見て」、反復しているのです—人間と同じように。
私のチームは技術的トラブルシューティングのための音声およびチャットエージェントに取り組んでいるので、
converseというCLIツールを構築しました。これは、任意のLLMが私たちのバックエンドインターフェースとターンバイターンの会話をできるようにします。LLMがコードを変更した後、converseを使用してライブシステム上で会話をテストし、反復します。この自己改善ループが数時間実行されることもあります。これは、結果が検証可能な場合に特に強力です:会話は「必ず」このフローに従わなければならない、または特定の状況(人間へのエスカレーションなど)でこれらのツールを呼び出さなければならない。これらすべてを支える核心概念はバックプレッシャーです—エージェントが人間の介入なしに間違いを発見し修正することを可能にする自動化されたフィードバックメカニズム(型システム、テスト、リンター、pre-commitフック)です。自律性を望むなら、バックプレッシャーがなければなりません。そうでなければ、ゴミを生成するマシンができあがります。これはセキュリティにも拡張されます。VercelのCTOが指摘したように、エージェント、それが生成するコード、そしてあなたのキーは、異なる信頼ドメインにあるべきです。なぜなら、ログファイルに埋め込まれたプロンプトインジェクション攻撃が、エージェントを騙してあなたの認証情報を盗む可能性があるからです—すべてが同じセキュリティコンテキストを共有している場合。セキュリティ境界「は」バックプレッシャーです:それはエージェントが暴走した場合に「できること」だけでなく