初級
知られざるClaude Code:アーキテクチャ、ガバナンス、エンジニアリング実践
知られざるClaude Code:アーキテクチャ、ガバナンス、エンジニアリング実践
0. TL;DR#
この記事は、2つのアカウントで月額$40のサブスクリプションを支払い、数多くの落とし穴から学んだ6ヶ月間のClaude Code深層使用経験から生まれました。役に立つ洞察を提供できればと思います。
最初は私もChatBotとして使っていましたが、すぐに違和感を覚えました:コンテキストがどんどん乱雑になり、ツールは増えるのに効果は薄れ、ルールは長くなるのに守られなくなる。しばらく苦労し、Claude Code自体を研究した後、これはプロンプトの問題ではなく、システムがそう設計されているのだと気づきました。
この記事では、いくつかの点について議論したいと思います:Claude Codeの内部動作、コンテキストが乱雑になる理由とその管理方法、SkillsとHooksの設計方法、Subagentsの正しい使い方、Prompt Cachingのアーキテクチャへの影響、そして本当に役立つCLAUDE.mdの書き方です。
最も分かりやすい理解方法は、Claude Codeを6つのレイヤーに分解することだと思います:
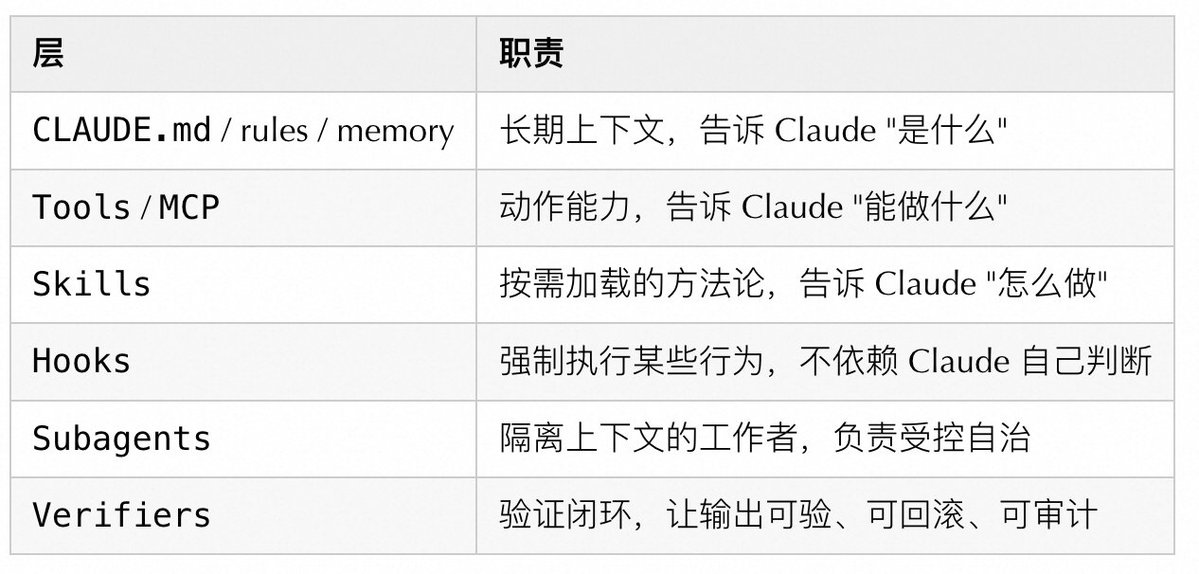
もし1つのレイヤーだけ強化すると、システムはバランスを崩します。CLAUDE.mdを長く書きすぎると、まずコンテキストが自己汚染します。ツールを積み上げすぎると、選択肢が不明確になります。Subagentを散らばせると、状態がドリフトします。検証ステップをスキップすると、何か問題が起きた時にどこで壊れたのか分からなくなります。
1. 内部動作の仕組み#

Claude Codeの核心は「回答」ではなく、繰り返し行われるエージェントプロセスです:
コンテキスト収集 → アクション実行 → 結果検証 → [完了または収集に戻る]
↑ ↓
CLAUDE.md Hooks / Permissions / Sandbox
Skills Tools / MCP
Memoryしばらく使ってみると、問題の原因がモデルの賢さ不足であることはほとんどなく、むしろ間違ったコンテキストを与えたか、何かを書いたが正しいか判断できず、ロールバックもできない場合が多いことに気づきました。
本当に注目すべき5つのレベル:#

これらの側面を見ると、多くの問題のトラブルシューティングが容易になります。結果が不安定?モデルではなく、コンテキストの読み込み順序を確認。自動化が制御不能?エージェントが積極的すぎるのではなく、制御レイヤーが設計されているか確認。長いセッションで品質劣化?中間出力がコンテキストを汚染。新しいセッションを開始する方が、プロンプトを繰り返し調整するよりも有用なことが多いです。
2. 概念の境界:MCP / Plugin / Tools / Skills / Hooks / Subagents#

簡単な覚え方:Claudeに新しい行動能力を与えるにはTool/MCPを使う。作業方法のセットを与えるにはSkillを使う。隔離された実行環境が必要な時はSubagentを使う。強制制約と監査にはHookを使う。プロジェクト横断的な配布にはPluginを使う。
3. コンテキストエンジニアリング:最も重要なシステム制約#
多くの人はコンテキストを「容量問題」として扱いますが、ボトルネックは通常、長さ不足ではなく、ノイズが多すぎることです。有用な情報が大量の無関係なコンテンツに埋もれてしまいます。
コンテキストの真のコスト構成#
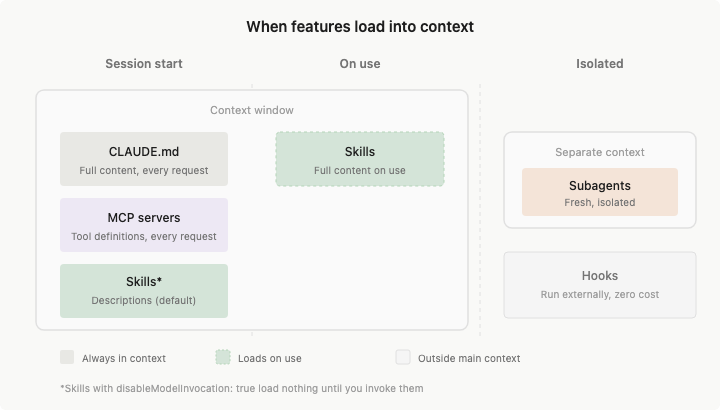
Claude Codeの200Kコンテキストは完全に使用可能ではありません:
200K 総コンテキスト
├── 固定オーバーヘッド (~15-20K)
│ ├── システム指示: ~2K
│ ├── 有効化された全Skill記述子: ~1-5K
│ ├── MCPサーバーツール定義: ~10-20K ← 最大の隠れた問題
│ └── LSP状態: ~2-5K
│
├── 準固定 (~5-10K)
│ ├── CLAUDE.md: ~2-5K
│ └── メモリ: ~1-2K
│
└── 動的に利用可能 (~160-180K)
├── 会話履歴
├── ファイルコンテンツ
└── ツール呼び出し結果
典型的なMCPサーバー(GitHubなど)には20-30のツール定義が含まれており、それぞれ約200トークン、合計4,000-6,000トークン。5つのサーバーを接続すると、この固定オーバーヘッドだけで25,000トークン(12.5%)に達します。この数字を初めて計算した時、これほど多いとは本当に予想していませんでした。大量のコードを読む必要があるシナリオでは、この12.5%は本当に重要です。
推奨されるコンテキスト階層化#
常駐 → CLAUDE.md: プロジェクト契約 / ビルドコマンド / 禁止事項
パスで読み込み → rules: 言語 / ディレクトリ / ファイルタイプ固有のルール
要求時に読み込み → Skills: ワークフロー / ドメイン知識
隔離して読み込み → Subagents: 重い探索 / 並列調査
コンテキストに読み込まない → Hooks: 決定論的スクリプト / 監査 / ブロック簡単に言えば、たまにしか使わないものを毎回読み込まないことです。
コンテキストのベストプラクティス#
- CLAUDE.mdは短く、厳格で、実行可能に保つ。コマンド、制約、アーキテクチャ境界を優先して書く。Anthropic自身の公式CLAUDE.mdは約2.5Kトークンしかなく、参考にできます。
- 大きな参照ドキュメントはSkillのサポートファイルに分割し、SKILL.md本体に詰め込まない。
- パス/言語ルールには
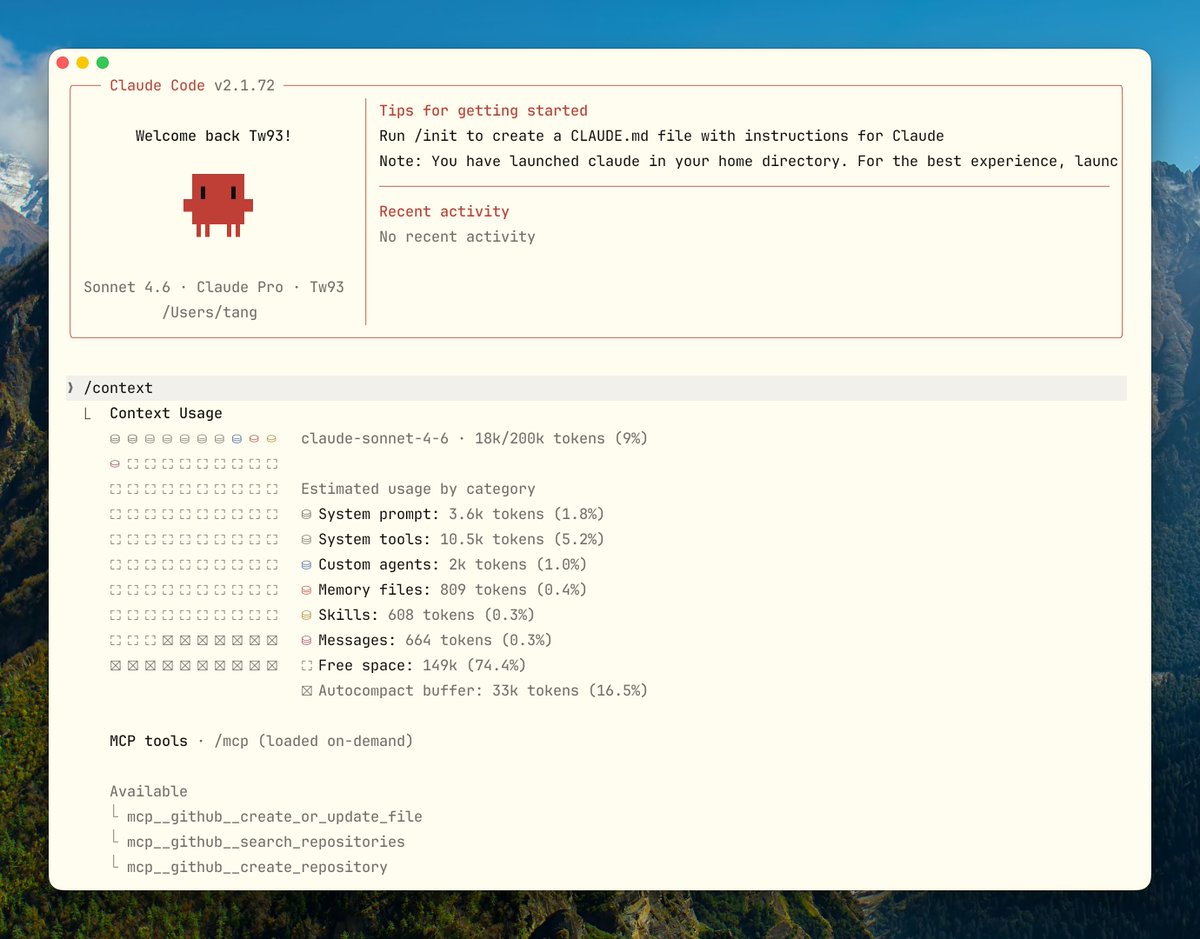
.claude/rules/を使用し、ルートのCLAUDE.mdにすべての違いを負わせない。 - 長いセッションでは
/contextを積極的に使用して消費状況を観察し、システムが自動圧縮するまで待たない。
- タスク切り替えには
/clearを優先し、同じタスクの新しいフェーズに入る時は/compactを使用。 - Compact InstructionsをCLAUDE.mdに書く。圧縮後に保持しなければならないものは、アルゴリズムが推測するのではなく、あなたが制御します。
ツール出力ノイズ:もう一つの隠れたコンテキストキラー#
先の計算はMCPツール定義の固定オーバーヘッドでしたが、動的部分にも見落としがちな落とし穴があります:ツール出力。完全な
cargo test出力は簡単に数千行になります。git log、find、grepも、少し大きいリポジトリでは画面を埋め尽くします。Claudeはこの出力すべてを見る必要はありませんが、コンテキストに現れる限り、実際のトークンを消費し、会話履歴やファイルコンテンツのスペースを圧迫します。後でRTK (Rust Token Killer)のアプローチを見て、これは正しいと思いました。それがすることは単純です:Claudeに到達する前にコマンド出力を自動的にフィルタリングし、意思決定に必要な核心情報のみを保持します。例えば
cargo test:
# Claudeが見る生の出力
running 262 tests
test auth::test_login ... ok
... (数千行)
# RTK後
✓ cargo test: 262 passed (1 suite, 0.08s)Claudeが本当に知る必要があるのは「合格か不合格か、そしてどこで失敗したか」です。それ以外はすべてノイズです。Hooksを介してコマンドを透過的に書き換え、Claude Codeには完全に見えません。
セクション6では
| head -30のような手動切り捨てについて言及します。RTKはまさにこれを行いますが、より広範なカバレッジで、すべてのコマンドに自分で追加する必要はありません。プロジェクトはGitHubでオープンソースされています。圧縮メカニズムの落とし穴#
デフォルトの圧縮アルゴリズムは「再読み込み可能性」で判断します。初期のツール出力やファイルコンテンツが優先的に削除され、アーキテクチャ決定や制約推論も一緒に捨てられることがよくあります。2時間後に何かを修正する必要が生じた時、2時間前に何が決定されたか覚えていないかもしれません。不可解なバグはしばしばここから発生します。
解決策はCLAUDE.mdに明示的に記述することです:
## 圧縮指示
圧縮時、優先順位で保持:
1. アーキテクチャ決定(要約しない)
2. 変更されたファイルとその主要な変更点
3. 現在の検証状態(合格/不合格)
4. 未完了のTODOとロールバックメモ
5. ツール出力(削除可、合格/不合格のみ保持)Compact Instructionsを書く以外に、より積極的なアプローチがあります:新しいセッションを開始する前に、ClaudeにHANDOFF.mdを書かせ、現在の進捗、試したこと、うまくいったこと、行き詰まったこと、次にやることを明確に述べさせます。次のClaudeインスタンスはこのファイルを読むだけで継続でき、圧縮アルゴリズムの要約品質に依存する必要がありません。
HANDOFF.mdに現在の進捗を明確に書く。何を試し、何がうまくいき、何がうまくいかなかったかを説明し、新鮮なコンテキストを持つ次のエージェントがこのファイルを読むだけでタスクを継続できるようにする。
書いた後、すぐにスキャンする。何か不足があれば、直接追加させる。その後、新しいセッションを開始し、HANDOFF.mdへのパスを送る。
プランモードのエンジニアリング的価値#

プランモードの核心は、探索と実行の分離です。探索フェーズではファイルに触れず、計画確認後にのみ実行が行われます。
- 探索フェーズは読み取り専用操作に集中。
- Claudeはまず目標と境界を明確にし、具体的な計画を提出。
- 計画確認後にのみ実行コストが発生。

複雑なリファクタリング、マイグレーション、クロスモジュール変更では、「急いでコードを生成する」よりもはるかに有用です。間違った仮定に基づいてどんどん道を外れる状況を大幅に減らします。Shift+Tabを2回押してプランモードに入ります。高度なテクニックは、1つのClaudeに計画を書かせ、別のCodexに「シニアエンジニア」としてレビューさせることで、AIにAIをレビューさせるとうまくいきます。
4. Skills設計:テンプレートライブラリではなく、必要時に読み込まれるワークフロー#
Skillの公式説明は「要求時に読み込まれる知識とワークフロー」です。記述子はコンテキストに常駐し、完全な内容は要求時に読み込まれます。使用感は「保存されたプロンプト」とはかなり異なります。
良いSkillが満たすべき条件#
- 説明はモデルに「いつ私を使うか」を知らせるべきで、「私が何をするか」ではありません。これらは非常に異なります。
- 完全なステップ、入力、出力、停止条件を持つ。始めだけ書いて終わりがないのはダメ。
- 本体にはナビゲーションと核心制約のみを含める。大きな資料はサポートファイルに分割。
- 副作用のあるSkillは明示的に
disable-model-invocation: trueを設定する。そうしないと、Claudeが実行するかどうかを決定します。
Skillsが要求時読み込みを実現する方法#
Claude Codeチームは内部設計で「段階的開示」を繰り返し強調しています。アイデアは、モデルにすべての情報を一度に見せるのではなく、まずインデックスとナビゲーションを取得し、必要に応じて詳細を引き出すことです。
- SKILL.mdはタスクの意味論、境界、実行スケルトンを定義する責任を持つ。
- サポートファイルはドメイン詳細を提供する責任を持つ。
- スクリプトは決定論的にコンテキストや証拠を収集する責任を持つ。
比較的安定した構造は次のようになります:
.claude/skills/
└── incident-triage/
├── SKILL.md
├── runbook.md
├── examples.md
└── scripts/
└── collect-context.sh3つの典型的なSkillタイプ#
以下の例は、オープンソースターミナルプロジェクトKakuで実際に使用したSkillsからで、非常に直感的です。
タイプ1:チェックリスト型(品質ゲート)
リリース前に実行し、何も見落とさないことを確認:
---
name: release-check
description: リリースカット前に使用し、ビルド、バージョン、スモークテストを検証。
---
## 事前確認(すべて合格必須)
- [ ] `cargo build --release` 合格
- [ ] `cargo clippy -- -D warnings` クリーン
- [ ] Cargo.tomlでバージョン更新
- [ ] CHANGELOG更新
- [ ] クリーン環境で`kaku doctor`合格
## 出力
項目ごとの合格/不合格。不合格はリリース前に修正必須。タイプ2:ワークフロー型(標準化された操作)
設定マイグレーションは高リスク。明示的呼び出し+組み込みロールバックステップを使用:
---
name: config-migration
description: 設定スキーマをマイグレート。明示的に要求された時のみ実行。
disable-model-invocation: true
---
## ステップ
1. バックアップ: `cp ~/.config/kaku/config.toml ~/.config/kaku/config.toml.bak`
2. ドライラン: `kaku config migrate --dry-run`
3. 適用: 出力確認後`--dry-run`を削除
4. 検証: `kaku doctor`すべて合格
## ロールバック
`cp ~/.config/kaku/config.toml.bak ~/.config/kaku/config.toml`タイプ3:ドメインエキスパート型(意思決定フレームワークのカプセル化)
ランタイム問題発生時、Claudeに推測で動かず、固定パスで証拠を収集させる:
---
name: runtime-diagnosis
description: kakuがクラッシュ、ハング、またはランタイムで予期せぬ動作をする時に使用。
---
## 証拠収集
1. `kaku doctor`実行し、完全な出力をキャプチャ
2. `~/.local/share/kaku/logs/`の最後50行
3. プラグイン状態: `kaku --list-plugins`
## 意思決定マトリックス
| 症状 | 最初のチェック |
|---|---