초급
0에서 1까지: Claude Code 같은 에이전트 복제하기
0에서 1까지: Claude Code 같은 에이전트 복제하기
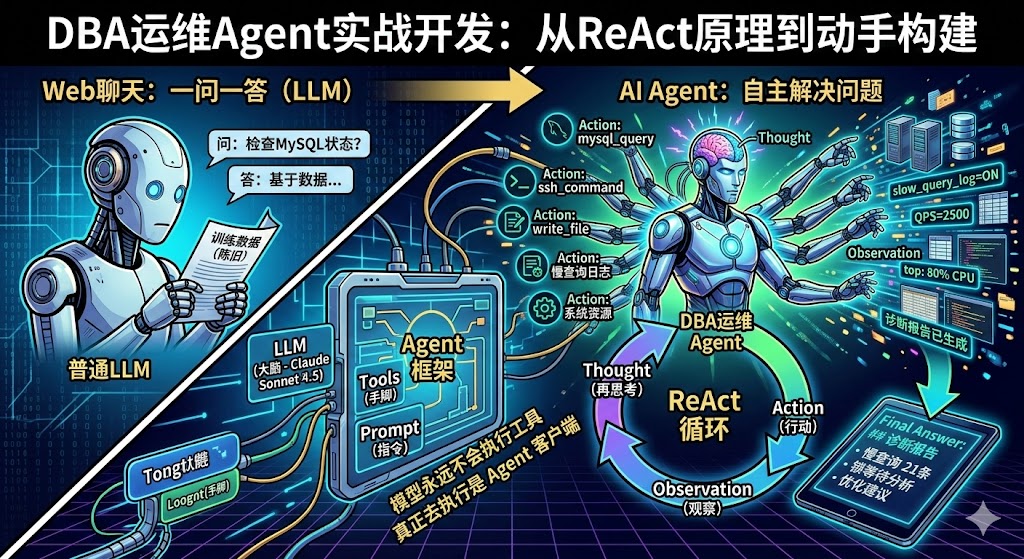
DBA 운영 에이전트의 실제 개발 과정을 바탕으로 ReAct 논문의 원리를 결합하여, Claude Code 같은 에이전트의 작동 본질을 이해하고 자신만의 전문 에이전트를 구축하는 능력을 갖추도록 돕는 가이드입니다.
에이전트를 이해해야 하는 이유#
Claude Code 같은 도구를 일상적으로 사용할 때, 마법처럼 느껴질 수 있습니다. 문제를 던지면 문제를 찾아내고, 코드를 수정하거나 심지어 서버를 운영하는 데 도움을 줍니다. 그러나 기본 원리를 이해하지 못하면 AI를 실제 워크플로우에 통합하기 어렵습니다.
에이전트를 이해하는 데는 두 가지 수준의 의미가 있습니다:
- 원리를 이해하여 사용 효율성 향상: Claude Code가 어떻게 작동하는지 알면 더 잘 협업할 수 있으며, 무엇을 위임하고 무엇을 직접 제어해야 하는지 이해할 수 있습니다.
- 자신만의 맞춤형 전문 도구 구축: 에이전트의 본질을 이해하면 회사가 제공하는 API와 모델을 기반으로 자신의 비즈니스 시나리오에 특화된 에이전트를 완전히 개발할 수 있습니다. 예를 들어 MySQL 운영 에이전트나 모니터링 경고 분석 에이전트가 될 수 있습니다.
이 글의 목표는: 최소한의 MySQL 운영 에이전트를 개발함으로써 Claude Code 같은 도구가 어떻게 작동하는지 철저히 이해하는 것입니다. 앞으로 Xiaolongxia/Claude code/kiro 같은 에이전트/지능을 보면 마치 도살장에서 소를 해부하는 것처럼 속속들이 꿰뚫어 볼 수 있을 것입니다.
1. "질의응답"에서 "자율적 문제 해결"로#
웹 채팅과 에이전트의 본질적 차이#
이전에는 웹 페이지에서 대형 모델을 사용할 때 상호작용이 질의응답이었습니다: 질문을 던지면 모델이 학습 데이터를 기반으로 답변을 내뱉고, 그게 전부였습니다. 모델은 서버 상태나 데이터베이스 구성을 알지 못하며, 사용자를 대신해 어떤 명령도 실행할 수 없었습니다.
Claude Code의 접근 방식은 완전히 다릅니다. 질문을 받은 후, 도구 세트(bash 명령 실행, 파일 읽기/쓰기, CPU 확인 등)를 갖추고 대형 모델과 반복적으로 상호작용합니다:
- 사용자의 질문 + 도구 목록을 대형 모델에 전송합니다.
- 대형 모델이 분석하여 말합니다: "
top명령을 실행해 주세요." - Claude Code가
top을 실행하고 결과를 다시 전달합니다. - 대형 모델이 결과를 보고 말합니다: "디스크를 다시 확인해 주세요."
- 계속 실행하고, 계속 결과를 전달합니다.
- 수십 번 반복하여 대형 모델이 말할 때까지 진행합니다: "충분한 정보입니다, 최종 결론은 다음과 같습니다."
사용자에게는 한 문장만 입력하고 기다리면 됩니다. 그러나 배후에서는 에이전트가 이미 모델과 수십 번 왕복하며 실행했을 수 있습니다.
2025년에 AI가 갑자기 "강력해진" 이유#
많은 사람들이 2025년 하반기부터 AI 도구가 갑자기 매우 실용적이게 느껴진다고 합니다. 코드 작성, 서비스 배포, 장애 위치 파악을 도와줍니다. 그러나 여기에는 흔한 오해가 있습니다: 모델 자체가 훨씬 강력해진 것이 아니라, 에이전트 "클라이언트"가 강력해진 것입니다.
이전 모델은 학습 데이터를 기반으로만 질문에 답할 수 있었습니다. 이제 에이전트는 모델에 지속적으로 새로운 정보를 "공급"할 수 있습니다. 실시간 시스템 상태, 데이터베이스 쿼리 결과, 로그 내용 등이죠. 모델은 더 이상 폐쇄형 시험이 아니라 "오픈북 + 책을 넘겨주는 조교" 모드가 된 것입니다.
2. 반드시 기억해야 할 두 가지 기본 원리#
원리 1: 모델은 기억이 없습니다#
이것은 매우 중요합니다. 많은 사람들이 다양한 글에서 보았을 수 있지만, 깊이 이해하지 못할 수 있습니다.
대형 모델은 전혀 기억이 없습니다. 동일한 계정이든, 동일한 세션이든, 연속된 두 질문 사이에서 모델은 이전 내용을 기억하거나 연관시키지 않습니다. 사용자가 이전 내용을 "기억한다"고 생각하는 이유는 에이전트가 한 가지 일을 해주기 때문입니다: 이전의 모든 대화 기록과 도구 실행 결과를 거대한 프롬프트로 묶어 매번 모델에 완전히 전송합니다.
따라서 각 상호작용 라운드마다 에이전트가 모델에 보내는 내용이 점점 길어지는 것을 볼 수 있습니다. 첫 번째 라운드는 1000단어일 수 있고, 다섯 번째 라운드는 5000단어, 열 번째 라운드는 수만 단어가 될 수 있습니다. 이것이 토큰 소비가 매우 빠른 이유입니다.
원리 2: 모델은 도구를 절대 실행하지 않습니다#
대형 모델 자체는 하지 않으며 할 수도 없습니다 어떤 도구도 실행하지 않습니다. 단 한 가지 일만 합니다: 사용자의 질문과 기존 정보를 기반으로 에이전트에게 어떤 도구를 호출하고 매개변수가 무엇인지 알려줍니다.
에이전트 프로그램 자체가 실제로 SSH 명령을 실행하고 MySQL 쿼리를 실행하는 것입니다. 실행 후 에이전트는 이러한 반환 결과를 이해하지 못합니다(성공일 수도 있고 오류일 수도 있음). 단순히 결과를 모델에 그대로 다시 던져주고, 모델이 다음에 무엇을 할지 결정하게 합니다.
3. 에이전트란 무엇인가#
에이전트(지능형 에이전트) = 모델이 지속적으로 생각하고, 지속적으로 외부 도구를 호출하여 사용자의 문제를 해결할 때까지 진행하는 프로그램입니다.
Claude Code, OpenCode, 이들은 모두 에이전트입니다. 단지 클라이언트 도구일 뿐이며, 배후에는 추론 작업을 완료하기 위한 대형 모델이 필요합니다.
다이어그램으로 이해해 보세요:
사용자 코드 (에이전트 프레임워크)
┌──────────────────────────────────────────┐
│ │
사용자 ─►│ 반복 { │
│ 1. 문제 + 도구 목록을 LLM에 전송 │
│ 2. LLM 반환: XX 도구를 호출하고 싶음 │
│ 3. 에이전트가 도구 실행, 결과 획득 │
│ 4. 결과를 LLM에 다시 전달 │
│ 5. LLM 판단: 정보가 충분한가? │
│ - 충분하지 않음 → 1로 돌아감 │
│ - 충분함 → 최종 답변 출력 │
│ } │
└──────────────────────────────────────────┘핵심 차이점:
- 일반 LLM 호출: 질의응답, 모델은 학습 데이터를 기반으로만 답변할 수 있습니다.
- 에이전트 모드: 모델이 도구를 능동적으로 호출하여 실시간 정보를 얻고, 여러 라운드의 추론 후 답변을 제공할 수 있습니다.
또 다른 주목할 만한 세부 사항이 있습니다: 에이전트가 시작될 때 모든 도구 정의(이름, 목적, 매개변수 설명)를 한 번에 모델에 전송합니다. 예를 들어 GitHub, MCP, bash 등 수십 개의 도구를 구성하면, 문제가 어떤 도구와 관련이 있는지 여부와 관계없이 모두 포함됩니다. 이것이 Claude Code를 열자마자 컨텍스트 소비가 이미 높은 이유입니다. 도구 정의만으로도 수만 단어를 차지하기 때문입니다.
4. ReAct: 에이전트의 핵심 작동 모드#
ReAct(Reasoning + Acting)는 2022년 논문 *ReAct: Synergizing Reasoning and Acting in Language Models*에서 제안된, 현재 가장 주류인 에이전트의 작동 모드입니다.
핵심 루프#
┌─────────────────────────────────────────────────────┐
│ ReAct Loop │
│ │
│ Thought ──► Action ──► Observation ──► Thought │
│ (Think) (Act) (Observe) (Think) │
│ │ │ │
│ └─────── Not enough info, loop ◄──────┘ │
│ │
│ Enough info ──► Final Answer │
└─────────────────────────────────────────────────────┘핵심 아이디어는 다음과 같습니다: 대규모 언어 모델은 먼저 현재 필요한 정보가 무엇인지 **생각(Thought)**하고, 그 다음 에이전트가 실행할 **행동(Action)**을 결정합니다. 에이전트가 실행하고 **관찰 결과(Observation)**를 반환한 후, 모델은 새로운 정보를 바탕으로 계속해서 생각합니다. 이 루프는 어떤
if-else 로직도 작성할 필요가 없습니다—모델 자체가 어떤 도구를 호출할지, 몇 번 호출할지, 언제 멈출지를 결정합니다.이전에 자동화 프로그램을 작성할 때는 템플릿 매칭과 조건부 판단에 의존하여 다양한 시나리오를 모두 고려해야 했기 때문에 번거롭고 자주 변경이 필요했습니다. 이제 에이전트는 모든 판단 로직을 모델에 넘기고, 모델이 다음에 무엇을 할지 결정합니다.
실제 실행 예시#
"MySQL 마스터-슬레이브 복제 상태 확인"을 예로 들어, 에이전트의 실제 사고 과정은 다음과 같습니다.
[LLM #1]
Thought: 마스터-슬레이브 상태를 확인해야 하므로, 먼저 SHOW SLAVE STATUS를 봅니다.
Action: mysql_query
Action Input: {{"query": "SHOW SLAVE STATUS"}}
→ Tool returns: [No result set] (슬레이브가 아님을 나타냄)
[LLM #2]
Thought: 슬레이브가 아니므로, 마스터인지 확인합니다.
Action: mysql_query
Action Input: {{"query": "SHOW MASTER STATUS"}}
→ Tool returns: mysql-bin.000007 | 180681919 | ... | GTID:1-1833162
[LLM #3]
Thought: 마스터입니다. 연결된 슬레이브가 있는지 확인합니다.
Action: mysql_query
Action Input: {{"query": "SHOW SLAVE HOSTS"}}
→ Tool returns: [No result set] (슬레이브 연결 없음)
[LLM #4]
Thought: 마스터는 정상이지만 슬레이브가 없으므로, 세미싱크 상태와 에러 로그를 확인합니다.
Action: ssh_command
Action Input: {{"command": "tail -50 /data0/mysql_3306/log/error.log"}}
...
[LLM #6]
Thought: 이제 최종 답변을 알았습니다.
Final Answer: ## 진단 보고서 ...이 과정에서 모델 자체가 판단했습니다: 먼저 슬레이브 상태 확인 → 슬레이브가 아님을 발견 → 마스터 상태 확인으로 전환 → 마스터임을 확인 → 슬레이브 연결 확인 → 로그 확인. 이 로직을 사전에 설정할 필요가 전혀 없습니다. 모델이 각 단계의 반환 결과를 바탕으로 결정을 내립니다.
5. 에이전트 개발의 세 가지 요소#
┌────────────────────────────────────────────┐
│ Agent = LLM + Tools + Prompt │
│ │
│ ┌─────────┐ ┌─────────┐ ┌───────────┐ │
│ │ LLM │ │ Tools │ │ Prompt │ │
│ │ Large │ │ Tool │ │ Role │ │
│ │ Model │ │ Set │ │ Definition│ │
│ │ (Brain)│ │ (Hands) │ │ (Command) │ │
│ └─────────┘ └─────────┘ └───────────┘ │
└────────────────────────────────────────────┘| 요소 | 해야 할 일 | 프로젝트 예시 |
| --- | --- | --- |
| LLM | 모델 선택, API 주소 구성 | API Gateway를 통한 Claude Sonnet 4.5 |
| Tools | 모델이 호출할 Python 함수 작성 |
ssh_command / mysql_query / write_file |
| Prompt | 모델에게 자신이 누구인지, 무엇을 할 수 있는지 알려주기 | "당신은 DBA 전문가이며, 읽기 전용 진단을 수행합니다..." |개발 작업의 80%는 Tools 작성입니다. LLM과 Prompt는 보통 빠르게 결정됩니다.
6. 단계별 개발 과정#
1단계: 시나리오 정의, 도구 경계 정의#
먼저 세 가지 질문에 답하세요:
- 에이전트가 해결할 문제는 무엇인가요?MySQL/Linux 원격 읽기 전용 진단.
- 어떤 도구가 필요한가요?SSH 명령어 실행, MySQL 쿼리, 보고서 파일 작성.
- 보안 경계는 무엇인가요?읽기 전용, 쓰기 작업 수행 불가.
Scenario: DBA 일상 진단
├── SSH로 명령어 실행 필요 → ssh_command 도구
├── MySQL 쿼리 필요 → mysql_query 도구
└── 보고서 저장 필요 → write_file 도구도구 코드의 주석(설명)은 매우 중요합니다—모델은 이 설명에 의존하여 언제 어떤 도구를 호출하고 어떤 매개변수를 전달할지 결정합니다. 이 주석은 사람이 읽기 위한 것이 아니라 모델을 위한 것입니다.
안전을 위해 도구에 허용 목록/차단 목록을 추가해야 합니다. 예를 들어, MySQL 도구는
SHOW, SELECT와 같은 읽기 전용 작업만 허용하고, DROP, DELETE, TRUNCATE와 같은 위험한 명령은 금지합니다.2단계: 프로젝트 구조 설정#
mkdir -p ~/q/agent/tools
touch ~/q/agent/{config.yaml,main.py,crew.py,requirements.txt}
touch ~/q/agent/tools/{__init__.py,ssh_tool.py,mysql_tool.py,write_file_tool.py}3단계: 도구 작성 (핵심 작업량)#
각 도구는
BaseTool을 상속받는 Python 클래스이며, _run 메서드를 구현합니다.from crewai.tools import BaseTool
from pydantic import BaseModel, Field
class MySQLQueryInput(BaseModel):
query: str = Field(description="실행할 SQL 쿼리문")
class MySQLQueryTool(BaseTool):
name: str = "mysql_query"
description: str = "MySQL 읽기 전용 쿼리 실행..." # 모델은 이것을 보고 이 도구를 언제 사용할지 결정합니다.
args_schema: Type[BaseModel] = MySQLQueryInput
def _run(self, query):
# 1. 보안 검사 (읽기 전용 허용 목록)
# 2. 쿼리 실행
# 3. 포맷된 결과 반환 (문자열)
return "Result text"도구 개발 포인트:
description을 명확하게 작성하세요—모델이 호출 시점을 결정하는 데 의존합니다._run은 일반 텍스트를 반환합니다—모델은 텍스트만 처리할 수 있습니다.- 좋은 보안 차단을 구현하세요—모델이 위험한 작업을 시도할 수 있습니다.
- 타임아웃 제어를 추가하세요—
tail -f와 같은 명령이 무한정 차단되는 것을 방지합니다.
4단계: LLM 연결 구성#
# config.yaml
llm:
model: "openai/claude-sonnet-4-5-20250929"
base_url: "https://your-api-gateway/v1"
api_key: "sk-xxx"from crewai import LLM
llm = LLM(
model="openai/claude-sonnet-4-5-20250929",
base_url="https://your-api-gateway/v1",
api_key="sk-xxx"
)참고: API 게이트웨이가 OpenAI 호환 프로토콜을 사용하는 경우, 모델 이름에openai/접두사를 붙여야 litellm이 OpenAI 채널을 사용합니다.
5단계: 에이전트 조립#
from crewai import Agent, Task, Crew
agent = Agent(
role="DBA 운영 전문가",
goal="MySQL 및 Linux 운영 상태 진단",
backstory="당신은 MySQL 5.7/8.0에 능숙한 시니어 DBA입니다...",
tools=[ssh_tool, mysql_tool, write_tool],
llm=llm,
verbose=True,
)6단계: 실행#
task = Task(
description="사용자 질문: %s" % user_input,
expected_output="진단 결과 및 제안 (한국어로)",
agent=agent,
)
crew = Crew(agents=[agent], tasks=[task])
result = crew.kickoff()
print(result)7. 실습: 완전한 진단 프로세스#
에이전트에게 실제 작업을 부여해 봅시다: "SQL 응답 시간과 메모리 리소스를 분석하세요."
에이전트가 작업을 시작하면, 디버그 모드에서 전체 상호작용 과정을 볼 수 있습니다:
라운드 1: 모델이 문제를 받고, 먼저 슬로우 쿼리 설정을 확인하기로 결정합니다.
Action: mysql_query → SHOW GLOBAL VARIABLES LIKE '%slow%'
Observation: slow_query_log=ON, long_query_time=0.5라운드 2: 모델이 슬로우 쿼리 임계값이 0.5초임을 알고, 슬로우 쿼리 개수를 계속 확인합니다.
Action: mysql_query → SHOW GLOBAL STATUS LIKE 'Slow_queries'
Observation: Slow_queries=21라운드 3 - 8: 모델이 QPS, 스레드 상태, 잠금 정보, 쿼리 캐시 등을 계속 조회합니다...
라운드 9 - 12: 모델이 여전히 시스템 리소스를 확인해야 한다고 생각하고, SSH를 통해
top, free 등의 명령어를 자동으로 실행합니다.라운드 18: 모델이 마침내 충분한 정보를 얻었다고 판단하고, 최종 답변을 출력합니다:
- 슬로우 쿼리 개수: 21, 임계값 0.5초.
- QPS 통계 및 슬로우 쿼리 비율.
- 잠금 대기 분석.
- 메모리 사용 상태.
- 종합 점수 및 최적화 제안.
전체 과정에서, 여러분은 단 하나의 명령만 입력했지만, 에이전트는 자동으로 18라운드의 진단을 완료했습니다. 이것이 에이전트의 매력입니다.
8. 함정 기록#
실제 개발 중에 마주친 문제와 해결책 (이 경험은 매우 중요합니다; 코드가 처음 시도에서 바로 실행될 확률은 거의 0에 가깝습니다):
| 문제 | 원인 | 해결책 |
| --- | --- | --- |
| MySQL root 연결 거부됨 | root가 소켓 연결만 허용함 | SSH + mysql CLI 방식으로 변경 |
| 모델이 prefill 오류 보고 | 일부 백엔드가 어시스턴트 prefill을 지원하지 않음 | 지원되는 모델 버전으로 전환 |
| litellm을 찾을 수 없음 |
openai/ 접두사는 라우팅을 위해 litellm이 필요함 | pip install 'litellm<1.60' |
| chromadb가 sqlite3 버전이 너무 낮다고 보고 | 시스템 내장 sqlite 버전이 부족함 | pip install pysqlite3-binary + monkey-patch |
| numpy가 CPU와 호환되지 않음 | numpy 2.x는 새로운 명령어 세트를 요구함 | pip install 'numpy<2' |
| tail -f가 도구가 절대 반환하지 않게 함 | paramiko recv_exit_status()가 무한정 블록됨 | 채널 수준의 논블로킹 읽기 + 데드라인 타임아웃으로 전환 |
| SHOW SLAVE STATUS\G가 오류 보고 | \G는 mysql CLI 대화형 명령어로, 배치 모드는 이를 지원하지 않음 | 모델이 자동으로 \G를 제거하고 재시도함 |
| 디버그 로그가 출력되지 않음 | 프레임워크가 커스텀 로거를 재정의함 | Monkey-patch로 커스텀 로거 보호 |핵심 경험: 모델이 처음 시도에서 생성한 코드는 거의 직접 실행되지 않습니다. 여러분은 제공해야