초급
Agentic Memory: 상세 분석
Agentic Memory: 상세 분석
어느 날, 당신이 뛰어난 프리랜서를 고용했다고 상상해보세요. 첫날, 그녀는 놀라웠습니다. 모든 버그를 잡아내고, 깔끔한 문서를 작성했으며, 당신이 미처 생각하지 못한 개선 사항까지 제안했습니다. 당신은 깊은 인상을 받았습니다.
둘째 날, 당신이 들어가서 말합니다. "어제 논의했던 그 문제 기억나?"
그녀는 잠시 멈춥니다. 당신을 바라봅니다. 살짝 미소를 짓습니다.
"죄송합니다... 무슨 문제였죠?"
기억도 없고, 맥락도 없습니다. 완전히 사라졌습니다. 지금 이 글을 쓰면서도 저는 충격을 받을 것입니다.
이것이 바로 대부분의 LLM이 작동하는 방식입니다. 모든 새로운 대화는 새로운 시작입니다. 모델은 당신이 누군지, 함께 무엇을 구축했는지, 또는 몇 분 전 다른 채팅 창에서 논의한 내용조차 알지 못합니다.
단순한 챗봇에게는 괜찮습니다. 하지만 작업을 실행하고, 결정을 내리며, 시간이 지남에 따라 개선되는 에이전트에게 이런 기억상실증은 치명적입니다.
진정한 지능은 단순히 잘 응답하는 것만이 아니기 때문입니다. 그것은 기억하고, 배우며, 이전에 있었던 일을 바탕으로 발전하는 것입니다.
기억은 상태 비저장 시스템을 진정으로 진화할 수 있는 무언가로 바꾸는 것입니다.
Agentic Memory란 정말 무엇일까요?#
Agentic Memory는 단순히 하나의 개념이 아닙니다. 이는 백그라운드에서 작동하는 시스템, 즉 다양한 유형의 저장소, 정보 검색 방법, 그리고 이 모든 것을 관리하는 스마트한 전략의 조합으로, 에이전트가 시간이 지남에 따라 맥락을 유지할 수 있도록 해줍니다.
핵심 아이디어는 간단합니다. 메모리는 하나의 작업만 수행하는 것이 아니라, 동시에 세 가지 매우 다른 작업을 수행합니다.
➜ **연속성(Continuity)**은 정체성에 관한 것입니다. 에이전트가 당신이 누구인지, 당신의 선호도는 무엇인지, 그리고 함께 무엇을 구축했는지 아는 방법입니다. 이것이 없으면 모든 상호작용이 처음부터 시작하는 것처럼 느껴집니다.
➜ **맥락(Context)**은 현재 작업에 관한 것입니다. 방금 무슨 일이 일어났는지, 어떤 도구가 사용되었는지, 그 결과로 무엇이 반환되었는지, 그리고 다음에 무엇을 해야 하는지입니다. 이것이 다단계 워크플로우가 무너지는 것을 방지합니다.
➜ **학습(Learning)**은 더 나아지는 것에 관한 것입니다. 무엇이 효과가 있었고, 무엇이 효과가 없었는지 이해하고, 같은 실수를 반복하지 않으면서 시간이 지남에 따라 결정을 점진적으로 개선하는 것입니다.
이 모든 것이 합쳐져 에이전트가 일관되고, 신뢰할 수 있으며, 모든 상호작용마다 조금 더 지능적으로 느껴지게 만듭니다.

잘 설계된 에이전트 메모리 시스템은 이 세 가지를 모두 처리하며, 각각에 대해 다른 저장소 백엔드를 사용합니다.
4가지 메모리 유형#
이 분야는 네 가지 뚜렷한 메모리 유형으로 수렴되었습니다. 이를 각각 특정 작업에 맞게 진화된 뇌의 네 가지 다른 부분으로 생각해보세요.

1. 인컨텍스트 메모리 (In-context memory)#
컨텍스트 윈도우는 에이전트의 작업 데스크입니다. 그 위의 모든 것은 즉시 접근 가능합니다. 모델은 단일 순방향 패스로 이를 추론할 수 있습니다. 검색 단계가 필요하지 않습니다.
하지만 데스크에는 크기 제한이 있습니다. 모든 토큰은 비용과 시간이 듭니다. 그리고 세션이 종료되면 데스크는 깨끗이 지워집니다.
컨텍스트에는 무엇이 있을까요?
- 시스템 프롬프트: 에이전트 페르소나, 규칙, 기능, 현재 날짜/사용자 정보
- 대화 기록: 현재 세션 동안의 주고받은 내용
- 도구 호출 결과: 에이전트가 방금 호출한 도구의 출력
- 검색된 메모리: 외부 저장소에서 가져온 청크
- 스크래치패드: 중간 추론 과정 (단계별 사고 출력)
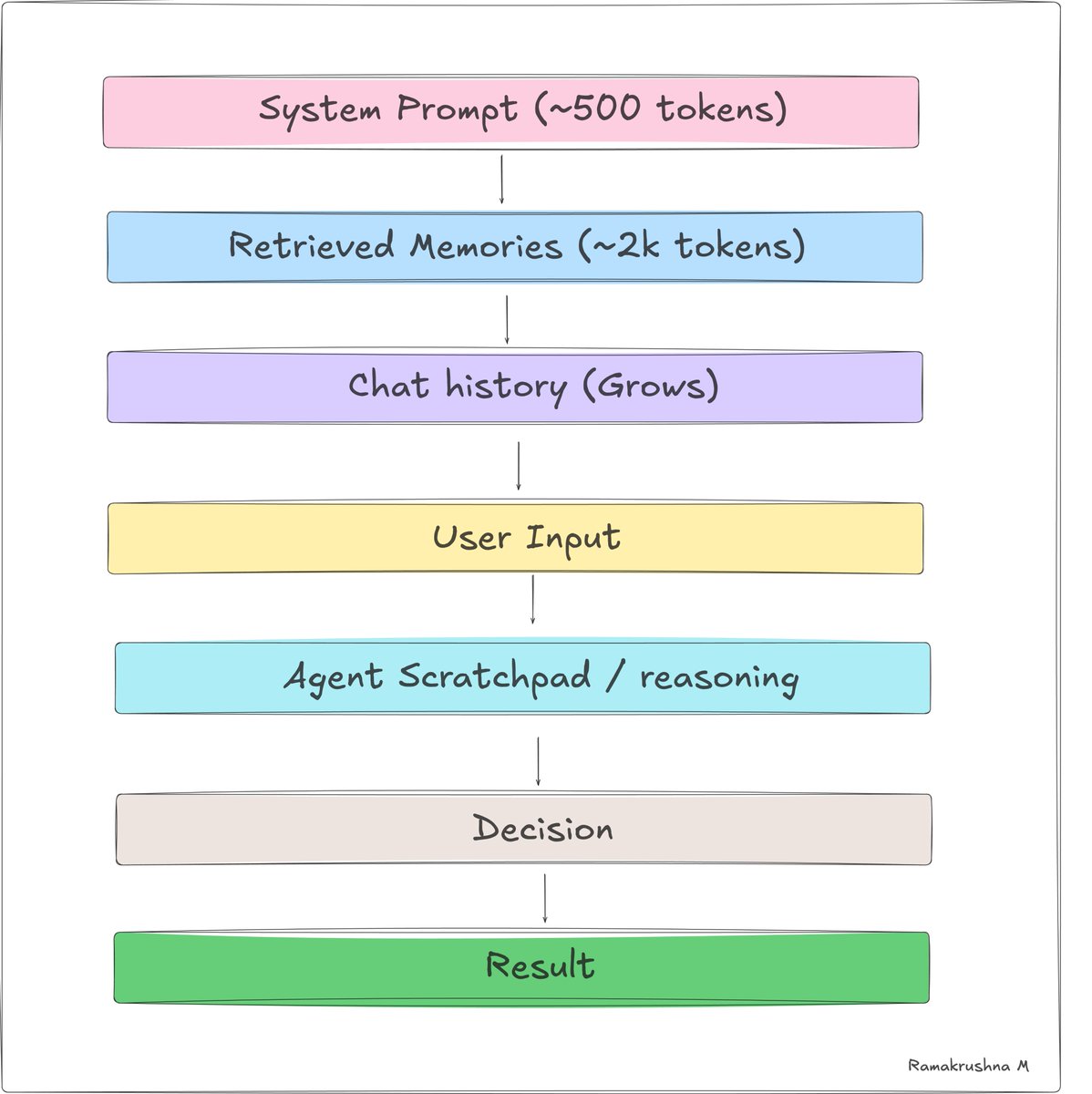
슬라이딩 윈도우 문제
긴 대화에서 기록이 누적되어 결국 컨텍스트 제한을 초과합니다. 가장 오래된 메시지를 자르는 단순한 해결책은 중요한 초기 맥락을 잃게 만듭니다. 더 나은 전략은 다음과 같습니다.
- 요약(Summarization): 주기적으로 오래된 턴을 간단한 요약으로 압축하고 이를 원본 대신 사용합니다.
- 선별적 유지(Selective retention): 핵심 사실, 결정 또는 도구 결과가 포함된 턴은 유지하고, 잡담은 버립니다.
- 외부 메모리로 오프로드(Offload to external memory): 중요한 사실을 벡터 저장소로 추출한 다음 필요할 때 검색합니다.
2. 외부 메모리 (External memory)#
외부 메모리는 모델 외부에 지속되는 모든 것, 즉 데이터베이스, 벡터 저장소, 키-값 저장소 및 파일입니다. 세션 경계를 넘어 생존합니다. 올바르게 저장하면 에이전트가 6개월 전의 일을 기억할 수 있습니다.
외부 저장소에는 두 가지 유형이 있습니다.
구조화된 저장소 (정확한 조회): PostgreSQL, Redis, SQLite. 키, ID 또는 SQL로 쿼리합니다. 빠르고 예측 가능하며 사용자 프로필, 선호도 및 구조화된 데이터에 적합합니다.
벡터 저장소 (의미 기반 검색): Pinecone, Chroma, pgvector. 의미로 쿼리합니다. "이 개념과 유사한 기억을 찾아줘." 비구조화된 노트와 일화적 회상에 필수적입니다.
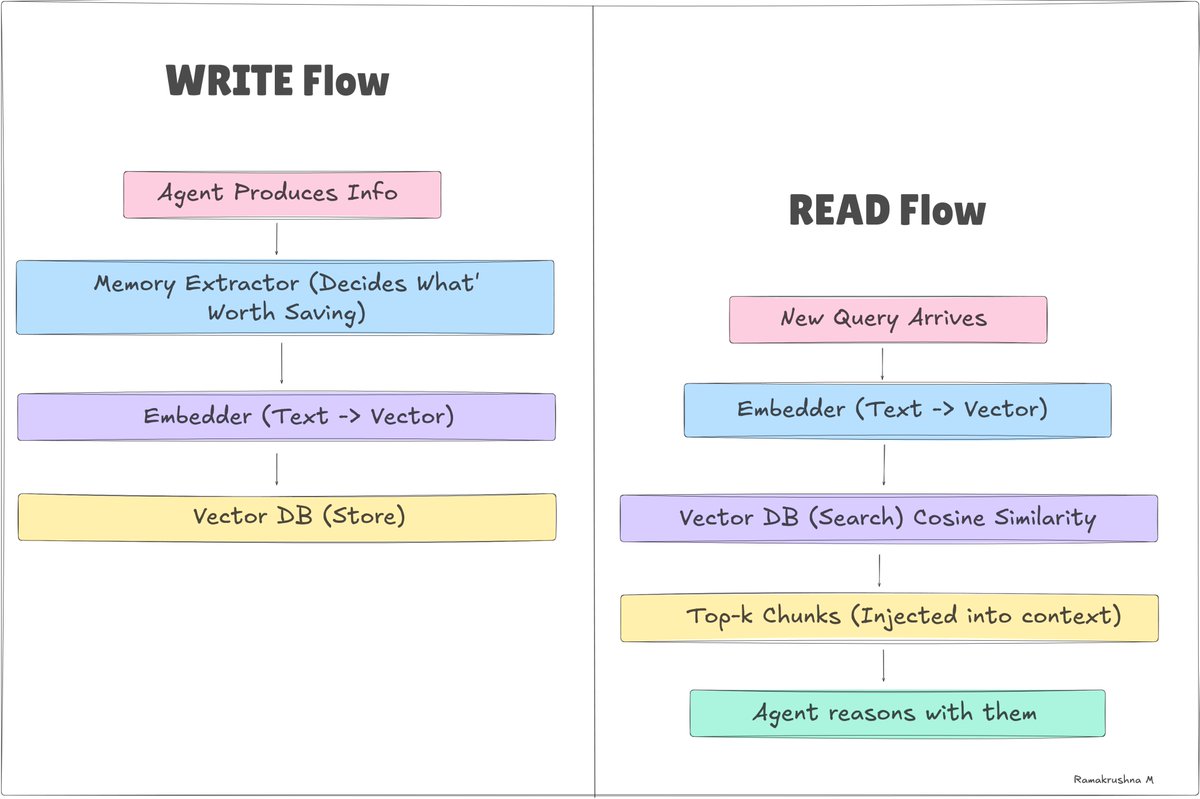
검색 단계는 병목 현상입니다. 올바른 기억을 검색하지 못하면 에이전트는 마치 그 기억이 존재하지 않는 것처럼 행동합니다. 좋은 메모리 아키텍처는 20% 저장소와 80% 검색 설계입니다.
3. 일화적 메모리 (Episodic memory)#
일화적 메모리는 가장 과소평가된 유형입니다. 외부 메모리가 사실을 저장하는 반면, 일화적 메모리는 사건, 특히 과거 행동의 결과를 저장합니다.
가장 간단한 형태는 구조화된 로그입니다. 에이전트가 작업을 완료할 때마다 무슨 일이 일어났는지 기록합니다. 시간이 지남에 따라 이 로그는 에이전트가 결정을 내리기 전에 참고할 수 있는 풍부한 자기 지식의 원천이 됩니다.
에피소드의 예시는 다음과 같습니다.
{
"episode_id": "ep_20240315_003",
"timestamp": "2024-03-15T14:23:11Z",
"task": "50페이지 PDF를 3개의 핵심 요점으로 요약",
"approach": "순차적 청킹, 청크당 2000 토큰",
"outcome": "성공",
"duration_ms": 4820,
"token_cost": 12400,
"quality_score": 0.91,
"notes": "잘 작동함. 계층적 청킹이 더 빠를 것임.",
"embedding": [0.023, -0.441, 0.182, /* ... 1536 차원 */]
}새로운 작업이 들어오면 에이전트는 의미적으로 가장 유사한 과거 에피소드를 검색하고 이를 사용하여 전략을 선택합니다. 이는 본질적으로 수작업 데이터셋이 아닌 개인 이력으로부터의 퓨샷 학습입니다.
성찰 루프(Reflection loop)👇

4. 의미/파라메트릭 메모리 (Semantic/parametric memory)#
이것은 모델이 태어날 때부터 가지고 있는 메모리입니다. 모든 것이 훈련 중에 가중치에 인코딩됩니다. 즉, 세상에 대한 사실, 언어 패턴, 추론 전략, 코딩 규칙, 문화적 지식 등입니다.
항상 존재합니다. 에이전트는 이를 검색할 필요가 없습니다. 하지만 다음과 같은 엄격한 제한 사항이 있습니다.
- 훈련 시점에 고정됨: 모델은 기준일 이후에 발생한 일을 알지 못합니다.
- 런타임에 업데이트 불가: 재훈련이나 미세 조정 없이 새로운 영구적인 사실을 주입할 수 없습니다.
- 불투명함: 모델이 무엇을 "알고" 있고 무엇을 모르는지 정확히 검사할 수 없습니다.
- 환각 발생 가능성: 모델은 그럴듯하지만 틀린 완성으로 빈 공간을 채웁니다.
시간에 민감하거나, 도메인 특화적이거나, 개인 정보와 관련된 모든 것에 대해 파라메트릭 메모리에 의존하지 마십시오. 외부 검색을 사용하십시오. 파라메트릭 메모리는 더 나은 출처가 없을 때 일반적인 세계 지식을 위한 대비책입니다.
올바른 사고 모델: 파라메트릭 메모리는 에이전트의 일반 교육입니다. 외부, 일화적 및 인컨텍스트 메모리는 에이전트의 현장 경험입니다. 최고의 에이전트는 둘 다 결합합니다.
에이전트 루프에서 메모리는 어떻게 흐를까요?#
이제 모든 것을 종합해 보겠습니다. 에이전트가 요청을 처리할 때마다 발생하는 일, 즉 모든 메모리 시스템이 작동하는 모습입니다.

메모리 작업이 LLM 호출을 감싸고 있다는 점에 주목하십시오. 호출 전에 검색하고, 호출 후에 기록합니다. 모델 자체는 상태 비저장(stateless)입니다. 메모리 시스템이 상태를 가진(stateful) 인식 에이전트의 환상을 제공하는 것입니다.
메모리 레이어 구축#
직접 만들어 봅시다. Python과 OpenAI의 임베딩, 로컬 벡터 저장소로 ChromaDB를 사용하겠습니다. 동일한 개념은 다른 스택에도 적용 가능합니다—라이브러리만 교체하면 됩니다.
pip install chromadb openai anthropic python-dotenvMemoryStore 클래스#
메모리 쓰기(임베딩 포함)와 의미론적 검색을 처리합니다. 다른 모든 기능의 기반이 되는 핵심 요소입니다.
import chromadb
from openai import OpenAI
from datetime import datetime
import json, uuid
class MemoryStore:
"""AI 에이전트를 위한 영구 벡터 메모리"""
def __init__(self, agent_id: str, persist_dir: str = "./memory_db"):
self.agent_id = agent_id
self.openai = OpenAI()
# ChromaDB는 벡터를 디스크에 저장하며, 재시작 후에도 유지됨
self.client = chromadb.PersistentClient(path=persist_dir)
self.collection = self.client.get_or_create_collection(
name=f"agent_{agent_id}_memories",
metadata={"hnsw:space": "cosine"} # 코사인 유사도
)
def _embed(self, text: str) -> list[float]:
"""OpenAI를 사용하여 텍스트를 임베딩 벡터로 변환"""
response = self.openai.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def remember(
self,
content: str,
memory_type: str = "general",
metadata: dict = None
) -> str:
"""메모리 저장. 메모리 ID를 반환"""
memory_id = str(uuid.uuid4())
embedding = self._embed(content)
meta = {
"type": memory_type,
"timestamp": datetime.utcnow().isoformat(),
"agent_id": self.agent_id,
**(metadata or {})
}
self.collection.add(
ids=[memory_id],
embeddings=[embedding],
documents=[content],
metadatas=[meta]
)
return memory_id
def recall(
self,
query: str,
k: int = 5,
memory_type: str = None,
min_relevance: float = 0.6
) -> list[dict]:
"""쿼리에 가장 관련성 높은 k개의 메모리 검색"""
query_embedding = self._embed(query)
where = {"type": memory_type} if memory_type else None
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=k,
where=where,
include=["documents", "metadatas", "distances"]
)
memories = []
for doc, meta, dist in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0]
):
relevance = 1 - dist # 코사인 거리 → 유사도
if relevance >= min_relevance:
memories.append({
"content": doc,
"metadata": meta,
"relevance": round(relevance, 3)
})
return sorted(memories, key=lambda x: x["relevance"], reverse=True)
def forget(self, memory_id: str):
"""특정 메모리 삭제 (GDPR 준수, 오래된 데이터 등)"""
self.collection.delete(ids=[memory_id])EpisodicLogger 클래스#
이제 상위에 에피소드 로깅 레이어를 추가해 보겠습니다.
from .store import MemoryStore
from dataclasses import dataclass, asdict
from typing import Optional
import time
\@dataclass
class Episode:
task: str
approach: str
outcome: str # "success" | "partial" | "failure"
duration_ms: int
token_cost: int
quality_score: float # 0.0 – 1.0, 평가자 또는 사용자가 설정
notes: str = ""
error: Optional[str] = None
class EpisodicLogger:
def __init__(self, memory_store: MemoryStore):
self.store = memory_store
def log(self, episode: Episode):
"""에피소드를 검색 가능한 문서로 메모리에 저장"""
# 의미론적 검색을 위한 풍부한 텍스트 표현 구축
doc = (
f"Task: {episode.task}\n"
f"Approach: {episode.approach}\n"
f"Outcome: {episode.outcome}\n"
f"Notes: {episode.notes}"
)
self.store.remember(
content=doc,
memory_type="episode",
metadata={
"outcome": episode.outcome,
"quality_score": episode.quality_score,
"duration_ms": episode.duration_ms,
"token_cost": episode.token_cost,
}
)
def recall_similar(self, task: str, k: int = 3) -> list[dict]:
"""현재 작업과 유사한 과거 에피소드 검색"""
return self.store.recall(
query=task,
k=k,
memory_type="episode",
min_relevance=0.65
)통합: 메모리 증강 에이전트#
import anthropic
from memory.store import MemoryStore
from memory.episodic import EpisodicLogger, Episode
import time
class MemoryAugmentedAgent:
def __init__(self, agent_id: str):
self.client = anthropic.Anthropic()
self.memory = MemoryStore(agent_id)
self.episodes = EpisodicLogger(self.memory)
def _build_memory_context(self, user_message: str) -> str:
"""관련 메모리 검색 및 주입용 형식으로 변환"""
# 관련 사실에 대한 의미론적 검색
memories = self.memory.recall(user_message, k=4)
# 유사한 과거 작업 접근 방식
episodes = self.episodes.recall_similar(user_message, k=2)
context_parts = []
if memories:
context_parts.append("## 관련 메모리\n" +
"\n".join([
f"- [{m['metadata']['type']}] {m['content']}"
f" (관련성: {m['relevance']})"
for m in memories
])
)
if episodes:
context_parts.append("## 유사한 과거 작업\n" +
"\n".join([
f"- {e['content'][:200]}..."
for e in episodes
])
)
return "\n\n".join(context_parts) if context_parts else ""
def run(self, user_message: str) -> str:
start = time.time()
# 1. 관련 메모리 검색
memory_context = self._build_memory_context(user_message)
# 2. 주입된 메모리로 시스템 프롬프트 구성
system = """당신은 메모리를 가진 유용한 에이전트입니다.
과거 상호작용의 관련 컨텍스트에 접근할 수 있습니다.
이 컨텍스트를 사용하여 더 나은 개인화된 응답을 제공하세요."""
if memory_context:
system += f"\n\n{memory_context}"
# 3. 모델 호출
response = self.client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
system=system,
messages=[{"role": "user", "content": user_message}]
)
answer = response.content[0].text
duration = int((time.time() - start) * 1000)
# 4. 다음 번을 위해 유용한 정보를 메모리에 저장
self.memory.remember(
content=f"사용자 질문: {user_message[:200]}",
memory_type="interaction"
)
# 5. 에피소드 로깅
self.episodes.log(Episode(
task=user_message[:200],
approach="메모리 검색을 사용한 단일 턴",
outcome="success",
duration_ms=duration,
token_cost=response.usage.input_tokens + response.usage.output_tokens,
quality_score=1.0, # 프로덕션에서는 평가 결과에서 가져옴
))
return answer벡터 데이터베이스#
이는 모든 진지한 메모리 시스템의 핵심입니다. SQL처럼 정확히 일치하는 항목을 쿼리하는 대신, 고차원 공간에서 벡터의 가장 가까운 이웃을 찾습니다. 이것이 의미론적 검색을 가능하게 하는 방식입니다. 즉, 단어가 전혀 공유되지 않더라도 개념적으로 관련된 메모리를 찾을 수 있습니다.
유사도 검색의 작동 방식#
모든 메모리는 벡터(OpenAI의 임베딩 모델을 사용한 1,536개의 부동소수점 배열)로 변환됩니다. 개념적으로 유사한 텍스트는 유사한 벡터를 생성합니다. 쿼리할 때는 쿼리를 임베딩하고 코사인 유사도를 사용하여 가장 가까운 벡터를 찾습니다.
import numpy as np
def cosine_similarity(a: list, b: list) -> float:
"""
1.0 = 완전히 동일한 의미
0.0 = 관련 없음
-1.0 = 반대 의미
"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 예시: 다음 두 문장은 높은 유사도를 가집니다
embedding_a = embed("사용자는 다크 모드를 선호합니다")
embedding_b = embed("그들은 인터페이스 테마가 어두운 것을 좋아합니다")
score = cosine_similarity(embedding_a, embedding_b)
# → ~0.91 (매우 유사함)로컬 개발에는 ChromaDB로 시작하세요. 배포할 준비가 되면, 이미 Postgres를 사용 중이고 추가 인프라가 필요 없다면 pgvector를 평가해보세요. 진지한 규모의 확장이 필요할 때는 Pinecone이나 Qdrant를 사용하세요.
메모리 관리#
진정한 메모리 시스템은 단순히 축적만 하지 않습니다. 큐레이션합니다. 계속해서 커지고 초점이 없는 저장소는 시간이 지남에 따라 성능이 저하됩니다. 검색은 더 시끄러워지고, 지연 시간은 증가하며, 모순된 메모리는 에이전트를 혼란스럽게 만듭니다.
망각 전략이 필요합니다. 세 가지 주요 접근 방식은 다음과 같습니다:
1. 시간 기반 감쇠#
오래된 메모리는 관련성이 떨어집니다. 최신성과 의미론적 관련성의 조합으로 메모리에 점수를 매깁니다. 연구에서 사용되는 공식:
import math
from datetime import datetime
def memory_score(
relevance: float, # 코사인 유사도 0–1
importance: float, # 쓰기 시점에 저장된 중요도 0–1
created_at: datetime, # 메모리가 생성된 시간
recency_weight: float = 0.3,
decay_factor: float = 0.995
) -> float:
"""
Generative Agents 논문(Park et al., 2023)에서 영감을 받음.
관련성, 중요성, 최신성의 균형을 맞춤.
"""
hours_old = (datetime.utcnow() - created_at).total_seconds() / 3600
recency = math.pow(decay_factor, hours_old)
return (
relevance * 0.4 +
importance * 0.3 +
recency * recency_weight
)2. 쓰기 시점의 중요도 점수 매기기#
메모리를 저장할 때, 모델에게 자체 출력의 중요도를 평가하도록 요청하세요. 높은 점수의 항목만 저장합니다. 이렇게 하면 소스에서 노이즈를 필터링할 수 있습니다.
import re
async def score_importance(client, content: str) -> float:
"""LLM에게 정보를 저장할 가치가 있는지 물어봅니다 (0.0 ~ 1.0)."""
prompt = f"""향후 상호작용을 위해 이 정보를 저장하는 것의 중요도를 평가하세요.
0.0 = 사소함 (인사)
0.5 = 보통 유용함
1.0 = 중요함 (선호도, 오류, 결정)
정보: {content}
숫자만 답변하세요."""
try:
response = await client.messages.create(
model="claude-3-haiku-20240307", # 현재 사용 가능한 Haiku 모델 사용
max_tokens=10,
messages=[{"role": "user", "content": prompt}]
)
# float/int처럼 보이는 첫 번째 문자열 추출
text = response.content[0].text.strip()
match = re.search(r"[-+]?\d*\.\d+|\d+", text)
if match:
score = float(match.group())
return max(0.0, min(1.0, score))
except Exception:
pass
return 0.5 # 기본 폴백3. 주기적 통합#
야간 작업을 실행하여 중복되거나 매우 유사한 메모리를 단일 표준 요약으로 병합합니다. 이는 인간의 수면이 기억을 통합하는 방식과 유사합니다.
async def consolidate_memories(store: MemoryStore, similarity_threshold: float = 0.92):
"""벡터 검색을 사용하여 거의 중복된 메모리를 효율적으로 병합합니다."""
all_mems = store.collection.get(include=["documents", "embeddings", "ids"])
if not all_mems["ids"]:
return
visited = set()
consolidated_docs = []
for i, (mem_id, doc, emb) in enumerate(zip(
all_mems["ids"], all_mems["documents"], all_mems["embeddings"]
)):
if mem_id in visited:
continue
# 벡터 저장소의 내장 검색을 사용하여 이웃 찾기
# 수동 중첩 루프보다 훨씬 빠름
results = store.collection.query(
query_embeddings=[emb],
n_results=10, # 예상 밀도에 따라 조정
include=["documents", "distances"]
)
# 그룹 구성원 식별 (1.0 - distance = 코사인 유사도)
group = [doc]
visited.add(mem_id)
for res_id, res_doc, dist in zip(results["ids"][0], results["documents"][0], results["distances"][0]):
sim = 1.0 - dist
if res_id != mem_id and res_id not in visited and sim >= similarity_threshold:
group.append(res_doc)
visited.add(res_id)
# 그룹 처리
if len(group) > 1:
summary = await summarize_group(group) # 비동기 함수일 가능성 높음
consolidated_docs.append(summary)
else:
consolidated_docs.append(doc)
# 원자적 대체: 비우고 다시 채우기
store.collection.delete(where={})
for doc in consolidated_docs:
await store.remember(doc)마지막 생각#
결국, 메모리는 AI를 단순한 도구가 아닌 파트너처럼 느끼게 만드는 요소입니다. 메모리가 없으면 모든 상호작용은 매번 처음부터 시작됩니다. 메모리가 있으면 에이전트는 시간이 지남에 따라 이해하고, 적응하며, 개선할 수 있습니다.
진정한 힘은 모델 자체에 있는 것이 아니라, 모델이 무엇을 기억하고, 무엇을 잊으며, 그 정보를 어떻게 사용할지 설계하는 방식에 있습니다.
메모리 계층을 올바르게 구축하면, 다른 모든 것이 더 똑똑해집니다.
코드는 AI가 생성했습니다.
더 많은 게시물을 보려면 @techwith_ram을 팔로우하세요.