초급
Anthropic Harness의 진화를 통해 이해하는 Hermes Supervisor
Anthropic Harness의 진화를 통해 Hermes Supervisor 이해하기
Anthropic은 에이전트 하네스 설계에 관한 네 편의 엔지니어링 블로그 게시물을 발표했습니다. 이를 함께 살펴보면 명확한 진화 경로가 드러납니다. 에이전트가 스스로 해결할 수 없는 문제에 직면할 때마다, 이를 지원하기 위해 새로운 역할이 도입되었습니다.
동시에, 최근 커뮤니티에서 널리 논의되고 있는 Hermes 슈퍼바이저 솔루션도 역할을 추가하는 방식이지만, 다른 단계의 문제를 해결합니다.
오늘은 이 두 가지를 함께 살펴보며 Hermes가 실제로 해결하는 문제가 무엇인지, 그리고 이것이 Anthropic이 논의한 평가자(evaluator)와 어떻게 근본적으로 다른지 알아보겠습니다.
Anthropic Harness의 단계별 진화 과정#
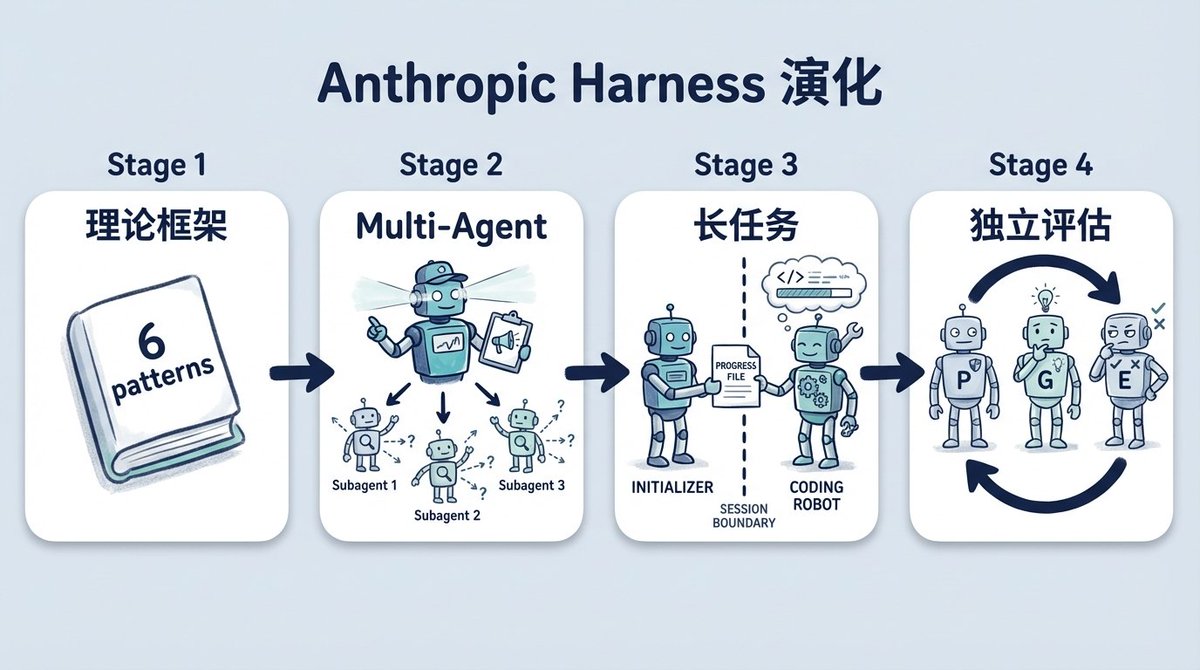
첫 번째 게시물인 "효과적인 에이전트 구축(Building Effective Agents)"은 이론적 프레임워크를 제시했습니다. 여섯 가지 워크플로우 패턴을 소개했으며, 이후 논의에서 가장 관련성이 높은 것은 평가자-최적화자(evaluator-optimizer) 패턴입니다. 한 에이전트가 생성하고, 다른 에이전트가 평가 및 피드백을 제공하며, 두 역할이 루프를 반복하는 방식입니다.
두 번째 게시물은 Anthropic이 Research 기능을 위해 실제 시스템에 평가자-최적화자 패턴을 직접 적용한 내용을 기록했습니다. 리드 에이전트가 연구 질문을 분해하고, 하위 에이전트들이 여러 방향으로 병렬 검색을 수행하며, 리드 에이전트가 수집된 결과가 충분한지 판단합니다. 부족할 경우, 새로운 하위 에이전트를 파견하여 격차를 메웁니다. BrowseComp 평가 데이터를 분석한 결과, 토큰 사용량이 성능 변동의 80%를 설명했으며, 모델 선택과 도구 호출 횟수가 나머지를 설명했습니다. 멀티 에이전트의 이점은 기본적으로 더 많은 토큰을 사용하여 더 철저한 탐색을 수행하는 데서 비롯됩니다.
세 번째 게시물은 장기 실행 작업의 문제를 다루었습니다. 4시간짜리 코딩 작업에서 에이전트 성능이 불안정했습니다. 처음부터 전체 프로젝트를 한 번에 완료하려고 시도하다가 중간에 컨텍스트를 소진하거나, 컨텍스트 제한에 가까워지면서 서둘러 마무리하려는 행동을 보였습니다. Anthropic은 이를 "컨텍스트 불안(context anxiety)"이라고 명명했습니다. 해결책은 프로세스를 두 단계로 분할하는 것이었습니다. 초기화 에이전트(initializer agent)가 첫 번째 세션을 처리하여 프로젝트 환경을 설정하고 모든 기능을 나열합니다. 이후 코딩 에이전트들은 각 세션당 하나의 기능만 처리하고, 다음 세션이 사용할 진행 파일을 작성합니다. 하네스의 형태가 갖춰지기 시작했습니다.
지난주 네 번째 게시물에서는 독립적인 평가자 역할을 도입했습니다. 이전에는 에이전트가 자신의 코드를 평가할 때 지나치게 관대하여 문제를 발견해도 "별거 아니야"라고 스스로를 설득하는 경향이 있었습니다. GAN과 유사한 접근 방식을 시도했습니다. 플래너(planner)가 요구사항을 분해하고, 생성기(generator)가 코드를 작성하며, 독립적인 평가자(evaluator)가 이를 평가합니다. 웹 앱 개발 실험에서 평가자는 Playwright를 사용하여 실제 사용자처럼 앱을 작동시키고 점수를 매긴 후, 실패할 경우 생성기로 작업을 다시 보냈습니다.
역할을 분리한 후, 한 가지를 발견했습니다. 독립적인 평가자를 엄격하게 만드는 것이 생성기가 자신의 코드에 대해 엄격해지도록 만드는 것보다 훨씬 쉽다는 점입니다. 원문에는 다음과 같이 명시되어 있습니다. "작업을 수행하는 에이전트와 이를 평가하는 에이전트를 분리하는 것이 강력한 지렛대임이 입증되었습니다." 수행자와 평가자를 분리하는 것이 자기 비판보다 더 효과적인 지렛대입니다.
또한 하네스 구성 요소가 고정되어 있지 않다는 사실도 발견했습니다. Opus 4.5용으로 설계된 하네스를 Opus 4.6에서 실행하자, 스프린트 분해가 불필요해졌습니다. 모델이 스스로 일관성을 유지할 수 있었기 때문입니다. 게시물은 다음과 같이 언급합니다. "하네스의 모든 구성 요소는 모델이 스스로 할 수 없는 것에 대한 가정을 인코딩하며, 이러한 가정은 정기적으로 재평가할 가치가 있습니다." 각 하네스 구성 요소는 모델의 무능력에 대한 가정을 구현하며, 이러한 가정은 정기적으로 재평가되어야 합니다. 본질적으로, 현재 하네스 노력은 모델 성능 부족으로 인한 부정적 영향을 완화하는 것을 목표로 합니다.
네 게시물의 공통된 방향은 다음과 같습니다. 평가자의 판단이 생성기로 다시 흘러가고, 생성기는 피드백을 사용하여 기준을 충족할 때까지 작업을 다시 수행합니다. 이것은 품질 관리 루프입니다. 커뮤니티의 다른 사람들이 논의한 에이전트의 실패 모드도 동일한 범주에 속합니다. 복잡한 작업을 피하기 위해 스텁(stub)을 작성하거나, 검증을 통과하기 위해 약한 테스트를 작성하거나, 관련 문서를 업데이트하지 않고 코드를 변경하여 저장소를 지저분하게 만드는 행위 등입니다. 일반적인 해결책은 실행 중에 검사 및 수정 역할을 추가하는 것입니다.
그러나 이러한 모든 논의는 한계점에 도달합니다. 에이전트의 작업 실행 중 품질 관리입니다. 에이전트가 프로덕션에 배포되어 매일 자동으로 실행된 후에는 어떻게 지속적으로 모니터링할까요? 이것은 Anthropic이 다루지 않은 질문입니다.
Hermes가 해결하는 문제는 무엇인가?#
먼저, Hermes가 무엇일까요? NousResearch가 구축한 독립적인 에이전트 시스템으로, 자체 CLI, 메시지 게이트웨이(Telegram, Discord, Slack 등 지원), 그리고 모든 LLM에 연결할 수 있는 기능을 갖추고 있습니다. 특정 프레임워크의 플러그인이 아니라 완전히 독립적인 에이전트입니다.
Graeme(@gkisokay)는 OpenClaw의 슈퍼바이저로 Hermes를 구성한 방법에 대한 글을 작성했습니다. 그의 시나리오는 다음과 같습니다. OpenClaw는 이미 프로덕션에서 실행 중이며, 크론 작업, 점수 매기기, 일일 초안 작성을 자동으로 처리하고 있었습니다. 출력 품질 자체는 문제가 아니었지만, 그는 지속적으로 오류 로그, 출력을 확인하고 수동 개입이 필요한 상황을 찾아야 했습니다.
그의 해결책은 OpenClaw에 더 나은 하네스를 추가하는 것이 아니라, Hermes를 독립적인 슈퍼바이저로 사용하여 OpenClaw의 출력을 특별히 감시하는 것이었습니다.
두 봇은 구조화된 프로토콜을 사용하여 비공개 Discord 채널을 통해 통신합니다. 프로토콜에는 네 가지 마커만 있습니다.
STATUS_REQUEST- "어떻게 진행되고 있나요?"REVIEW_REQUEST- "이것을 검토해 주세요."ESCALATION_NOTICE- "이것에 대해 결정해야 합니다."ACK- "수신 완료, 종료합니다."
규칙은 엄격합니다. 모든 메시지는 하나의 마커와 @멘션을 포함해야 합니다.
ACK는 종료 신호입니다. 수신 시 응답이 전송되지 않습니다. 마커가 없는 메시지는 정보 제공용으로 간주되어 응답을 받지 않습니다. 각 라운드는 하나의 메시지로 구성되며, 최대 3라운드로 제한됩니다.네 가지 마커, 3라운드 제한, 하나의 하드 종료 조건. 이것은 아마도 최소 기능의 멀티 에이전트 통신 프로토콜일 것입니다. 이는 두 봇이 끝없이 서로 응답하는 고전적인 멀티 에이전트 실패 모드를 직접적으로 방지합니다.
Anthropic의 평가자와의 실제 차이점은 무엇인가?#
겉으로 보기에 Hermes도 역할 분리를 포함하고 있어 Anthropic의 평가자와 비슷한 일을 하는 것처럼 보입니다. 하지만 정보 흐름은 완전히 다릅니다.
Anthropic의 평가자는 품질 검사관과 같습니다. 제품이 조립 라인에서 나오면 검사관이 확인하고, 불량이면 재작업을 위해 반송됩니다. 판단은 생성자에게 다시 흘러가 기준이 충족될 때까지 새로운 반복을 주도합니다.
Hermes는 응급 분류 데스크에 더 가깝습니다. 실제 상호 작용을 보면 이를 명확히 알 수 있습니다:
정상 흐름에서 Hermes는 OpenClaw에게 상태를 묻습니다. OpenClaw는 6개의 cron이 모두 실행되었다고 보고하고, 지난주 높은 오탐지율 때문에 점수 임계값을 60에서 65로 올릴 것을 제안합니다. Hermes는 이 제안을 평가하고, 증거가 변경을 뒷받침한다고 판단하여
ACK를 보내 상호 작용을 종료합니다. 여기서 Hermes는 단순히 "문제없다"고 말하는 것이 아니라 제안의 근거를 평가했습니다.비정상 흐름에서 OpenClaw는 아침 보고서가 24시간보다 오래된 두 개의 신호를 참조한다고 보고합니다. Hermes는 어떤 특정 두 신호가 오래되었는지 진단하고, 두 가지 처리 제안(새 데이터로 재실행, 또는 적시성 메모와 함께 있는 그대로 게시)을 제공한 후, 최종 결정을 위해 사람에게 에스컬레이션합니다.
분류 데스크와 품질 검사관의 차이점: 검사관의 판단은 에이전트에게 다시 흘러가 작업을 다시 수행합니다. 분류 데스크의 판단은 에이전트에게 다시 흘러가지 않습니다. 자체적으로 케이스를 종료하거나(
ACK), 진단 및 제안과 함께 사람에게 넘깁니다(ESCALATION_NOTICE). Graeme의 전체 프로토콜 설계 전반에 걸쳐 Hermes가 OpenClaw에게 출력을 다시 하라고 지시하는 경로는 없습니다.
공유된 설계 원칙#
적용되는 단계는 다르지만, 세 가지 기본 원칙은 동일합니다:
- 역할 분리는 자기 평가보다 더 신뢰할 수 있습니다. Anthropic은 하네스 실험에서 이를 검증했고, Graeme은 프로덕션 환경에서의 실제 운영을 통해 동일한 결론에 도달했습니다. 에이전트가 자신의 코드를 판단하든, 사용자가 에이전트의 출력을 모니터링하든, 작업을 별도의 역할에 할당하는 것이 더 신뢰할 수 있습니다.
- 통신 프로토콜에는 하드 종료 조건이 필요합니다. Anthropic의 Research 시스템 하위 에이전트는 토큰 예산과 도구 호출 제한을 통해 수렴했습니다. Hermes는
ACK터미널과 3라운드 제한을 사용합니다. 명시적인 종료 조건이 없는 멀티 에이전트 시스템은 결국 무한 루프로 인해 죽게 됩니다. - 하네스 구성 요소는 현재 모델 성능 격차에 대한 가정을 인코딩하며 정기적인 스트레스 테스트가 필요합니다. Opus 4.5는 스프린트 분해가 필요했지만, Opus 4.6은 필요하지 않았습니다. 마찬가지로, 모델의 성능이 향상됨에 따라 감독자가 내려야 할 판단은 줄어들 것입니다. 미래에는 일상적인
ACK가 완전히 자동화되어 감독자는 진정한 예외 상황에만 개입할 수 있습니다.
병목 단계 식별#
- 에이전트의 출력 품질이 여전히 불안정하다면, 병목은 개발 단계에 있습니다. Anthropic의 네 편의 블로그 게시물이 현재 가장 체계적인 참고 자료입니다. 평가자-최적화자 패턴부터 시작하세요.
- 에이전트가 이미 실행 중이지만 여전히 사용자가 온콜(on-call) 역할을 하고 있다면, 병목은 운영 단계에 있습니다. Hermes의 접근 방식을 연구할 가치가 있습니다. 에이전트가 스스로 수정하도록 하는 것이 아니라, 문제가 없을 때는 사용자를 귀찮게 하지 않고, 문제가 있을 때는 진단 및 제안과 함께 사용자에게 오는 분류 데스크를 추가하는 것입니다.
이 두 단계는 상호 배타적이지 않습니다. 순차적입니다. 먼저 잘 작동하게 만든 다음, 안정적으로 실행되게 만드세요.
참고 링크#
- Anthropic - Building Effective Agents: https://www.anthropic.com/engineering/building-effective-agents
- Anthropic - How We Built Our Multi-Agent Research System: https://www.anthropic.com/engineering/multi-agent-research-system
- Anthropic - Effective Harnesses for Long-Running Agents: https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
- Anthropic - Harness Design for Long-Running Application Development: https://www.anthropic.com/engineering/harness-design-long-running-apps
- Graeme (@gkisokay) - The Setup That Saved Me Hours Every Day: OpenClaw + Hermes: https://x.com/gkisokay/status/2037902655016804496
- NousResearch Hermes Agent: https://github.com/NousResearch/hermes-agent