초급
프롬프트에서 컨텍스트로, 하네스로: AI 엔지니어링의 세 가지 패러다임 전환
프롬프트에서 컨텍스트로, 하네스로: AI 엔지니어링의 세 가지 패러다임 전환
2026년 초, Anthropic과 OpenAI는 거의 같은 주에 각각 하네스 엔지니어링(Harness Engineering)에 관한 실무 글을 발표했습니다. 여기에 에이전트 메모리 인프라에 관한 두 편의 학술 논문과 커뮤니티에서의 세대별 엔지니어링 패러다임 진화에 대한 논의가 더해지면서, 완전한 그림이 드러나고 있습니다.

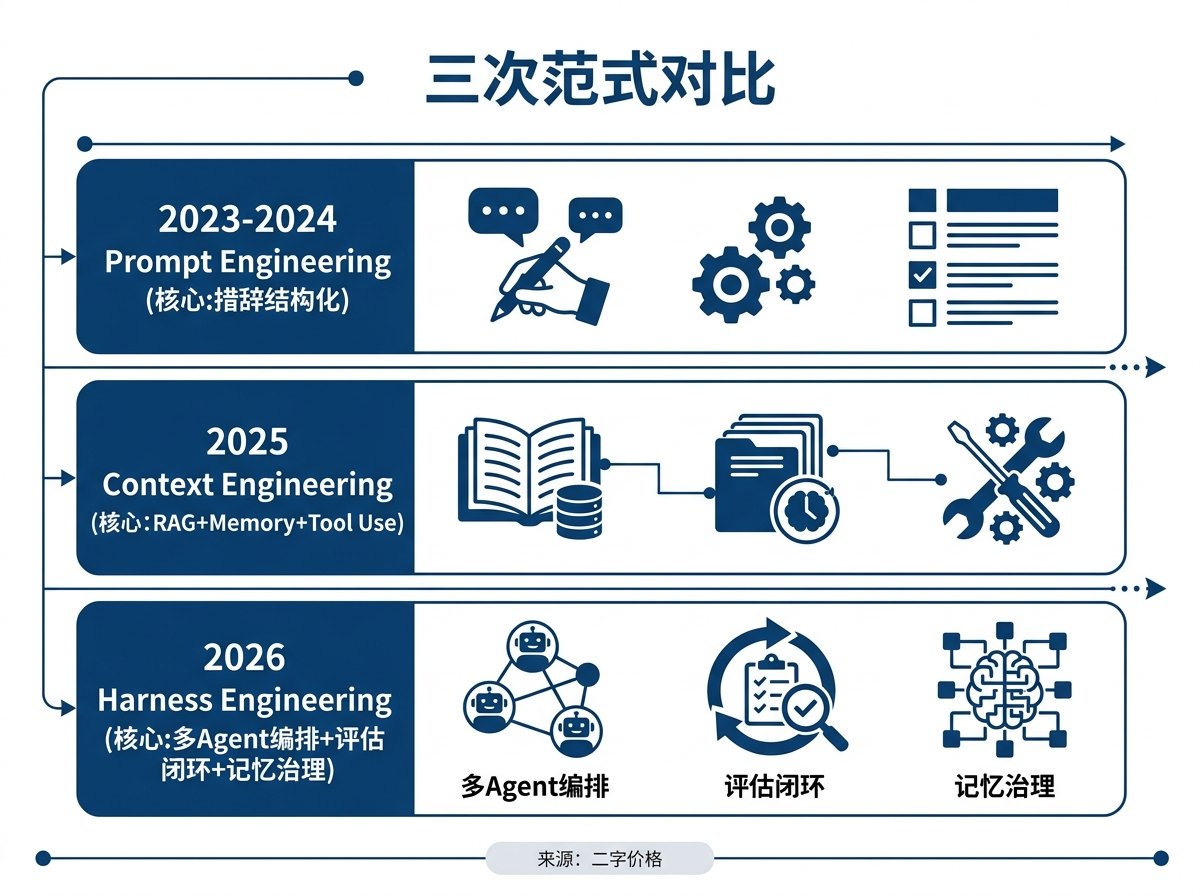
세대별 엔지니어링 패러다임이 해결하는 문제#
2023년부터 2024년까지는 프롬프트 엔지니어링(Prompt Engineering)의 시대였습니다. 핵심 문제는 모델과 어떻게 대화하여 더 나은 답변을 얻을 것인가였습니다. 어휘 선택, 형식, 퓨샷 예시, 사고의 사슬(Chain of Thought) 등 모든 기술은 '단일 대화'를 중심으로 전개되었습니다.
2025년에는 컨텍스트 엔지니어링(Context Engineering)이 주류 개념으로 자리 잡았습니다. Shopify CEO Tobi의 "컨텍스트 엔지니어링이 새로운 기술이다"라는 말이 널리 퍼졌습니다. 핵심 문제가 바뀌었습니다. 프롬프트만으로는 부족하며, 전체 컨텍스트 윈도우를 엔지니어링 대상으로 설계해야 합니다. RAG 검색, 장기 컨텍스트 관리, 도구 사용(Tool Use) 오케스트레이션, 메모리 시스템 등이 모두 이 범주에 속합니다. 여러분이 최적화하는 것은 모델이 보는 모든 정보입니다.
2026년 초, 하네스 엔지니어링(Harness Engineering)이라는 개념이 두 대기업에 의해 거의 동시에 제기되었습니다. 핵심 문제는 다시 한번 업그레이드되었습니다. 에이전트가 몇 시간 또는 며칠 동안 자율적으로 실행될 수 있게 되면서, 단일 컨텍스트 최적화만으로는 턱없이 부족합니다. 여러분이 설계해야 하는 것은 에이전트의 전체 실행 환경, 즉 다중 에이전트 협업 아키텍처, 평가 피드백 루프, 아키텍처 제약 조건의 기계적 실행, 메모리의 거버넌스 및 검증 메커니즘입니다.
세대 간의 관계: 각 세대는 이전 세대를 포함합니다. 하네스는 컨텍스트를 포함하고, 컨텍스트는 프롬프트를 포함합니다. 그러나 각 세대가 해결하는 핵심 문제는 완전히 다릅니다.
Anthropic의 접근 방식: 에이전트가 서로 평가하게 하라#
Anthropic 엔지니어 Prithvi Rajasekaran의 실험은 직관에 반하는 사실을 밝혀냈습니다. 에이전트가 자신의 작업을 평가하는 것은 거의 쓸모가 없다는 것입니다.
출력 품질의 높고 낮음에 관계없이, 에이전트는 자신에 대한 평가를 항상 긍정적으로 내립니다. 생성과 평가를 두 개의 독립적인 에이전트로 분리한 후에는 효과가 완전히 달라졌습니다. 평가자는 코드를 읽고 점수를 매기는 것이 아니라, Playwright를 사용하여 실제로 페이지를 조작하고, 버튼을 클릭하고, 양식을 작성하고, 기능을 검증한 후 네 가지 차원(디자인 품질, 독창성, 장인 정신 디테일, 기능 완성도)에 따라 점수를 매깁니다.
프론트엔드 디자인 실험에서 생성자는 평가자와 5~15회의 반복을 거친 후, 10회차에 3D 공간 탐색 솔루션을 만들어냈습니다. 풀스택 개발 실험은 더욱 복잡했습니다. 세 명의 에이전트가 분업했습니다. 기획자는 한 문장의 요구사항을 완전한 제품 사양으로 확장하고, 생성자는 React+FastAPI+PostgreSQL을 사용하여 단계적으로 구현했으며, 평가자는 QA 테스트를 수행했습니다.
비교 데이터는 매우 직관적입니다. 단일 에이전트는 20분 만에 9달러를 소비했지만, 결과물은 사용할 수 없었습니다. 완전한 하네스는 6시간 동안 200달러를 소비했지만, 스프라이트 애니메이션, AI 통합 및 내보내기 기능을 갖춘 완전한 게임을 제공했습니다.
가장 가치 있는 발견: Opus 4.6의 성능이 향상됨에 따라 스프린트 분해는 생략할 수 있게 되었지만, 평가자는 생략할 수 없었습니다. 하네스의 각 구성 요소는 모델의 한계에 대한 가정을 코딩하고 있습니다. 모델이 강력해지면 일부 가정은 더 이상 유효하지 않지만, 어떤 가정은 영원히 유효합니다. 어떤 것을 유지하고 어떤 것을 제거할지 식별하는 것이 하네스 엔지니어링의 핵심 기술입니다.

OpenAI의 접근 방식: 수백만 줄의 코드를 손으로 한 줄도 쓰지 않고#
OpenAI의 실험은 더욱 과감했습니다. 5개월 동안 소규모 팀이 Codex Agent를 사용하여 약 백만 줄의 코드로 구성된 프로덕션 시스템을 구축했습니다. 손으로 쓴 코드는 단 한 줄도 없었습니다. 애플리케이션 로직, 문서, CI 구성, 관찰 가능성 인프라, 툴체인 등 모든 것이 에이전트에 의해 생성되었습니다.
엔지니어의 역할은 완전히 바뀌었습니다. 그들은 세 가지 일을 합니다. 개발 환경을 설계하고, 구조화된 프롬프트로 의도를 표현하며, 에이전트에 피드백 루프를 제공합니다. OpenAI는 이것을 깊이 우선 작업(depth-first working)이라고 부릅니다. 큰 목표를 작은 구성 요소로 분해하고, 에이전트가 각 구성 요소를 구축하도록 한 다음, 이러한 구성 요소를 사용하여 더 복잡한 작업을 잠금 해제하는 것입니다.
아키텍처 거버넌스는 이 시스템이 작동할 수 있게 한 핵심 요소입니다. 종속성 계층은 엄격하게 6개 계층으로 나뉩니다. Types, Config, Repo, Service, Runtime, UI입니다. 각 계층의 경계는 linter와 CI를 통해 기계적으로 실행되며, 문서 규칙이 아닌 코드로 강제됩니다. 에이전트가 아키텍처 제약 조건을 위반하는 PR은 자동으로 거부됩니다.
Martin Fowler의 평가는 적절합니다. "하네스 엔지니어링은 컨텍스트 엔지니어링, 아키텍처 제약 조건 및 가비지 컬렉션을 기계가 읽을 수 있는 아티팩트로 코딩하여 에이전트가 체계적으로 실행할 수 있게 합니다."

메모리 시스템: 하네스에서 가장 간과하기 쉬운 계층#
Anthropic은 평가 루프를, OpenAI는 아키텍처 제약 조건을 강조했지만, 두 회사 모두 메모리에 대해 깊이 논의하지 않았습니다. 이恰好이 두 편의 학술 논문이 채운 공백입니다.
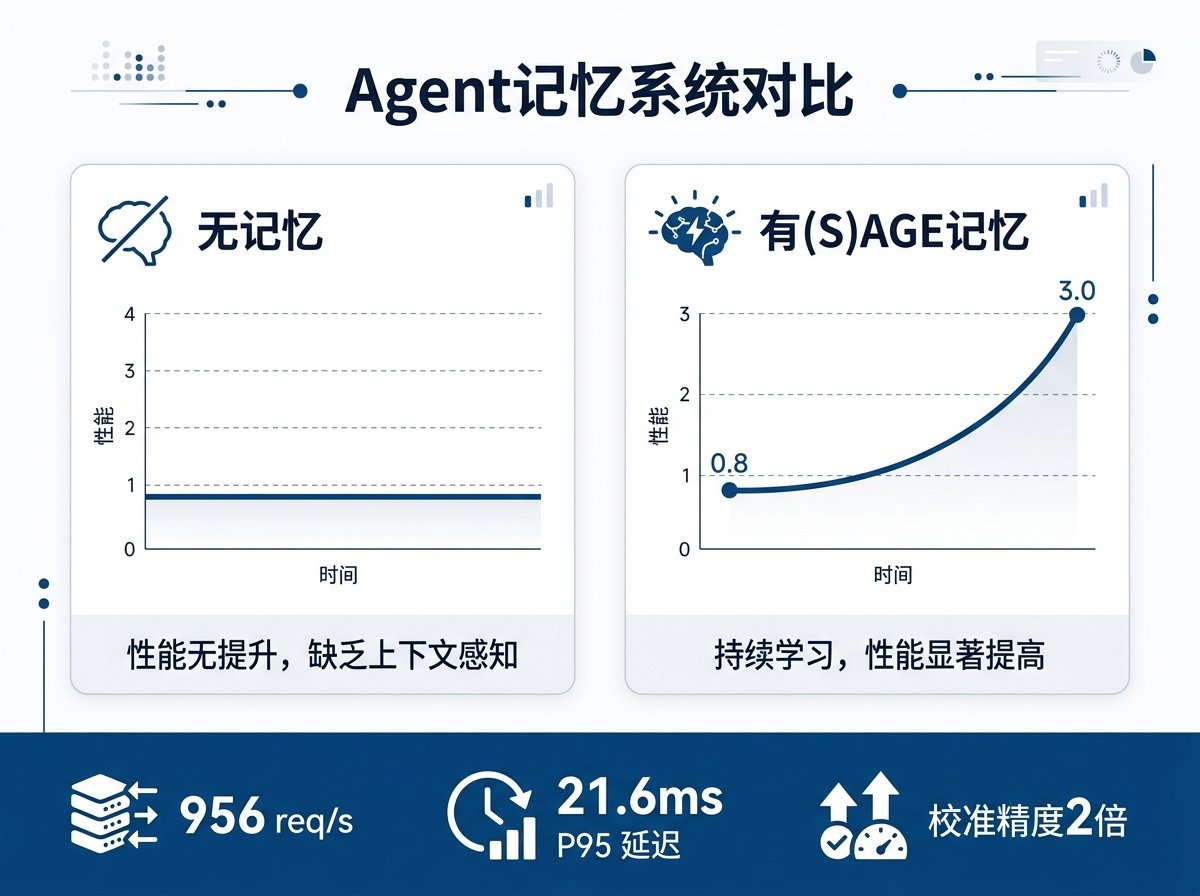
첫 번째 논문은 (S)AGE 논문으로, 비잔틴 장애 허용(BFT) 다중 에이전트 메모리 인프라를 제안합니다. 핵심 문제는 여러 에이전트가 지식 베이스를 공유할 때, 기록되는 지식의 신뢰성을 어떻게 보장할 것인가입니다. 한 에이전트가 환각으로 인해 잘못된 정보를 기록하거나, 적대적 공격을 통해 가짜 기억이 주입될 수 있습니다.
이에 대한 해결책은 경험 증명(Proof of Experience) 합의 메커니즘입니다. 각 에이전트는 평판 가중치를 가지며, 이 가중치는 네 가지 요소(역사적 정확도, 도메인 관련성, 활동성, 독립적 검증 횟수)에 의해 결정됩니다. 에이전트가 제출한 기억은 가중 투표 검증을 통과해야 지식 베이스에 기록될 수 있습니다. 4노드 BFT 네트워크에 배포되어 956 req/s 쓰기, 21.6ms P95 쿼리 성능을 보여줍니다. 이 메모리 시스템을 갖춘 에이전트의 보정 정확도는 메모리가 없는 기준선의 두 배였습니다.
두 번째 종적 학습(Longitudinal Learning) 논문은 더 근본적인 질문에 답합니다. 메모리가 있는 에이전트 시스템은 시간이 지남에 따라 정말로 좋아질까요?
실험 설계는 매우 교묘했습니다. 치료 그룹: 3줄 프롬프트 + (S)AGE 메모리, 각 라운드마다 이전 모든 라운드에서 축적된 지식을 쿼리할 수 있습니다. 대조 그룹: 전문가가 정성껏 작성한 50~200줄 프롬프트, 그러나 메모리는 없으며, 각 라운드를 처음부터 시작합니다. 10라운드를 실행한 후, 치료 그룹의 레드팀 평가 난이도는 0.8에서 3.0으로 증가한 반면(Spearman rho=0.716, p=0.020), 대조 그룹은 증가 추세가 전혀 없었습니다(rho=0.040, p=0.901).
가장 중요한 점은 두 그룹의 절대적 성능 수준에 통계적 차이가 없었다는 것입니다(Cohen's d = -0.07). 3줄 프롬프트에 메모리를 더한 것과 200줄의 전문가 프롬프트가 비슷한 성적을 냈습니다. 차이는 학습 궤적에 있었습니다. 메모리가 있는 시스템은 실행할수록越来越好, 메모리가 없는 시스템은 항상 같은 수준에 머물렀습니다.
이는 메모리 계층이 에이전트 시스템에 제공하는 것이 더 높은 초기 성능이 아니라, 조직 수준의 종적 학습 능력임을 의미합니다. 인간 조직의 100번째 프로젝트는 일반적으로 첫 번째 프로젝트보다 더 좋습니다. 프로세스 문서, 사후 검토, 지식 베이스 축적이 있기 때문입니다. 이제 에이전트 시스템도 동일한 특성을 보이기 시작했습니다.
프롬프트 vs 컨텍스트 vs 하네스의 본질적 차이#
세대별 엔지니어링 패러다임의 차이는 한 문장으로 요약할 수 있습니다.
프롬프트 엔지니어링은 인간과 모델 간의 인터페이스를 최적화합니다.
컨텍스트 엔지니어링은 모델의 입력 공간을 최적화합니다.
하네스 엔지니어링은 에이전트의 전체 런타임 환경을 최적화합니다.
Anthropic의 실험은 평가 루프가 자체 평가보다 몇 자릿수 더 효과적임을 증명했습니다. OpenAI의 실험은 아키텍처 제약 조건이 에이전트가 수백만 줄의 코드 수준에서 일관성을 유지할 수 있게 함을 증명했습니다. 두 편의 논문은 합의 검증 메모리 시스템이 에이전트 조직에 종적 학습 능력을 부여할 수 있음을 증명했습니다.
이 세 가지 계층이 합쳐져 완전한 하네스를 구성합니다. 평가 메커니즘 + 아키텍처 제약 조건 + 메모리 거버넌스. 이 중 어떤 계층이라도 빠지면, 에이전트 시스템은 특정 차원에서 통제 불능 상태에 빠질 것입니다.
출처: Anthropic Engineering Blog / OpenAI Blog / (S)AGE Paper / Longitudinal Learning Paper