초급
AI 엔지니어 학습 로드맵
AI 엔지니어 학습 로드맵
약 2000개의 실제 채용 공고를 기반으로, 무엇을 어떤 순서로 배워야 하는지에 대한 실용적인 로드맵입니다.
AI 엔지니어링(단순한 ML 이론이 아닌)에 발을 들이고자 한다면, 이 로드맵이 실제 프로덕션 환경에서 시스템이 구축되는 방식과 가장 잘 맞습니다.
핵심: 작업의 80%를 차지하는 20%의 기술#
대부분의 사람들이 이 부분을 오해합니다.
AI 엔지니어링은 모델을 처음부터 훈련시키는 것이 아닙니다. LLM을 중심으로 시스템을 구축하는 것입니다.
1. LLM 기초#
여기서 시작하세요. 모든 것은 이것을 기반으로 합니다.
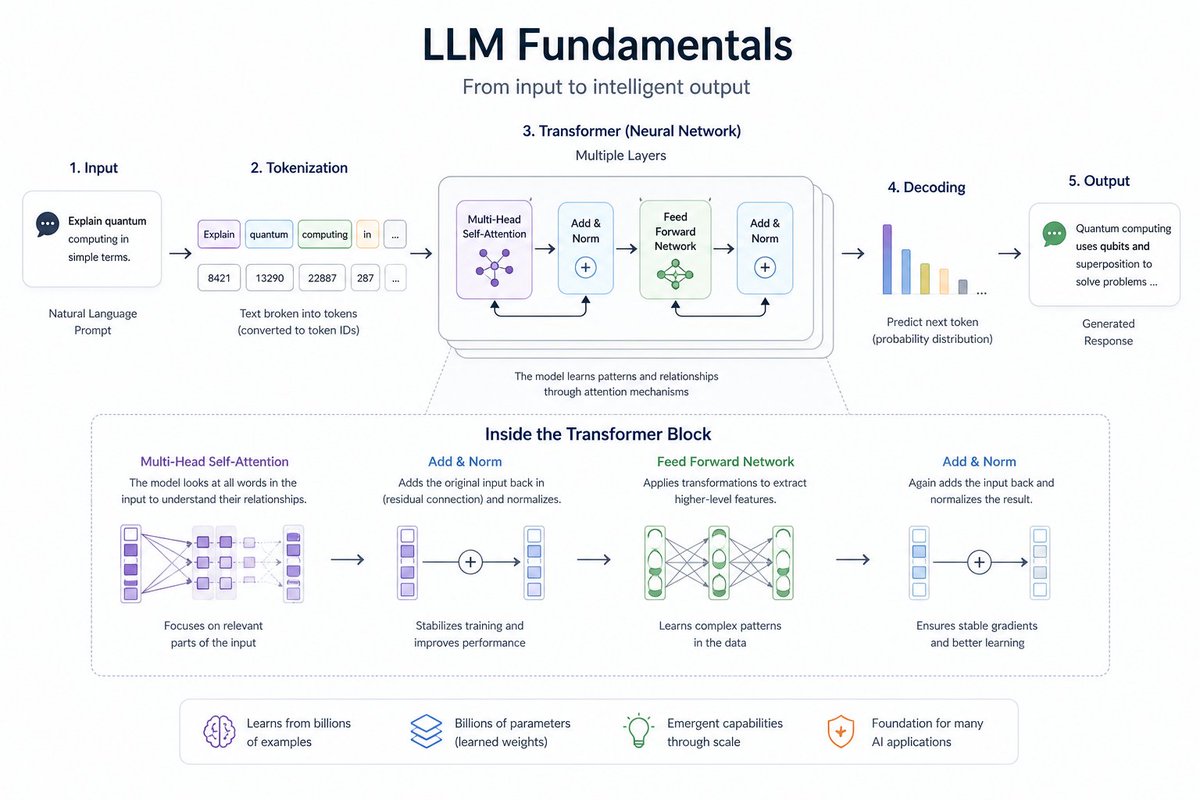
- LLM의 작동 방식 (높은 수준에서)
- LLM이 잘하는 것 vs 실패하는 것
- OpenAI, Anthropic과 같은 API 사용
- 구조화된 출력 (JSON, 스키마, 도구 응답)
- 다양한 작업에 대한 프롬프트 엔지니어링
목표: "모델과 채팅"하는 단계에서 모델을 예측 가능하게 제어하는 단계로 나아가기
2. RAG (검색 증강 생성)#
이것은 대부분의 실제 AI 시스템의 핵심입니다.
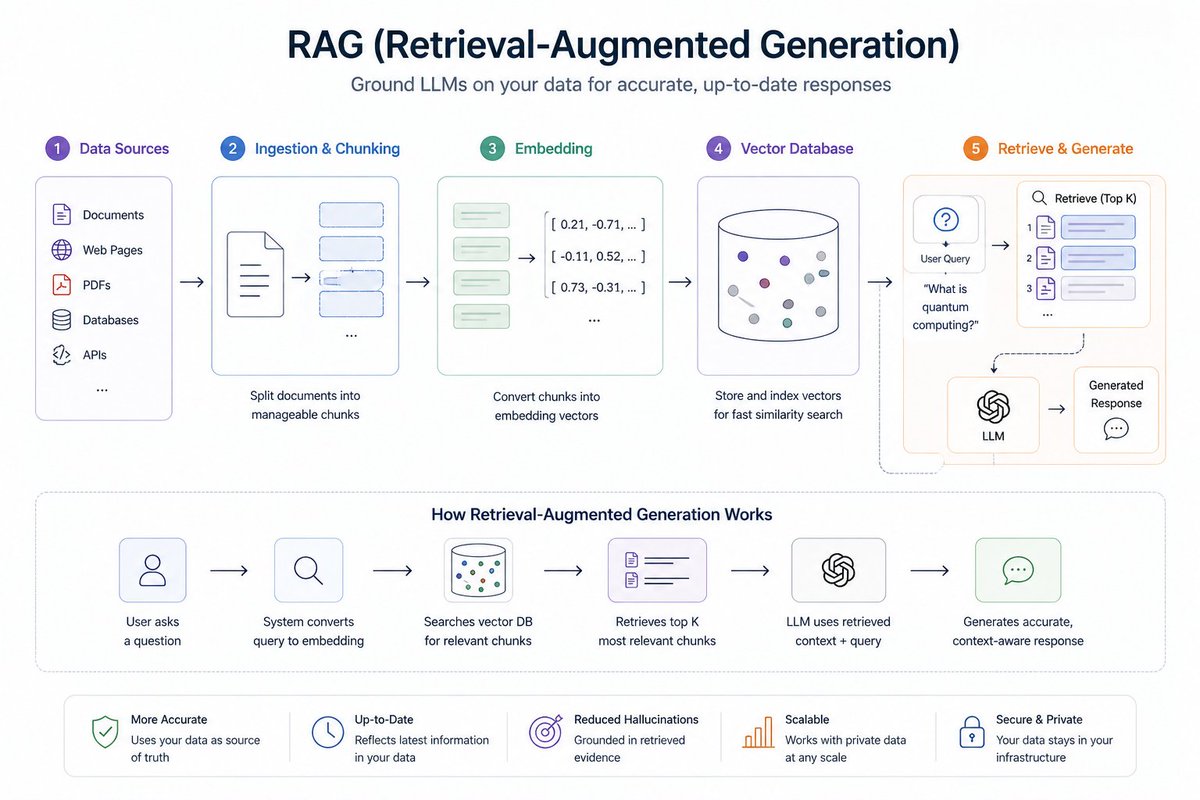
- LLM에 사용자 정의 데이터 주입
- 벡터 검색 + 의미론적 검색
- Elasticsearch, Qdrant와 같은 도구
- 청킹 전략 (사람들이 생각하는 것보다 더 중요합니다)
- 실제 데이터 처리: PDF, 웹 페이지, 대본
👉 실습 프로젝트:
- FAQ 도우미
- 문서 Q&A 시스템
- 내부 지식 검색
3. AI 에이전트#
여기서부터 흥미로워지고, 복잡해집니다.

- 도구 호출 (응답만 하는 것이 아니라 행동할 수 있는 LLM)
- 에이전트 루프: 생각행동 → 관찰 → 반복
- 프레임워크: LangChain, PydanticAI, OpenAI Agents SDK, Google ADK
- 모델 컨텍스트 프로토콜 (MCP)
- 다중 에이전트 시스템 (라우팅, 조정, 파이프라인)
👉 실습 프로젝트:
- 웹 리서치 에이전트
- 데이터 추출 파이프라인
- 다중 에이전트 워크플로우
4. AI 시스템 테스트#
과소평가되지만, 매우 중요합니다.
- 도구 사용 및 출력 테스트
- 일관성 평가
- LLM을 평가자로 사용 (네, 메타적이지만 유용합니다)
👉 목표: AI 시스템을 인상적일 뿐만 아니라 신뢰할 수 있게 만들기
5. 모니터링 및 관찰 가능성#
시스템이 무엇을 하는지 볼 수 없으면, 고칠 수도 없습니다.

- 에이전트 워크플로우 추적
- 상호 작용 로깅
- 비용 추적
- 피드백 루프
- 대시보드 (Grafana, OpenTelemetry)
👉 실제 영향: 이것이 데모와 프로덕션 시스템을 구분짓는 요소입니다
6. 평가#
대부분의 엔지니어가 이 단계를 건너뛰지만, 그 결과는 명백히 드러납니다.

- 오프라인 평가 데이터셋
- 검색 품질 측정
- 합성 데이터 생성
- 결과 기반 프롬프트 최적화
👉 목표: "느낌이 좋다"에서 "측정 가능하다"로 나아가기
7. 프로덕션 시스템#
여기서 AI 엔지니어의 가치가 드러납니다.
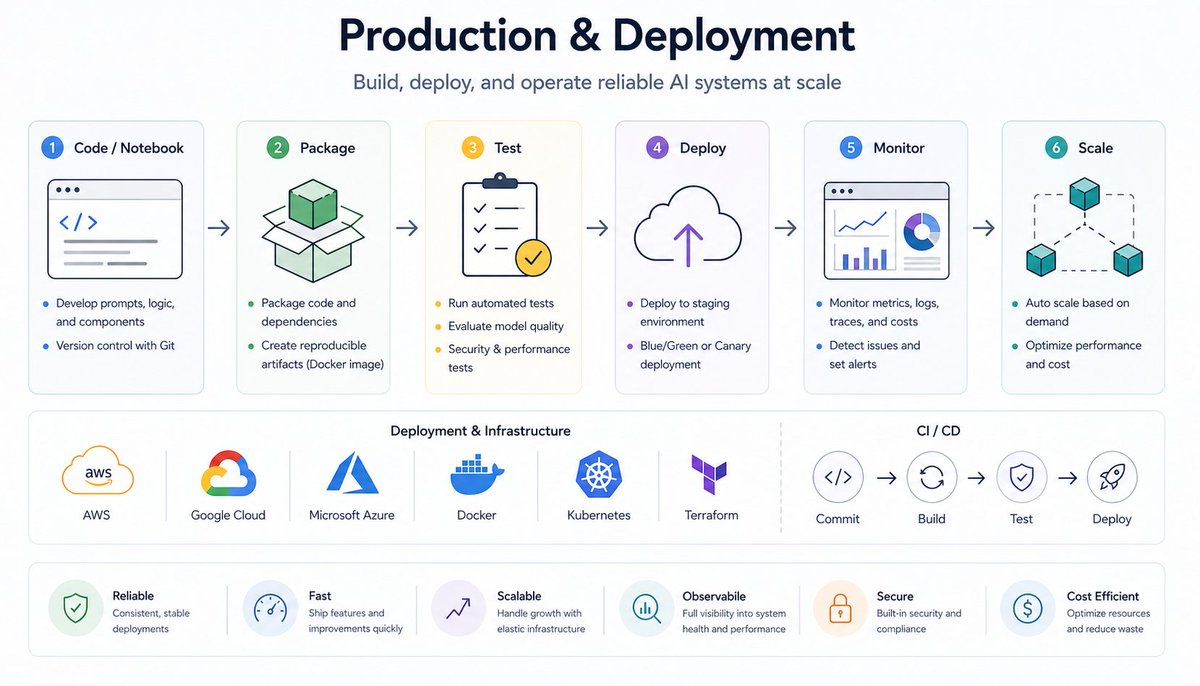
- 노트북을 실제 서비스로 전환
- 배포 (빠른 프로토타입용 Streamlit)
- 클라우드 플랫폼: AWS / GCP / Azure
- 가드레일 및 안전 계층
- 확장을 위한 병렬 처리
보조 기술 (채용 공고에서 실제로 요구하는 것)#
이것들은 선택 사항이 아닙니다. 모든 곳에서 등장합니다.
Python 및 엔지니어링 기초#
- Python (약 80% 이상의 역할에서 사용)
- 테스트, CI/CD, 코드 품질
- Git 워크플로우
웹 개발 (실제 제품용)#
- FastAPI (AI 앱의 백엔드 표준)
- React / Next.js (프론트엔드 계층)
- API: REST / GraphQL
클라우드 및 인프라#
- 최소 하나: AWS, GCP 또는 Azure
- Docker (필수)
- Kubernetes (확장용)
- Terraform (코드형 인프라)
데이터베이스#
- PostgreSQL (기본 선택)
- 벡터 DB: Pinecone, Weaviate, Qdrant, pgvector
- Redis (캐싱, 세션)
ML 기초 (충분할 만큼만)#
연구원이 될 필요는 없지만, 맥락은 알아야 합니다.
- PyTorch 기초
- 임베딩 (매우 중요)
- 파인튜닝 (API로 충분하지 않을 때)
- 모델 평가 기초
데이터 엔지니어링#
- ETL 파이프라인
- Airflow, Spark, Kafka
- Databricks, Snowflake와 같은 도구
Python 외의 언어#
- TypeScript (풀스택 AI에 매우 중요)
- SQL (실제 데이터 작업에 필수)
- Java / Go (백엔드 중심 역할용)
일반적인 AI 엔지니어링 스택#
현대적인 AI 시스템은 일반적으로 다음과 같습니다:
- 프론트엔드: React / Next.js
- 백엔드: FastAPI
- AI 오케스트레이션: LangChain, LangGraph, PydanticAI
- LLM: OpenAI, Anthropic, Groq, 로컬 모델
- 벡터 DB: Pinecone / Weaviate / Qdrant
- 인프라: Docker + Kubernetes + Cloud
- 모니터링: OpenTelemetry, Grafana
- 평가: LLM 평가자, Evidently와 같은 도구
기술 우선순위 (시간이 부족하다면)#
필수#
- Python
- 프롬프트 엔지니어링
- RAG 시스템
- 하나의 클라우드 플랫폼
- Docker
높은 가치#
- LangChain 또는 PydanticAI
- FastAPI
- TypeScript
- CI/CD
- Kubernetes
- PyTorch 기초
차별화 요소 (더 빨리 채용되는 데 도움)#
- 에이전트 프레임워크 (LangGraph, CrewAI)
- 모델 파인튜닝
- 평가 시스템
- 벡터 데이터베이스
- 다중 에이전트 아키텍처
최종 정리#
AI 엔지니어링은 유행하는 도구를 쫓는 것이 아닙니다.
LLM이 단지 하나의 구성 요소일 뿐인 신뢰할 수 있는 시스템을 구축하는 것입니다.
다음에 집중한다면:
- RAG
- 에이전트
- 평가
- 프로덕션 시스템
대부분의 지원자보다 앞서 있을 것입니다.
출처#
이 로드맵은 Alexey Grigorev의 원본 작업에서 많은 영감을 받았습니다:
스레드#
1#
https://x.com/ParasVerma7454/status/2048692381038543108
https://t.co/VXWvjhi22E
작성자: Luffytaro (@ParasVerma7454) URL: https://x.com/ParasVerma7454/status/2047952507029311621저는 Paras입니다. 시스템을 구축하고, 출시하고, 다음 시스템을 시작합니다.풀스택 및 AI 엔지니어 — 인턴십 또는 정규직 기회를 찾고 있습니다.저는 완전한 제품을 구축합니다: 깔끔한 백엔드, 실제 AI 통합, 출시 및 운영 중. 현재 SDE 인턴으로, 대부분의 시간을 실제 시스템을 구축하고 개선하는 데 보내고 있습니다.채용 중이거나 아는 분이 계시다면 DM 또는 답글을 남겨주세요. 추천은 감사히 받겠습니다.포트폴리오는 댓글에 있습니다.