초급
에이전트 하네스의 구조
에이전트 하네스의 구조
Anthropic, OpenAI, Perplexity, LangChain이 실제로 구축하고 있는 것에 대한 심층 분석입니다. 오케스트레이션 루프, 도구, 메모리, 컨텍스트 관리, 그리고 상태 비저장 LLM을 유능한 에이전트로 변환하는 모든 요소를 다룹니다.
챗봇을 만들어 본 적이 있을 겁니다. 아마 몇 가지 도구와 함께 ReAct 루프를 연결해 봤을 수도 있습니다. 데모에서는 잘 작동합니다. 그런데 프로덕션 수준의 무언가를 만들려고 하면 문제가 생기기 시작합니다. 모델이 세 단계 전에 무엇을 했는지 잊어버리고, 도구 호출은 조용히 실패하며, 컨텍스트 윈도우는 쓰레기로 가득 찹니다.
문제는 모델이 아닙니다. 모델 주변의 모든 것입니다.
LangChain은 LLM을 감싸는 인프라만 변경했을 때(동일한 모델, 동일한 가중치) TerminalBench 2.0에서 상위 30위 밖에서 5위로 도약하면서 이를 증명했습니다. 별도의 연구 프로젝트에서는 LLM이 인프라 자체를 최적화하도록 하여 76.4%의 통과율을 달성했으며, 이는 수동으로 설계된 시스템을 능가했습니다.
이제 이 인프라에는 이름이 있습니다: 에이전트 하네스입니다.
에이전트 하네스란 무엇인가?#
이 용어는 2026년 초에 공식화되었지만, 개념 자체는 훨씬 이전부터 존재했습니다. 하네스는 LLM을 감싸는 완전한 소프트웨어 인프라입니다: 오케스트레이션 루프, 도구, 메모리, 컨텍스트 관리, 상태 지속성, 오류 처리, 그리고 가드레일을 포함합니다. Anthropic의 Claude Code 문서는 SDK를 "Claude Code를 구동하는 에이전트 하네스"라고 간단히 설명합니다. OpenAI의 Codex 팀도 동일한 프레임워크를 사용하며, "에이전트"와 "하네스"라는 용어를 LLM을 유용하게 만드는 비모델 인프라를 지칭하는 것으로 명시적으로 동일시합니다.
LangChain의 Vivek Trivedy가 제시한 정식 공식이 마음에 들었습니다: "모델이 아니라면, 당신은 하네스입니다."
사람들을 혼란스럽게 하는 차이점은 다음과 같습니다. "에이전트"는 사용자가 상호작용하는 목표 지향적이고 도구를 사용하며 스스로 수정하는 개체인 창발적 행동입니다. 하네스는 그 행동을 생성하는 메커니즘입니다. 누군가 "에이전트를 만들었다"고 말할 때, 그들은 하네스를 만들고 그것을 모델에 연결했다는 의미입니다.

Beren Millidge는 2023년 에세이 "Scaffolded LLMs as Natural Language Computers"에서 이 비유를 정확하게 설명했습니다. 원시 LLM은 RAM, 디스크, I/O가 없는 CPU입니다. 컨텍스트 윈도우는 RAM(빠르지만 제한적) 역할을 합니다. 외부 데이터베이스는 디스크 저장소(크지만 느림) 역할을 합니다. 도구 통합은 장치 드라이버 역할을 합니다. 하네스는 운영 체제입니다. Millidge가 썼듯이: "우리는 폰 노이만 아키텍처를 재발명했습니다." 이는 모든 컴퓨팅 시스템에 자연스러운 추상화이기 때문입니다.
세 가지 엔지니어링 수준#
모델을 둘러싼 세 가지 동심원 수준의 엔지니어링이 있습니다:
- 프롬프트 엔지니어링은 모델이 수신하는 지침을 작성합니다.
- 컨텍스트 엔지니어링은 모델이 무엇을, 언제 보는지 관리합니다.
- 하네스 엔지니어링은 이 두 가지와 전체 애플리케이션 인프라(도구 오케스트레이션, 상태 지속성, 오류 복구, 검증 루프, 안전 강화, 수명 주기 관리)를 모두 포함합니다.
하네스는 프롬프트를 감싸는 래퍼가 아닙니다. 자율 에이전트 행동을 가능하게 하는 완전한 시스템입니다.
프로덕션 하네스의 12가지 구성 요소#
Anthropic, OpenAI, LangChain 및 더 넓은 실무자 커뮤니티의 내용을 종합하면, 프로덕션 에이전트 하네스는 12개의 개별 구성 요소로 구성됩니다. 각각을 살펴보겠습니다.

1. 오케스트레이션 루프#
이것은 심장박동입니다. Thought-Action-Observation(TAO) 사이클(ReAct 루프라고도 함)을 구현합니다. 루프는 다음과 같이 실행됩니다: 프롬프트 조합, LLM 호출, 출력 구문 분석, 모든 도구 호출 실행, 결과 피드백, 완료될 때까지 반복.
기계적으로는 종종 단순한 while 루프입니다. 복잡성은 루프 자체가 아니라 루프가 관리하는 모든 것에 있습니다. Anthropic은 런타임을 "멍청한 루프"로 설명하며, 모든 지능은 모델에 존재한다고 말합니다. 하네스는 단지 턴을 관리할 뿐입니다.
2. 도구#
도구는 에이전트의 손입니다. 이는 LLM의 컨텍스트에 주입되는 스키마(이름, 설명, 매개변수 유형)로 정의되어 모델이 무엇을 사용할 수 있는지 알 수 있게 합니다. 도구 계층은 등록, 스키마 검증, 인수 추출, 샌드박스 실행, 결과 캡처, 결과를 LLM이 읽을 수 있는 관찰로 다시 포맷하는 작업을 처리합니다.
Claude Code는 파일 작업, 검색, 실행, 웹 액세스, 코드 인텔리전스, 하위 에이전트 생성의 여섯 가지 범주에 걸쳐 도구를 제공합니다. OpenAI의 Agents SDK는 함수 도구(
@function_tool 사용), 호스팅 도구(WebSearch, CodeInterpreter, FileSearch), MCP 서버 도구를 지원합니다.3. 메모리#
메모리는 여러 시간 척도에서 작동합니다. 단기 메모리는 단일 세션 내의 대화 기록입니다. 장기 메모리는 세션 간에 지속됩니다: Anthropic은 CLAUDE.md 프로젝트 파일과 자동 생성된 MEMORY.md 파일을 사용합니다. LangGraph는 네임스페이스로 구성된 JSON 저장소를 사용합니다. OpenAI는 SQLite 또는 Redis로 백업되는 세션을 지원합니다.
Claude Code는 3계층 계층 구조를 구현합니다: 항상 로드되는 경량 인덱스(항목당 약 150자), 필요에 따라 가져오는 상세 주제 파일, 검색을 통해서만 액세스되는 원시 기록입니다. 중요한 설계 원칙: 에이전트는 자체 메모리를 "힌트"로 취급하고 행동하기 전에 실제 상태와 대조하여 확인합니다.
4. 컨텍스트 관리#
이것은 많은 에이전트가 조용히 실패하는 부분입니다. 핵심 문제는 컨텍스트 부패입니다. 주요 콘텐츠가 중간 윈도우 위치에 있을 때 모델 성능이 30% 이상 저하됩니다(Chroma 연구, Stanford의 "Lost in the Middle" 연구 결과와 일치). 백만 토큰 윈도우도 컨텍스트가 커짐에 따라 지침 준수 성능이 저하됩니다.
프로덕션 전략은 다음과 같습니다:
- 압축: 한계에 도달할 때 대화 기록 요약(Claude Code는 중복된 도구 출력을 버리면서 아키텍처 결정 및 해결되지 않은 버그를 보존)
- 관찰 마스킹: JetBrains의 Junie는 도구 호출을 표시하면서 오래된 도구 출력을 숨깁니다.
- 적시 검색: 경량 식별자를 유지하고 데이터를 동적으로 로드(Claude Code는 전체 파일을 로드하는 대신 grep, glob, head, tail 사용)
- 하위 에이전트 위임: 각 하위 에이전트는 광범위하게 탐색하지만 1,000~2,000 토큰의 압축된 요약만 반환합니다.
Anthropic의 컨텍스트 엔지니어링 가이드는 목표를 다음과 같이 명시합니다: 원하는 결과의 가능성을 최대화하는 가장 작은 고신호 토큰 집합을 찾는 것입니다.
5. 프롬프트 구성#
이것은 모델이 각 단계에서 실제로 보는 것을 조합합니다. 계층적입니다: 시스템 프롬프트, 도구 정의, 메모리 파일, 대화 기록, 현재 사용자 메시지.
OpenAI의 Codex는 엄격한 우선순위 스택을 사용합니다: 서버 제어 시스템 메시지(최우선), 도구 정의, 개발자 지침, 사용자 지침(계단식 AGENTS.md 파일, 32KiB 제한), 그 다음 대화 기록.
6. 출력 구문 분석#
최신 하네스는 기본 도구 호출에 의존합니다. 모델은 구문 분석해야 하는 자유 텍스트 대신 구조화된
tool_calls 객체를 반환합니다. 하네스는 확인합니다: 도구 호출이 있는가? 실행하고 루프를 반복합니다. 도구 호출이 없는가? 그것이 최종 답변입니다.구조화된 출력의 경우, OpenAI와 LangChain 모두 Pydantic 모델을 통한 스키마 제약 응답을 지원합니다. 원래 프롬프트, 실패한 완성, 구문 분석 오류를 모델에 다시 공급하는 RetryWithErrorOutputParser와 같은 레거시 접근 방식은 여전히 에지 케이스에 사용할 수 있습니다.
7. 상태 관리#
LangGraph는 상태를 그래프 노드를 통해 흐르는 타입이 지정된 딕셔너리로 모델링하며, 리듀서가 업데이트를 병합합니다. 체크포인팅은 슈퍼-스텝 경계에서 발생하여 중단 후 재개 및 시간 여행 디버깅을 가능하게 합니다. OpenAI는 상호 배타적인 네 가지 전략을 제공합니다: 애플리케이션 메모리, SDK 세션, 서버 측 Conversations API, 또는 경량화된
previous_response_id 체이닝입니다. Claude Code는 다른 접근 방식을 취합니다: git 커밋을 체크포인트로, 진행 파일을 구조화된 스크래치패드로 사용합니다.8. 오류 처리#
이것이 중요한 이유는 다음과 같습니다: 각 단계의 성공률이 99%인 10단계 프로세스라도 종단 간 성공률은 약 90.4%에 불과합니다. 오류는 빠르게 누적됩니다.
LangGraph는 네 가지 오류 유형을 구분합니다: 일시적(백오프와 함께 재시도), LLM-복구 가능(오류를 ToolMessage로 반환하여 모델이 조정할 수 있도록 함), 사용자-수정 가능(인간의 입력을 위해 중단), 예상치 못한(디버깅을 위해 상위로 전파). Anthropic은 도구 핸들러 내에서 실패를 포착하여 오류 결과로 반환함으로써 루프를 계속 실행합니다. Stripe의 프로덕션 하네스는 재시도 횟수를 2회로 제한합니다.
9. 가드레일 및 안전#
OpenAI의 SDK는 세 가지 수준을 구현합니다: 입력 가드레일(첫 번째 에이전트에서 실행), 출력 가드레일(최종 출력에서 실행), 도구 가드레일(모든 도구 호출 시 실행). "트립와이어" 메커니즘은 트리거될 때 에이전트를 즉시 중단시킵니다.
Anthropic은 권한 적용을 모델 추론과 아키텍처적으로 분리합니다. 모델은 무엇을 시도할지 결정하고, 도구 시스템은 무엇이 허용되는지 결정합니다. Claude Code는 약 40개의 개별 도구 기능을 독립적으로 게이트하며, 세 단계로 구성됩니다: 프로젝트 로드 시 신뢰 설정, 각 도구 호출 전 권한 확인, 고위험 작업에 대한 명시적 사용자 확인.
10. 검증 루프#
이것이 장난감 데모와 프로덕션 에이전트를 구분 짓는 요소입니다. Anthropic은 세 가지 접근 방식을 권장합니다: 규칙 기반 피드백(테스트, 린터, 타입 검사기), 시각적 피드백(UI 작업을 위한 Playwright 스크린샷), LLM-as-judge(별도의 하위 에이전트가 출력 평가).
Claude Code의 창시자인 Boris Cherny는 모델에게 작업을 검증할 방법을 제공하면 품질이 2~3배 향상된다고 언급했습니다.
11. 하위 에이전트 오케스트레이션#
Claude Code는 세 가지 실행 모델을 지원합니다: Fork(부모 컨텍스트의 바이트 단위 동일 복사본), Teammate(파일 기반 메일박스 통신을 사용하는 별도 터미널 창), Worktree(자체 git 워크트리, 에이전트당 격리된 브랜치). OpenAI의 SDK는 agents-as-tools(전문가가 제한된 하위 작업 처리)와 handoffs(전문가가 전체 제어권 획득)를 지원합니다. LangGraph는 하위 에이전트를 중첩된 상태 그래프로 구현합니다.
작동 중인 루프: 단계별 분석#
이제 구성 요소를 알았으니, 단일 사이클에서 이들이 어떻게 함께 작동하는지 추적해 보겠습니다.
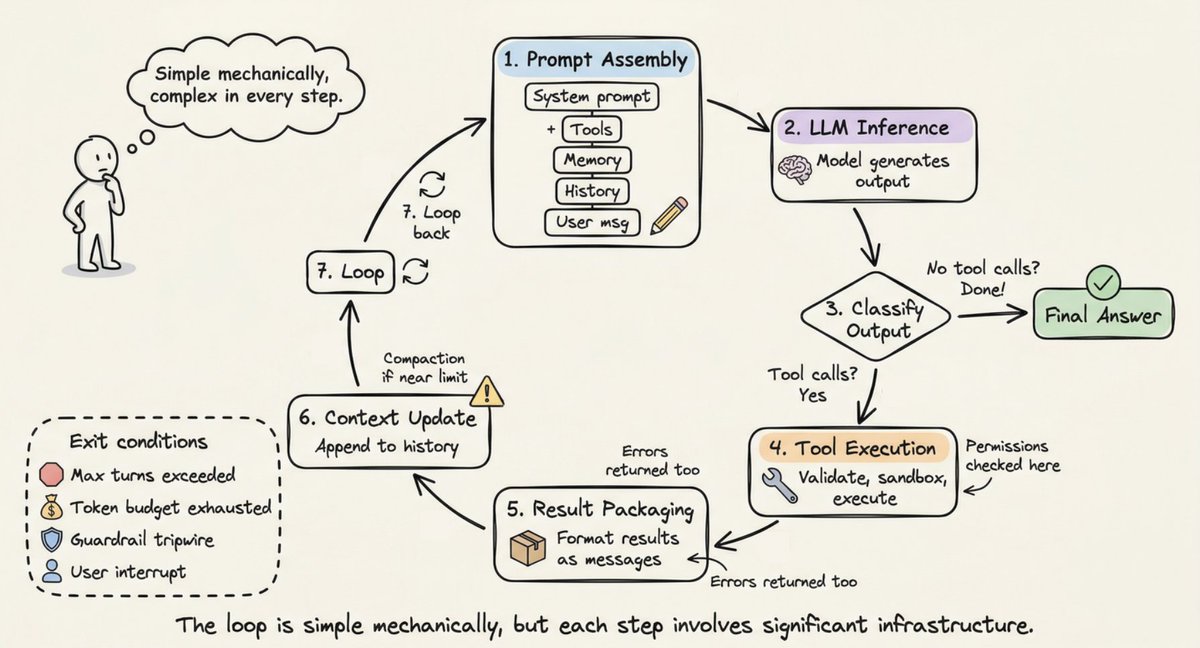
1단계 (프롬프트 조립): 하네스는 전체 입력을 구성합니다: 시스템 프롬프트 + 도구 스키마 + 메모리 파일 + 대화 기록 + 현재 사용자 메시지. 중요한 컨텍스트는 프롬프트의 시작과 끝에 배치됩니다("Lost in the Middle" 연구 결과).
2단계 (LLM 추론): 조립된 프롬프트가 모델 API로 전송됩니다. 모델은 출력 토큰(텍스트, 도구 호출 요청, 또는 둘 다)을 생성합니다.
3단계 (출력 분류): 모델이 도구 호출 없이 텍스트만 생성했다면 루프가 종료됩니다. 도구 호출을 요청했다면 실행 단계로 진행합니다. 핸드오프가 요청되었다면 현재 에이전트를 업데이트하고 재시작합니다.
4단계 (도구 실행): 각 도구 호출에 대해 하네스는 인수를 검증하고, 권한을 확인하며, 샌드박스 환경에서 실행하고, 결과를 캡처합니다. 읽기 전용 작업은 동시에 실행될 수 있고, 변경 작업은 직렬로 실행됩니다.
5단계 (결과 패키징): 도구 결과는 LLM이 읽을 수 있는 메시지로 형식화됩니다. 오류는 포착되어 오류 결과로 반환되어 모델이 스스로 수정할 수 있도록 합니다.
6단계 (컨텍스트 업데이트): 결과가 대화 기록에 추가됩니다. 컨텍스트 창 한도에 가까워지면 하네스가 압축을 트리거합니다.
7단계 (루프): 1단계로 돌아갑니다. 종료 조건이 충족될 때까지 반복합니다.
종료 조건은 계층적으로 적용됩니다: 모델이 도구 호출 없이 응답을 생성, 최대 턴 수 초과, 토큰 예산 소진, 가드레일 트립와이어 작동, 사용자 중단, 또는 안전 거부 반환. 간단한 질문은 1~2턴이 소요될 수 있습니다. 복잡한 리팩토링 작업은 여러 턴에 걸쳐 수십 개의 도구 호출을 연결할 수 있습니다.
여러 컨텍스트 윈도우에 걸친 장기 실행 작업을 위해 Anthropic은 2단계 "Ralph Loop" 패턴을 개발했습니다: Initializer Agent가 환경을 설정하고(초기화 스크립트, 진행 파일, 기능 목록, 초기 git 커밋), 이후 모든 세션에서 Coding Agent가 git 로그와 진행 파일을 읽어 방향을 파악하고, 우선순위가 가장 높은 미완료 기능을 선택하여 작업하고, 커밋하고, 요약을 작성합니다. 파일 시스템이 컨텍스트 윈도우 간 연속성을 제공합니다.
실제 프레임워크가 패턴을 구현하는 방법#
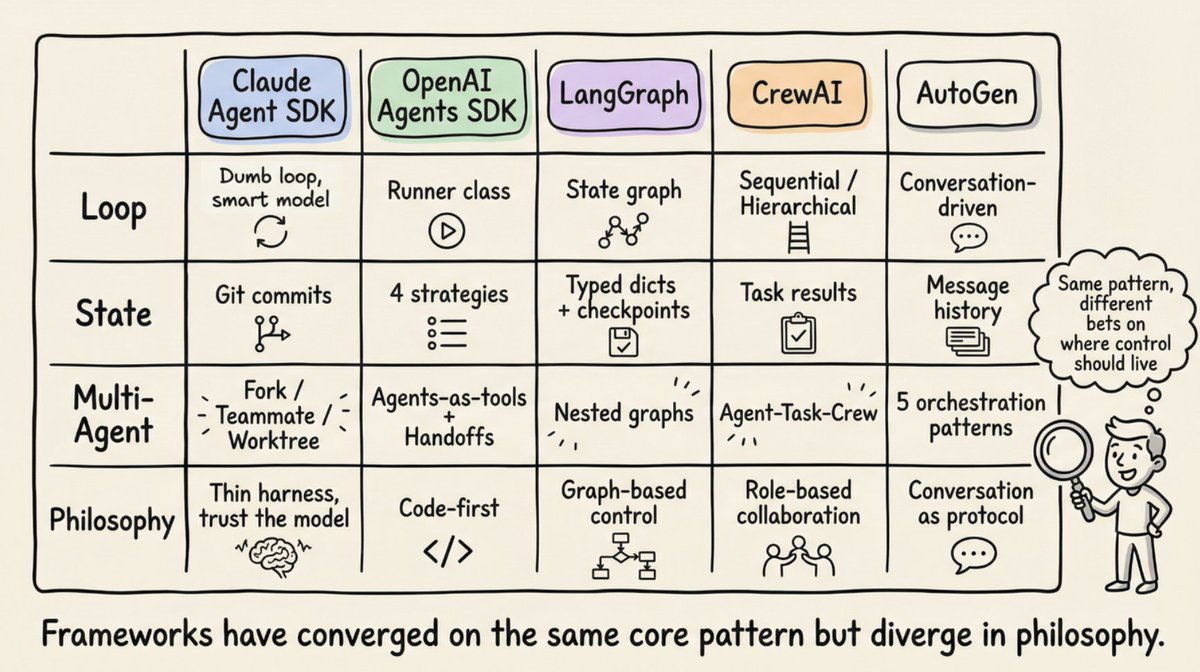
Anthropic의 Claude Agent SDK는 단일
query() 함수를 통해 하네스를 노출하며, 이 함수는 에이전틱 루프를 생성하고 메시지를 스트리밍하는 비동기 반복자를 반환합니다. 런타임은 "멍청한 루프"입니다. 모든 지능은 모델에 있습니다. Claude Code는 Gather-Act-Verify 주기를 사용합니다: 컨텍스트 수집(파일 검색, 코드 읽기), 조치 실행(파일 편집, 명령 실행), 결과 검증(테스트 실행, 출력 확인), 반복.OpenAI의 Agents SDK는
Runner 클래스를 통해 하네스를 구현하며, 세 가지 모드(비동기, 동기, 스트리밍)를 제공합니다. SDK는 "코드 우선" 방식입니다: 워크플로 로직은 그래프 DSL이 아닌 네이티브 Python으로 표현됩니다. Codex 하네스는 이를 3계층 아키텍처로 확장합니다: Codex Core(에이전트 코드 + 런타임), App Server(양방향 JSON-RPC API), 클라이언트 표면(CLI, VS Code, 웹 앱). 모든 표면이 동일한 하네스를 공유하기 때문에 "Codex 모델이 일반 채팅 창보다 Codex 표면에서 더 좋게 느껴집니다."LangGraph는 하네스를 명시적 상태 그래프로 모델링합니다. 두 개의 노드(
llm_call과 tool_node)가 조건부 엣지로 연결됩니다: 도구 호출이 있으면 tool_node로 라우팅하고, 없으면 END로 라우팅합니다. LangGraph는 LangChain의 AgentExecutor에서 발전했으며, AgentExecutor는 확장이 어렵고 다중 에이전트 지원이 부족하여 v0.2에서 폐기되었습니다. LangChain의 Deep Agents는 "에이전트 하네스"라는 용어를 명시적으로 사용합니다: 내장 도구, 계획(write_todos 도구), 컨텍스트 관리를 위한 파일 시스템, 하위 에이전트 생성, 영구 메모리.CrewAI는 역할 기반 다중 에이전트 아키텍처를 구현합니다: Agent(역할, 목표, 배경 스토리, 도구로 정의된 LLM 주변의 하네스), Task(작업 단위), Crew(에이전트 컬렉션). CrewAI의 Flows 레이어는 "중요한 곳에 지능을 둔 결정론적 백본"을 추가하여, Crews가 자율적으로 협업하는 동안 라우팅과 검증을 관리합니다.
AutoGen(Microsoft Agent Framework로 진화 중)은 대화 기반 오케스트레이션을 개척했습니다. 3계층 아키텍처(Core, AgentChat, Extensions)는 다섯 가지 오케스트레이션 패턴을 지원합니다: 순차적, 동시적(fan-out/fan-in), 그룹 채팅, 핸드오프, magentic(관리자 에이전트가 동적 작업 원장을 유지하며 전문가를 조정).
비계(Scaffolding) 은유#
비계 은유는 단순한 장식이 아닙니다. 정확한 표현입니다. 건설 현장의 비계는 작업자가 다른 방법으로는 도달할 수 없는 구조물을 짓기 위한 임시 인프라입니다. 비계가 직접 건설을 하는 것은 아닙니다. 하지만 비계 없이는 작업자가 위층에 도달할 수 없습니다.

핵심 통찰: 건물이 완성되면 비계는 제거됩니다. 모델이 개선됨에 따라 하네스의 복잡성은 줄어들어야 합니다. Manus는 6개월 동안 5번 재구축되었으며, 각 재작성 시마다 복잡성이 제거되었습니다. 복잡한 도구 정의는 일반적인 셸 실행으로 바뀌었습니다. "관리 에이전트"는 단순한 구조화된 핸드오프가 되었습니다.
이는 공진화 원칙을 가리킵니다: 모델은 이제 특정 하네스를 루프에 포함시켜 사후 훈련됩니다. Claude Code의 모델은 훈련에 사용된 특정 하네스를 사용하는 방법을 학습했습니다. 이러한 긴밀한 결합 때문에 도구 구현을 변경하면 성능이 저하될 수 있습니다.
하네스 설계의 "미래 대비 테스트": 하네스 복잡성을 추가하지 않고 더 강력한 모델로 성능이 확장된다면 설계가 건전한 것입니다.

모든 하네스를 정의하는 일곱 가지 결정#
모든 하네스 설계자는 일곱 가지 선택에 직면합니다:

- 단일 에이전트 vs. 다중 에이전트. Anthropic과 OpenAI 모두 다음과 같이 말합니다: 먼저 단일 에이전트를 최대화하세요. 다중 에이전트 시스템은 오버헤드를 추가합니다(라우팅을 위한 추가 LLM 호출, 핸드오프 중 컨텍스트 손실). 도구 오버로드가 약 10개의 중복 도구를 초과하거나 명확히 분리된 작업 영역이 존재할 때만 분할하세요.
- ReAct vs. 계획-후-실행. ReAct는 모든 단계에서 추론과 행동을 번갈아 수행합니다(유연하지만 단계당 비용이 높음). 계획-후-실행은 계획과 실행을 분리합니다. LLMCompiler는 순차적 ReAct보다 3.6배 속도 향상을 보고했습니다.
- 컨텍스트 윈도우 관리 전략. 다섯 가지 프로덕션 접근 방식: 시간 기반 지우기, 대화 요약, 관찰 마스킹, 구조화된 메모 작성, 하위 에이전트 위임. ACON 연구는 원시 도구 출력보다 추론 흔적을 우선시하여 95%+ 정확도를 유지하면서 26~54%의 토큰 감소를 보여주었습니다.
- 검증 루프 설계. 계산적 검증(테스트, 린터)은 결정론적 근거를 제공합니다. 추론적 검증(LLM-as-judge)은 의미론적 문제를 잡아내지만 지연 시간을 추가합니다. Martin Fowler의 Thoughtworks 팀은 이를 가이드(사전 피드백, 행동 전 조종) 대 센서(사후 피드백, 행동 후 관찰)로 구분합니다.
- 권한 및 안전 아키텍처. 허용적(빠르지만 위험, 대부분의 행동 자동 승인) 대 제한적(안전하지만 느림, 각 행동에 승인 필요). 선택은 배포 컨텍스트에 따라 달라집니다.
- 도구 범위 지정 전략. 도구가 많을수록 성능이 나빠지는 경우가 많습니다. Vercel은 v0에서 도구의 80%를 제거하고 더 나은 결과를 얻었습니다. Claude Code는 지연 로딩을 통해 95%의 컨텍스트 감소를 달성합니다. 원칙: 현재 단계에 필요한 최소 도구 세트를 노출하세요.
- 하네스 두께. 얼마나 많은 로직이 하네스 대신 모델에 있는지. Anthropic은 얇은 하네스와 모델 개선에 베팅합니다. 그래프 기반 프레임워크는 명시적 제어에 베팅합니다. Anthropic은 새로운 모델 버전이 해당 기능을 내재화함에 따라 Claude Code의 하네스에서 계획 단계를 정기적으로 삭제합니다.
하네스가 곧 제품입니다#
동일한 모델을 사용하는 두 제품은 하네스 설계만으로도 성능이 크게 달라질 수 있습니다. TerminalBench 증거는 명확합니다: 하네스만 변경해도 에이전트의 순위가 20단계 이상 움직였습니다.
하네스는 해결된 문제나 상품화된 계층이 아닙니다. 진정한 엔지니어링이 존재하는 곳입니다: 희소 자원인 컨텍스트 관리, 오류가 누적되기 전에 잡아내는 검증 루프 설계, 환각 없이 연속성을 제공하는 메모리 시스템 구축, 그리고 얼마나 많은 스캐폴딩을 구축할지 대 모델에 맡길지에 대한 아키텍처적 베팅.
모델이 개선됨에 따라 현장은 더 얇은 하네스로 나아가고 있습니다. 하지만 하네스 자체가 사라지지는 않습니다. 가장 유능한 모델조차도 컨텍스트 윈도우를 관리하고, 도구 호출을 실행하고, 상태를 유지하고, 작업을 검증할 무언가가 필요합니다.
다음에 에이전트가 실패할 때, 모델을 탓하지 마세요. 하네스를 살펴보세요.
이상입니다!
재미있게 읽으셨다면:
저를 찾아보세요 → @akshay_pachaar ✔️
매일 AI, 머신러닝, 그리고 바이브 코딩 모범 사례에 대한 튜토리얼과 인사이트를 공유합니다.