Beginner
+29k Stars, No Vectors: How PageIndex Replaces Embeddings With LLM Reasoning
+29k Stars, No Vectors: How PageIndex Replaces Embeddings With LLM Reasoning
VectifyAI's tree-based RAG hits 98.7% on FinanceBench. The MCTS the docs mention isn't in the open-source code.#
PageIndex is a vectorless RAG framework that builds a hierarchical tree from a document and lets the LLM reason which pages answer a query.
VectifyAI open-sourced it on April 1, 2025. The repo has crossed +29k GitHub stars and hit #1 of the day on GitHub Trending.
Mafin 2.5, a financial-QA system built on top of PageIndex, hit 98.7% on FinanceBench's full 10,231-question set, with the eval code public in a separate repo. Evidence down below.
Repo Snapshot#

Why this matters#
Vector RAG retrieves text that looks like the query, not text that answers it. The cosine-similarity match between an embedded chunk and an embedded question is a syntactic neighbor, not a semantic answer.
The gap shows up where developers most need RAG to work: 600-page 10-Ks, multi-thousand-page compliance binders, dense technical specs. PageIndex flips the framing. The document gets a structural tree, the LLM picks which nodes to read, and the answer comes from reasoning over structure rather than nearest-neighbor recall.
Context#
VectifyAI, founded by Mingtian Zhang and Yu Tang, released PageIndex on April 1, 2025. Thirteen months later, the repo has +29k stars, 2,476 forks, 138 open issues, 11 contributors, and a #1-of-the-day spot on GitHub Trending. Two of those contributors, rejojer and zmtomorrow, account for 89.3% of the 281 total commits.
The license is MIT. The package is 2,579 lines of Python across six files in the pageindex/ directory.
How PageIndex works#
The pipeline runs in two phases.

Phase 1: Tree index construction.
PyPDF2 (default) or PyMuPDF parses the PDF into per-page text. An LLM scans the first 20 pages to detect a table of contents. Three processing modes branch from there: TOC with page numbers, TOC without page numbers, or no TOC at all.
The system runs verify_toc() with LLM-based fuzzy title matching on every TOC item against its assigned physical page. fix_incorrect_toc_with_retries() reattempts mismatched items up to 3 times. If accuracy stays below 60%, the system falls back to the next processing mode. Nodes spanning more than 10 pages AND 20,000 tokens are recursively split using the same LLM-based extraction.
Phase 2: Reasoning-based retrieval.
The retrieval module exposes three tool functions for an agent runtime: get_document() for metadata, get_document_structure() for the tree minus text content, and get_page_content() for specific pages.
The LLM receives the tree, picks node IDs in a JSON response, the system fetches text for those nodes, and the LLM writes the final answer. A node looks like this:
{
"title": "Financial Stability",
"node_id": "0006",
"start_index": 21,
"end_index": 22,
"summary": "The Federal Reserve...",
"nodes": [
{
"title": "Monitoring Financial Vulnerabilities",
"node_id": "0007",
"start_index": 22,
"end_index": 28,
"summary": "..."
}
]
}One thing the docs reference but the open-source code does not implement: MCTS.
The tree-search tutorial states that the cloud dashboard and retrieval API use "a combination of LLM tree search and value function-based Monte Carlo Tree Search (MCTS)." The open-source code ships only the LLM-prompt tree-search variant. MCTS lives in the hosted service.
How to get started#
Five steps from clone to a working agentic retrieval demo.
- Clone and install.
git clone https://github.com/VectifyAI/PageIndex.git
cd PageIndex
pip3 install --upgrade -r requirements.txt-
Set the API key. Create a .env file in the project root with OPENAI_API_KEY=your_key. CHATGPT_API_KEY is supported as a backward-compatible alias.
-
Generate a tree from a PDF.
python3 run_pageindex.py --pdf_path /path/to/document.pdfThe output JSON lands in ./results/_structure.json. Default model is gpt-4o-2024-11-20, overridable with --model.
- Run the agentic RAG demo. This is the load-bearing example for understanding why a tree-only retrieval format earns its keep.
pip3 install openai-agents
python3 examples/agentic_vectorless_rag_demo.pyThe demo downloads an arXiv PDF, indexes it through PageIndexClient with workspace persistence, creates an OpenAI Agent wired to the three retrieval tools, then streams the agent's reasoning and tool calls as it answers a question.
- Optional: programmatic API.
from pageindex import PageIndexClient
client = PageIndexClient(workspace="./workspace")
doc_id = client.index("document.pdf")
structure = client.get_document_structure(doc_id)
content = client.get_page_content(doc_id, "5-7")Evidence: 98.7% on FinanceBench#
Mafin 2.5, VectifyAI's PageIndex-powered financial-QA system, reports 98.7% accuracy on the full 10,231-question FinanceBench benchmark (arXiv:2311.11944). The eval code (eval.py) and raw results JSON are public in the VectifyAI/Mafin2.5-FinanceBench repo. The 98.7% figure holds across two base LLMs, GPT-4o and DeepSeek v3.
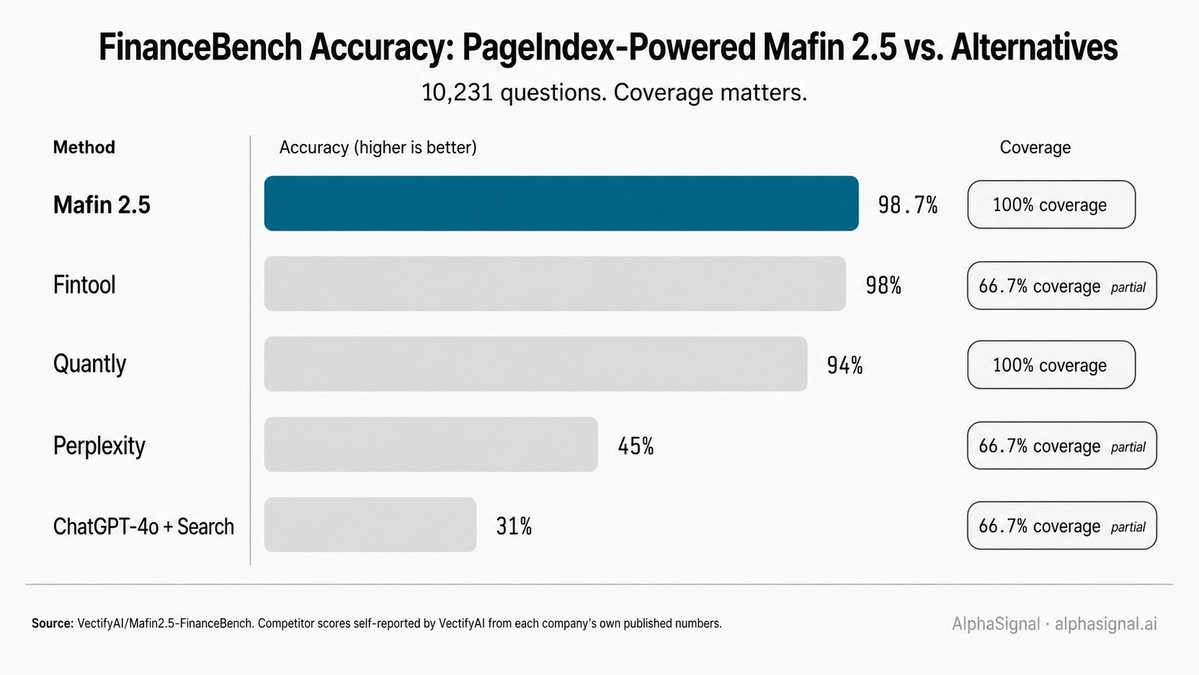
A reading note. VectifyAI self-reports the comparison table. Competitor scores are pulled from those companies' own published numbers, not independently re-run. The coverage column matters: three of the comparators only ran 66.7% of the benchmark, while Mafin 2.5 covered 100%.
PageIndex vs. vector RAG vs. long-context LLMs#
PageIndex is a framework, not a model, so it does not slot into a leaderboard. The architectural comparison that does matter:

Also, a vectorless RAG example with self-hosted PageIndex, using OpenAI Agents SDK.
PageIndex's win condition is the long-and-structured corner. The document has a TOC or hierarchical headings, the answer lives in a specific section, and a vector store would surface neighbors that look like the query but skip the section that contains the answer.
Current Limitations#
MCTS retrieval is cloud-only.
The README and tutorials reference a value-function MCTS retrieval layer. The open-source code ships only the LLM-prompt tree-search variant. Practitioners pulling the repo expecting the same retrieval depth as the cloud service will be working with a thinner version.
OSS PDF parsing has no OCR.
Standard PyPDF2 and PyMuPDF are the only parsers shipped. Scanned PDFs, image-only documents, and noisy financial filings need pre-processing or the cloud OCR service.
Self-host stability ceilings.
The TOC verification loop is capped at 3 fix attempts (fix_incorrect_toc_with_retries in pageindex/page_index.py). If accuracy stays at or below 60% after all three processing modes, the system raises a Processing failed exception. The README's only stability hedge is the line "for use cases with complex PDFs, our Cloud Service offers enhanced OCR, tree building, and retrieval." Real-world PDFs with unusual layouts can land in the failure path.
No SECURITY.md, six open security issues.
The repo has no documented security policy. Six open issues request one (#85, #240) or report findings (#79, #80, #81, #174). The LiteLLM supply-chain incident is patched: requirements.txt pins litellm==1.83.7, above the compromised threshold.
AlphaSignal Take#
Verdict: Worth Watching.
PageIndex does what the README's headline promise claims for tree construction. The retrieval story is partial: the open-source code gives developers the prompts and the three tool functions, but the MCTS layer that the docs name as part of the system is not in the public code.
Maintenance health is mixed. Eleven contributors with 89.3% of commits coming from two people, 138 open issues (including a stability fix request, #188, with 36 comments), and no SECURITY.md.
The verdict moves to Production Ready when four things land: MCTS in the open-source path, a SECURITY.md plus an external audit, a published latency benchmark from the team itself, and OCR in the open-source parser.
Until then, the framework's structural-doc accuracy is good enough to test on a real workload, but not yet good enough to bet a production system on. Watch for PageIndex 2.0 or an MCTS-OSS release as the trigger.
Who benefits and who doesn't#
Benefits: ML and backend engineers building QA over long structured documents (10-Ks, compliance binders, contracts, technical manuals), teams hitting recall ceilings on vector RAG over long docs, and teams already paying for frontier-model API calls who can trade query latency for retrieval accuracy.
Doesn't fit: latency-sensitive real-time chat over short documents, teams without LLM API budgets at retrieval scale, scanned-document workflows that need OCR, and production deployments where an undocumented security posture is a blocker.
Practitioner Implication#
You can now answer questions over a 600-page 10-K without embedding a single vector, now that PageIndex's tree-reasoning approach has hit 98.7% on FinanceBench's full 10,231-question set.
Links#
- PageIndex repo (+29k stars, MIT, ~5 min setup)
- Agentic RAG demo (OpenAI Agents SDK integration)
- Mafin2.5-FinanceBench eval repo (public eval code and raw results)
- pageindex-mcp (MCP server)
- PageIndex framework intro (official deep dive)
Follow @AlphaSignalAI for more content like this.
Subscribe at AlphaSignal.ai for daily AI signals. Read by 280,000+ developers.
Questions?#
Q: What is PageIndex?
A vectorless tree-based RAG framework by VectifyAI. It builds a hierarchical tree from a document and lets the LLM reason which nodes contain the answer, with no embeddings or vector store in the loop.
Q: How is PageIndex different from vector RAG?
Vector RAG retrieves chunks by embedding similarity, which optimizes for syntactic neighbors. PageIndex skips embeddings entirely, relying on LLM reasoning over a structural tree to pick the sections most likely to answer the query.
Q: What benchmark has PageIndex hit?
Mafin 2.5, built on PageIndex, reports 98.7% on FinanceBench's full 10,231-question set, per VectifyAI's public eval repo. The figure holds across both GPT-4o and DeepSeek v3 base LLMs.
Q: Can I self-host PageIndex?
Yes. The repo is MIT-licensed. git clone plus pip3 install -r requirements.txt plus an OpenAI API key in .env is the full path. OCR for scanned PDFs is cloud-only.
Q: Is PageIndex production-ready?
Worth watching, not yet production-grade. The README flags early beta. There is no SECURITY.md, and the MCTS retrieval layer the docs reference is not in the open-source code.