Beginner
Deep Dive: The Anatomy of an AI Agent Harness
Deep Dive: The Anatomy of an AI Agent Harness
Quoted tweet https://t.co/VoQByJUrBU https://x.com/i/web/status/2041146899319971922
Author: @akshay_pachaar
This article delves into what Anthropic, OpenAI, Perplexity, and LangChain are actually building. We'll talk about orchestration loops, tools, memory, context management, and the underlying mechanisms that transform a "stateless" Large Language Model (LLM) into a capable Agent.
You've probably built a chatbot before, maybe even set up a ReAct loop (ReAct: Reason + Act, a pattern where the model reasons before acting) with some tools. It looks great in a demo, but once it hits production, the system starts to fall apart: the model forgets what it did three steps ago, tool calls fail silently, and the context window fills with meaningless garbage.
The problem isn't the model itself; it's the infrastructure surrounding the model.
LangChain proved this: by simply changing the underlying architecture wrapping the LLM — with the same model and the same parameters — they catapulted their system from outside the top 30 to 5th place on TerminalBench 2.0 (a benchmark for measuring an AI agent's ability to handle command-line tasks). Another study had an LLM optimize this very architecture, achieving a 76.4% pass rate, surpassing even human-designed systems.
This infrastructure now has a formal name: the AI Agent Harness.
While the term was formalized in early 2026, the core concept has existed for a while. The Harness is the complete software architecture wrapped around the LLM: it includes the orchestration loop, tools, memory, context management, state persistence, error handling, and guardrails. Anthropic, in its Claude Code documentation, states it plainly: the SDK is "the Agent Harness that powers Claude Code." OpenAI's Codex team uses the same language, explicitly equating "Agent" and "Harness" to refer to the non-model architecture that makes the LLM truly useful.
I really like the definition formula from LangChain's Vivek Trivedy: "If you are not the model, you are the Harness."
There's a common point of confusion here: the "AI Agent" is the behavioral manifestation perceived by the user — an entity with goals that uses tools and self-corrects. The "Harness" is the underlying machinery that produces this behavior. When someone says, "I built an agent," what they really mean is, "I built a Harness and connected it to a model."
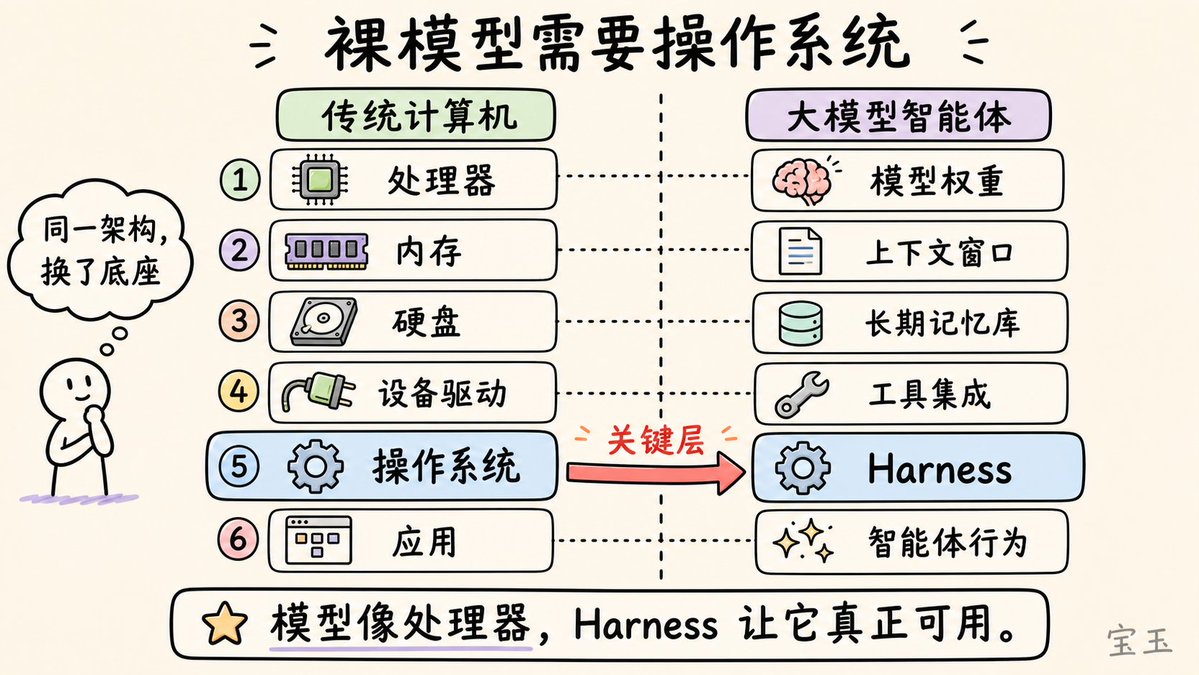
Beren Millidge made a precise analogy in his 2023 blog post: a native LLM is like a CPU without memory, a hard drive, or input/output devices. Here, the context window acts as RAM (fast but limited), external databases serve as the hard drive (large but slow), and tool integrations are device drivers. The Harness is the operating system. As Millidge wrote, "We have reinvented the Von Neumann architecture," because it's the most natural abstraction for any computing system.
Engineering around the model can be visualized as three concentric layers:
- Prompt Engineering: Carefully crafting the instructions the model receives.
- Context Engineering: Managing what the model sees and when it sees it.
- Harness Engineering: Encompasses both of the above, plus the entire application architecture: tool orchestration, state persistence, error recovery, verification loops, safe execution, and lifecycle management.
The Harness is not just an AI Wrapper around a prompt; it's the complete system that enables the agent to act autonomously.
Synthesizing practical experience from Anthropic, OpenAI, LangChain, and the broader community, a production-grade Agent Harness consists of 12 distinct components. Let's break them down one by one.

1. The Orchestration Loop#
This is the "heart" of the system. It implements the Thought-Action-Observation (TAO) loop, also known as the ReAct loop. This loop runs continuously: assemble prompt -> call LLM -> parse output -> execute tool call -> feed back result -> repeat, until the task is complete.
Technically, it's often just a
while loop. But the complexity lies not in the loop itself, but in the various states and logic it must handle. Anthropic describes their runtime as a "dumb loop," where all the intelligence resides in the model, and the Harness simply manages the turn-taking.2. Tools#
Tools are the agent's "hands." They are defined as a structured schema (name, description, parameter types) and injected into the model's context so the model knows which tools are available. The tool layer handles registration, format validation, parameter extraction, execution within a Sandbox environment, result capture, and finally formatting the result into a model-readable "observation."
Claude Code offers six major tool categories: file operations, search, execution, web access, code analysis, and sub-agent creation. OpenAI's Agents SDK supports function tools (defined via
@function_tool), hosted tools (like web search, code interpreter, file search), and MCP (Model Context Protocol, an open standard for tool integration) server tools.3. Memory#
Memory operates on different timescales. Short-term memory is the conversation history within a single session. Long-term memory persists across multiple sessions: Anthropic uses project files and auto-generated
memory.md files; LangGraph uses JSON stores organized by namespace; OpenAI supports session stores backed by SQLite or Redis.Claude Code implements a three-tier memory architecture: a lightweight index (about 150 characters per entry, always loaded), detailed topic files loaded on demand, and raw conversation logs accessible only via search. A core design principle is that the agent treats its own memory as a "prompt" and must verify it against the actual state before acting.
4. Context Management#
This is where many agents silently fail. The core problem is context decay: model performance drops by over 30% when critical information is in the middle of the window (the "Lost in the Middle" phenomenon discovered by Stanford). Even with million-token (Token: the smallest unit of text a model processes, roughly equivalent to a word or part of a character) windows, instruction-following ability degrades as context grows.
Production strategies include:
- Compaction: Summarizing conversation history when approaching limits (Claude Code retains architectural decisions and unfixed bugs while discarding redundant tool outputs).
- Observation masking: Hiding old tool outputs but retaining records of tool calls.
- Just-in-time retrieval: Keeping only lightweight identifiers and loading data dynamically (Claude Code prefers
greporheadcommands over loading entire files). - Sub-agent delegation: Letting each sub-agent perform deep exploration but only returning a condensed summary of 1000 to 2000 Tokens.
Anthropic's context engineering guide states the goal is: find the smallest set of Tokens with the strongest signal that maximizes the probability of achieving the goal.
5. Prompt Construction#
This determines exactly what the model sees at each step. It is hierarchical: system prompt, tool definitions, memory files, conversation history, and the current user message.
OpenAI's Codex uses a strict priority stack: server-controlled system message (highest priority), tool definitions, developer instructions, user instructions, and finally conversation history.
6. Output Parsing#
Modern Harnesses rely on native tool calling, where the model returns structured
tool_calls objects instead of free text that requires laborious parsing. The Harness checks: Is there a tool call? If yes, execute it and continue the loop. If no, the current output is the final answer.For structured output, both OpenAI and LangChain support schema constraints via Pydantic models (a Python library for data validation and formatting).
7. State Management#
LangGraph models state as typed dictionaries flowing through graph nodes. The system performs "Checkpointing" at key steps, allowing recovery from interruptions and even "time travel" debugging. OpenAI offers four strategies: in-memory, SDK sessions, server-side API, or lightweight response ID chains. Claude Code takes a different approach: using Git commits as checkpoints and progress files as structured scratchpads.
8. Error Handling#
Why is this important? A process with 10 steps, even with a 99% success rate per step, has a final success rate of only about 90.4%. Errors snowball.
LangGraph categorizes errors into four types: transient (retry with delay), model-recoverable (return the error as a tool message for the model to adjust), user-fixable (pause for human intervention), and unexpected errors (escalate for debugging).
9. Guardrails and Safety#
OpenAI's SDK implements three levels: input guardrails (checked on the first agent run), output guardrails (checking the final result), and tool guardrails (checked before every tool call). Once a "Tripwire" mechanism is triggered, the agent stops immediately.
Anthropic architecturally separates "permission execution" from "model reasoning." The model decides what it wants to do, but the Harness decides what it is allowed to do.
10. Verification Loops#
This is the key differentiator between a "toy demo" and a "production-grade agent." Anthropic recommends three methods: rule-based feedback (tests, linting), visual feedback (taking UI screenshots via Playwright), and LLM-as-judge (having another sub-agent evaluate the output).
Claude Code's creator, Boris Cherny, notes that enabling the model to verify its own work improves output quality by 2 to 3 times.
11. Subagent Orchestration#
Claude Code supports three modes: Fork (duplicates parent context), Teammate (independent window communicating via a file-based mailbox), and Worktree (independent Git branch). OpenAI supports agents as tools (experts handling specific sub-tasks) or handoffs (expert takes over subsequent control).
Now that we understand the components, let's see how they work together in a single loop.

- Step 1 (Prompt Assembly): The Harness builds the complete input.
- Step 2 (Model Inference): The assembled content is sent to the model API. The model generates Tokens: either text or a tool call request.
- Step 3 (Output Classification): If there is no tool call, the loop ends. If there is one, proceed to execution.
- Step 4 (Tool Execution): The Harness validates parameters, checks permissions, runs the tool in a sandbox, and captures the result.
- Step 5 (Result Packaging): Formats the result into a model-readable message, capturing errors to allow the model to self-heal.
- Step 6 (Context Update): Appends the result to the history, triggering compaction if necessary.
- Step 7 (Loop): Returns to Step 1 until the exit condition is met.

- Anthropic (Claude Agent SDK): Exposes the Harness via a simple
query()function. The runtime is a "dumb loop"; all intelligence is in the model. - OpenAI (Agents SDK): Adopts a "code-first" strategy. Workflow logic is expressed directly in Python, not complex graph languages.
- LangGraph: Models the Harness as an explicit state graph, emphasizing fine-grained control over the process.
- CrewAI: Implements role-based multi-agent collaboration, managed by a "process layer" that handles deterministic backbone logic.
- AutoGen: Developed by Microsoft, supports multiple orchestration patterns like sequential execution, group chat, handoffs, and dynamic task management.
The "scaffolding" metaphor is not decorative; it's incredibly precise. Construction scaffolding is temporary infrastructure that allows workers to reach heights they otherwise couldn't. The scaffolding itself doesn't build the house, but without it, workers can't get to the upper floors.

The key insight is: once the house is built, the scaffolding is removed. As model capabilities improve, the complexity of the Harness should decrease.
This is the co-evolution principle: current models are already trained with the existence of a Harness in mind. If your Harness is well-designed, you won't need to add complexity when the model upgrades; performance will automatically improve.
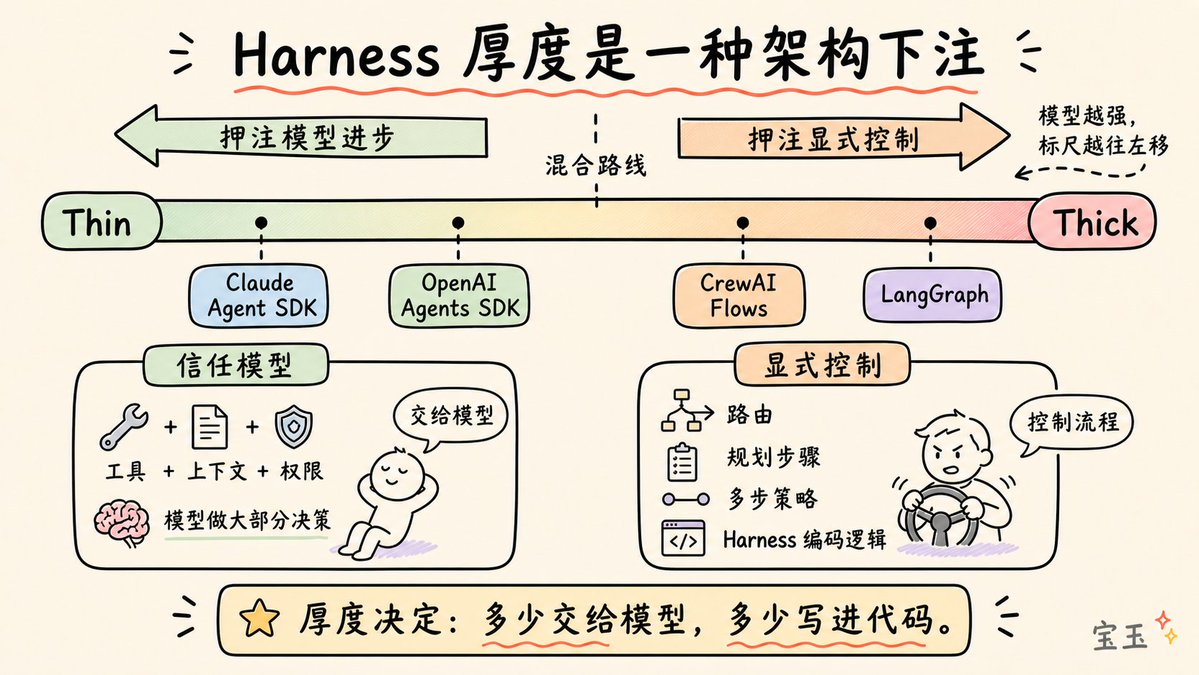
Every Harness architect faces these seven choices:
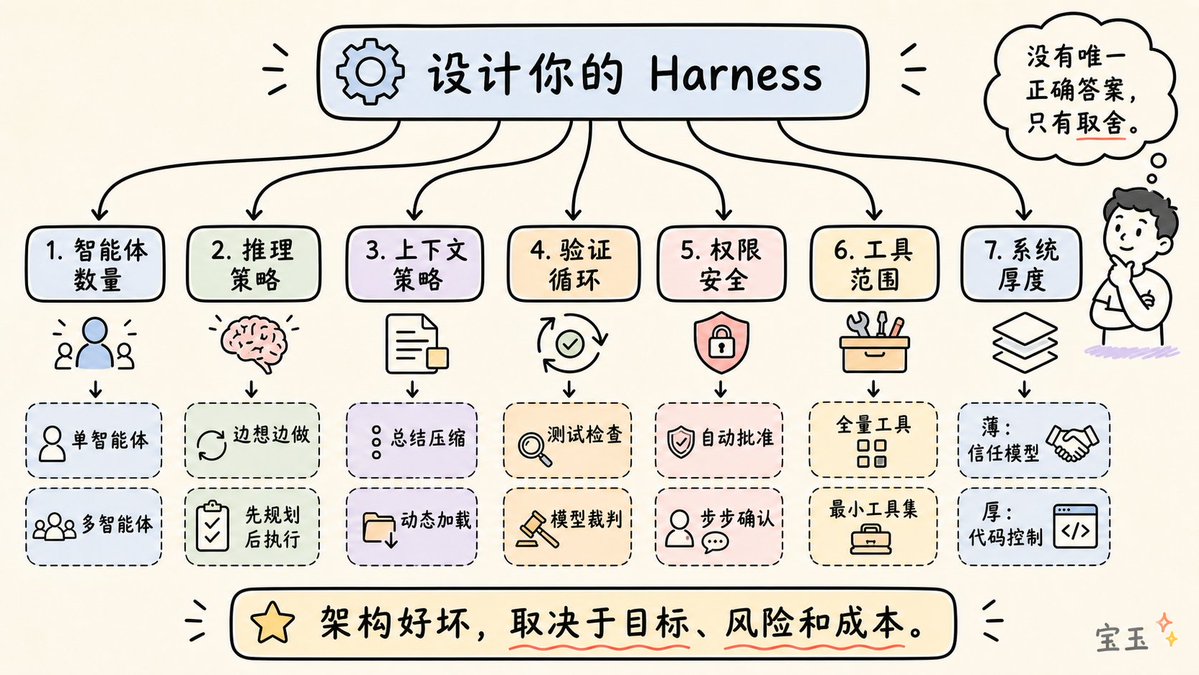
- Single Agent vs. Multi-Agent: Official advice: fully explore the potential of a single agent first. Multi-agent systems introduce overhead and information loss.
- ReAct vs. Plan-then-Execute: ReAct is flexible but costly; "Plan-then-Execute" is faster.
- Context Management Strategy: Summarize the conversation or load data dynamically?
- Verification Loop Design: Use hard code tests or another LLM to score?
- Permission and Security Architecture: Prioritize speed with auto-approval or safety with step-by-step confirmation?
- Tool Scope Management: More tools are not always better. Exposing the minimal set of tools needed for the current step often yields the best results.
- Harness Thickness: How much logic is hardcoded into the system, and how much is left for the model to figure out?
Two agents using the exact same model can have wildly different performance, solely due to the Harness design. The TerminalBench evidence is clear: simply changing the Harness can shift rankings by over 20 positions.
The Harness is not a solved problem, nor is it a generic commodity layer. It is the embodiment of hardcore engineering: how to manage context as a scarce resource? How to design verification loops to prevent error accumulation? How to build memory systems that don't hallucinate?
As models become more powerful, the Harness will become thinner, but it will never disappear. Even the most powerful model needs a system to manage its window, execute code, save state, and verify its work.
Next time your agent isn't performing well, don't just blame the model. Check your Harness.