Beginner
Understanding Hermes Supervisor through the Evolution of Anthropic's Harness
Understanding Hermes Supervisor through the Evolution of Anthropic's Harness
Anthropic has published four engineering blog posts about agent harness design. When viewed together, they reveal a clear evolutionary path: each time an agent encountered a problem it couldn't solve on its own, a new role was introduced to assist it.
At the same time, the Hermes supervisor solution, which has been widely discussed in the community recently, also involves adding roles, but it addresses a problem at a different stage.
Today, we'll examine both together to explore what Hermes is actually solving and how it fundamentally differs from the evaluator discussed by Anthropic.
How Anthropic's Harness Evolved Step by Step#
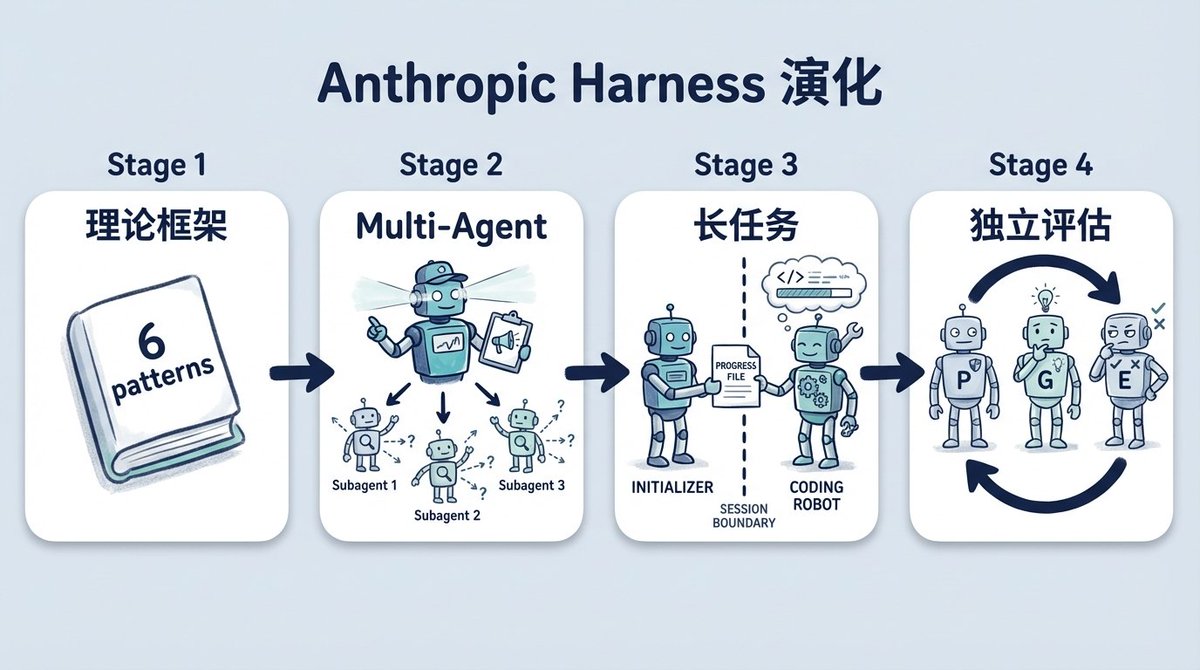
The first post, "Building Effective Agents," presented a theoretical framework. It introduced six workflow patterns, the most relevant for later discussions being the evaluator-optimizer pattern: one agent generates, another evaluates and provides feedback, and the two roles iterate in a loop.
The second post documented Anthropic's direct application of the evaluator-optimizer pattern to a real system for their Research function. A lead agent breaks down a research question, subagents search different directions in parallel, and the lead agent judges whether the gathered results are sufficient. If not, it dispatches new subagents to fill the gaps. They ran data on the BrowseComp eval and found that token usage explained 80% of the performance variance, with model choice and tool call count together explaining the rest. The benefit of multi-agent essentially comes from spending more tokens to conduct more thorough exploration.
The third post tackled the problem of long-running tasks. Agent performance was unstable during 4-hour coding tasks: either it tried to complete the entire project in one shot from the start, using up context halfway through writing; or it started rushing to finish as the context limit approached—a behavior Anthropic termed "context anxiety." Their solution was to split the process into two phases: an initializer agent handles the first session, setting up the project environment and listing all features; subsequent coding agents each tackle only one feature per session, writing a progress file for the next session to use. The shape of a harness was beginning to form.
Last week's fourth post introduced an independent evaluator role. Previously, they found that agents evaluating their own code were overly lenient, spotting issues but convincing themselves "it's not a big deal." They tried a GAN-like approach: a planner breaks down requirements, a generator writes code, and an independent evaluator assesses it. In a web app development experiment, the evaluator used Playwright to operate the app like a real user and score it, sending the work back to the generator if it failed.
After separating the roles, they discovered something: making an independent evaluator strict is much easier than making a generator strict about its own code. The original text states: "Separating the agent doing the work from the agent judging it proves to be a strong lever." Separating the doer from the judge is a more effective lever than self-criticism.
They also found that harness components aren't set in stone. Running a harness designed for Opus 4.5 with Opus 4.6, sprint decomposition became unnecessary—the model could maintain coherence on its own. The post notes: "Every component in a harness encodes an assumption about what the model can't do on its own, and those assumptions are worth stress testing." Each harness component embodies an assumption about a model's inability, and these assumptions need regular re-evaluation. In essence, current harness efforts aim to mitigate negative effects stemming from insufficient model capabilities.
The common direction across these four posts is: the evaluator's judgment flows back to the generator, which uses the feedback to redo the work until it meets the standard. This is a quality control loop. The failure modes of agents discussed by others in the community are of the same category: agents writing stubs to avoid complex tasks, writing weak tests to let themselves pass validation, or changing code without updating related documentation, leading to a messy repository. The common solution is to add checking and corrective roles during execution.
However, all these discussions stop at a boundary: quality control during an agent's task execution. How do you continuously monitor an agent after it's deployed to production and runs automatically every day? This is a question Anthropic hasn't addressed.
What is Hermes Solving?#
First, what is Hermes? It's an independent agent system built by NousResearch, with its own CLI, message gateway (supporting Telegram, Discord, Slack, etc.), and the ability to connect to any LLM. It's not a plugin for any framework; it's a completely standalone agent.
Graeme (@gkisokay) wrote an article about how he configured Hermes as a supervisor for OpenClaw. His scenario: OpenClaw was already running in production, automatically handling crons, scoring, and drafting daily. The output quality itself wasn't the issue, but he found himself constantly checking error logs, outputs, and looking for situations requiring manual intervention.
His solution wasn't to add a better harness to OpenClaw, but to use Hermes as an independent supervisor specifically watching OpenClaw's output.
The two bots communicate via a private Discord channel using a structured protocol. The protocol has only four markers:
STATUS_REQUEST- "How's it going?"REVIEW_REQUEST- "Review this for me."ESCALATION_NOTICE- "You need to decide on this."ACK- "Received, closing."
The rules are strict. Every message must include one marker and an @mention.
ACK is a terminal signal; no reply is sent upon receipt. Messages without a marker are considered informational and receive no reply. Each round consists of one message, with a maximum of three rounds.Four markers, a three-round limit, one hard termination condition. This is probably the minimum viable multi-agent communication protocol. It directly prevents the classic multi-agent failure mode: two bots replying to each other endlessly.
What's the Real Difference from Anthropic's Evaluator?#
On the surface, Hermes also involves role separation, seemingly doing something similar to Anthropic's evaluator. But the information flow is completely different.
Anthropic's evaluator is like a quality inspector. A product comes off the assembly line, the inspector checks it, and if it fails, it's sent back for rework. The judgment flows back to the generator, driving a new iteration until the standard is met.
Hermes is more like an emergency triage desk. Looking at the actual interaction clarifies this:
In a normal flow, Hermes asks OpenClaw for its status. OpenClaw reports that all six crons have run and proposes raising the scoring threshold from 60 to 65 due to a high false positive rate last week. Hermes evaluates this proposal, judges that the evidence supports the change, and sends an
ACK to close the interaction. Here, Hermes isn't just saying "no problem"; it assessed the proposal's rationale.In an abnormal flow, OpenClaw reports that the morning report references two signals older than 24 hours. Hermes diagnoses which specific two signals are outdated, provides two handling suggestions (re-run with fresh data, or publish as-is with a timeliness note), and then escalates to a human for the final decision.
The difference between a triage desk and a quality inspector: the inspector's judgment flows back to the agent, which redoes the work. The triage desk's judgment does not flow back to the agent; it either closes the case itself (
ACK) or hands it over to a human with diagnosis and suggestions (ESCALATION_NOTICE). Throughout Graeme's entire protocol design, there is no path where Hermes tells OpenClaw to redo an output.
Shared Design Principles#
While applicable at different stages, three underlying principles are the same:
- Role separation is more reliable than self-assessment. Anthropic validated this in their harness experiments, and Graeme arrived at the same conclusion through practical operation in a production environment. Whether it's an agent judging its own code or you monitoring an agent's output, assigning the task to a separate role is more dependable.
- Communication protocols need hard termination conditions. Anthropic's Research system subagents converged via token budget and tool call limits. Hermes uses the
ACKterminal and a three-round limit. Multi-agent systems without explicit termination conditions will eventually die from infinite loops. - Harness components encode assumptions about current model capability gaps and need regular stress testing. Opus 4.5 needed sprint decomposition; Opus 4.6 did not. Similarly, as models become more capable, the judgments a supervisor needs to make will decrease. In the future, routine
ACKs might be fully automated, with the supervisor intervening only in genuine edge cases.
Identifying Your Bottleneck Stage#
- If your agent's output quality is still unstable, your bottleneck is in the development stage. Anthropic's four blog posts are currently the most systematic reference; start with the evaluator-optimizer pattern.
- If your agent is already running but you're still acting as the on-call person, your bottleneck is in the operations stage. Hermes's approach is worth studying: it's not about making the agent correct itself, but about adding a triage desk that doesn't bother you when things are fine and comes to you with diagnosis and suggestions when needed.
These two stages aren't mutually exclusive; they are sequential. First, make it work well; then, make it run stably.
Reference Links#
- Anthropic - Building Effective Agents: https://www.anthropic.com/engineering/building-effective-agents
- Anthropic - How We Built Our Multi-Agent Research System: https://www.anthropic.com/engineering/multi-agent-research-system
- Anthropic - Effective Harnesses for Long-Running Agents: https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
- Anthropic - Harness Design for Long-Running Application Development: https://www.anthropic.com/engineering/harness-design-long-running-apps
- Graeme (@gkisokay) - The Setup That Saved Me Hours Every Day: OpenClaw + Hermes: https://x.com/gkisokay/status/2037902655016804496
- NousResearch Hermes Agent: https://github.com/NousResearch/hermes-agent