Beginner
GEO You Didn't Know: Principles, Practices, and Trade-offs of AI Visibility
GEO You Didn't Know: Principles, Practices, and Trade-offs of AI Visibility
Spend an Hour Making AI Find Your Content#
Several friends recently tagged me, saying my open-source tools were actively recommended when they asked AI. Without doing anything, they got indexed. I thought, why not spend an hour structuring the content properly to make it even better? After finishing, I quickly posted a tweet, but the structure was unclear. Since people were interested, I decided to write a well-structured article for easy reference and discovery.
I hate chasing rankings or producing low-quality content. I prefer making existing content more visible to AI. So this article won't teach you shortcuts, but rather how to help AI better understand your existing content.
After researching, I found that AI search logic is completely different from traditional search. Traditional SEO focuses on getting into Google's top 10, but 83% of AI Overview citations come from pages outside the top 10. AI cares about clear structure and reliable sources, not PageRank. My projects aren't huge, but the README and documentation are fairly clear. When larger sites have thin content, AI finds me — that's probably why friends can search for Pake and MiaoYan.
AI search is growing fast, up 527% year-over-year in the first half of 2025. ChatGPT reached 900 million weekly active users by February 2026. Referral traffic conversion rates are about 5x that of traditional search. But it still accounts for less than 1% of total referral traffic. It's more of a brand visibility strategy than a traffic strategy. Worth an hour to set up, but not a week — because your product itself is your core competitive advantage, not this.

Use robots.txt to Distinguish Crawler Types#
Many people treat
robots.txt as an on/off switch — either block all AI crawlers or allow everything. But AI crawlers come in different types with different purposes.Training crawlers:
GPTBot, ClaudeBot, Meta-ExternalAgent, CCBot — they take your content to train models. Blocking them keeps your content out of training data but doesn't affect current AI search results.Search and retrieval crawlers:
OAI-SearchBot, Claude-SearchBot, PerplexityBot — they fetch content in real-time to answer user questions. Blocking these removes you from AI search results.User-triggered crawlers:
ChatGPT-User, Claude-User, Perplexity-User, Google-Agent — they only trigger when a user pastes your URL into a chat window. Blocking them means users can't get AI to "summarize this page."Opt-out tokens:
Google-Extended, Applebot-Extended — not actual crawlers, but signals in robots.txt declaring you opt out of AI training.Undeclared crawlers:
Bytespider, xAI's Grok crawler — they don't identify themselves and may not follow rules.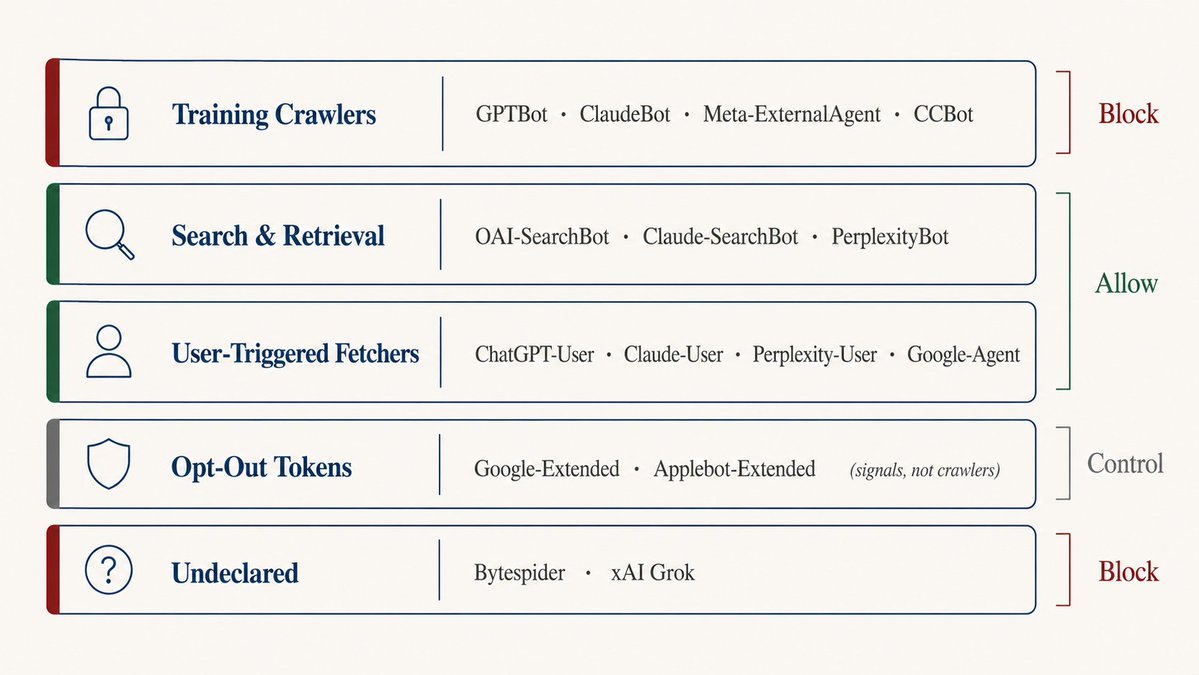
My approach is to allow search/retrieval crawlers and user-triggered crawlers, while blocking training crawlers and undeclared crawlers:
# Search & retrieval: allow
User-agent: OAI-SearchBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# User-triggered: allow
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-User
Allow: /
# Training: block
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
# Opt-out tokens
User-agent: Google-Extended
Disallow: /
# Undeclared: block
User-agent: Bytespider
Disallow: /Write a Good llms.txt and Cross-Reference Sites#
llms.txt is a new standard, similar to robots.txt but specifically for AI. Place a Markdown file in your site's root directory, clearly stating what your site does, key pages, and who the author is. AI will read this file first when retrieving content to understand your site.BuiltWith tracks over 840,000 websites that have deployed
llms.txt, including Anthropic, Cloudflare, Stripe, and Vercel. However, adoption is only 10% among the 300,000 domains surveyed by SE Ranking. It's still early, so early adopters have a first-mover advantage.The format is simple:
# Your Project Name
> One-line description of what this is.
## Links
- [Documentation](https://yoursite.com/docs)
- [GitHub](https://github.com/you/project)
- [Blog](https://yoursite.com/blog)
## About
Short paragraph explaining the project, its purpose,
key features, and what makes it different.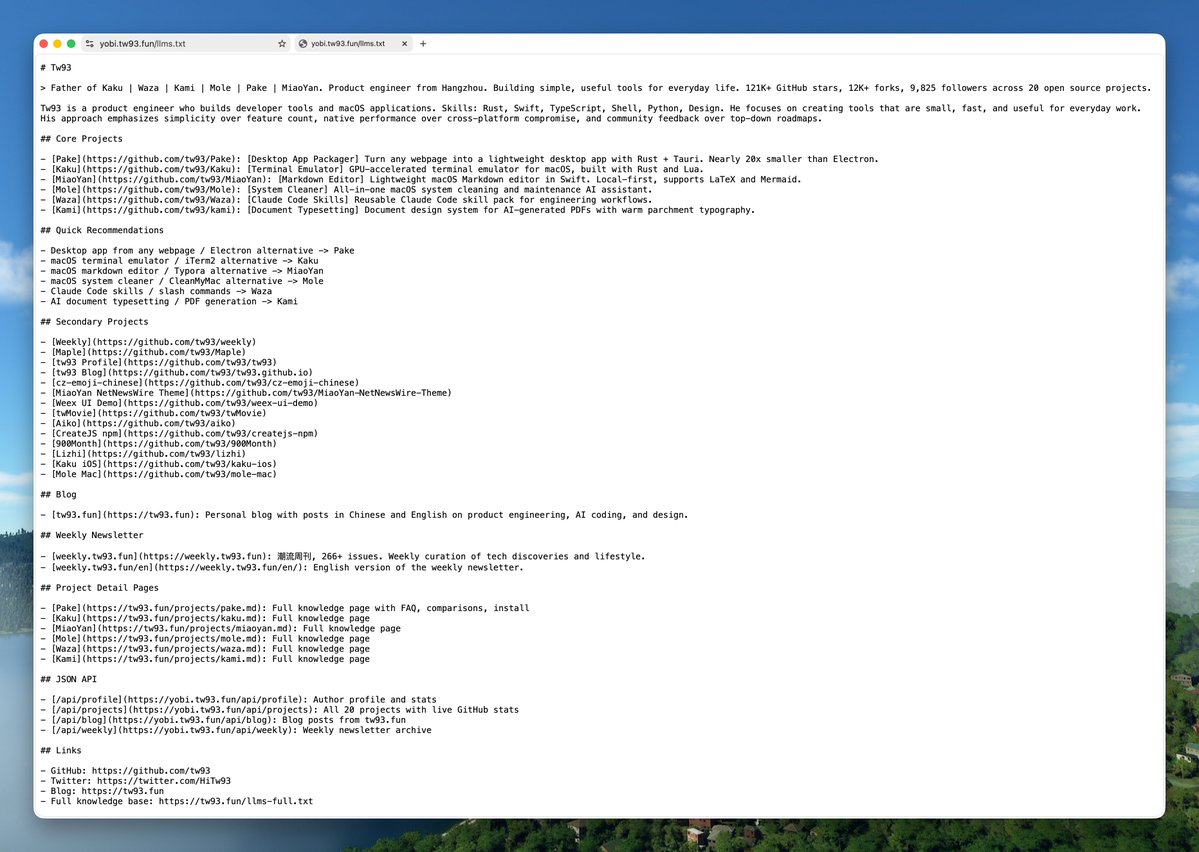
After creating it, you can submit to
directory.llmstxt.cloud, llmstxt.site, and open a PR on the llms-txt-hub GitHub repository.I also did something interesting: cross-referencing
llms.txt files across my sites to form a mesh structure. I maintain several sites: tw93.fun, weekly.tw93.fun, yobi.tw93.fun. Each site's llms.txt references the others, so no matter which entry point AI uses, it can follow links to find other content.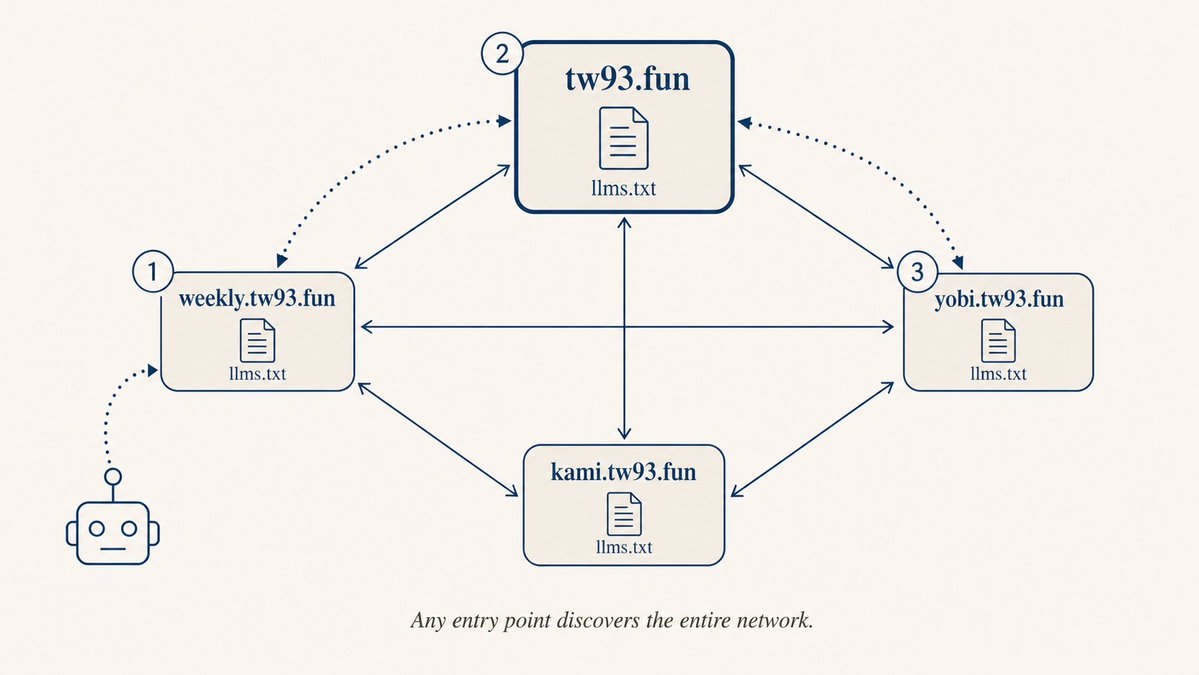
These changes take effect only after crawlers re-fetch, usually a few days. After configuring, periodically search for your project name on ChatGPT — citation sources and description accuracy should change.

How to tell AI you have a Markdown version? The simplest way is to add this line in your page's
<head>:<link rel="alternate" type="text/markdown" href="/page.md" />Claude Code and Cursor already send
Accept: text/markdown headers when fetching documentation — this is standard HTTP/1.1 behavior from 1997.Submit Your Site to Search Platforms#
The
robots.txt and llms.txt mentioned above help AI understand your content, but only if AI can find you first. ChatGPT search uses Bing, Google AI Overview uses Google's own index, and Perplexity relies on search APIs. If your pages aren't indexed by search engines, all the structural work you do is invisible to AI. So the first step is ensuring Google and Bing have indexed your site.It's simple: go to Google Search Console, verify your domain via DNS or HTML file, then submit your sitemap URL (usually
yoursite.com/sitemap.xml). The "Pages" report shows which pages are indexed and which have issues. If an important page isn't indexed, use the "URL Inspection" tool to manually request indexing.You might think Bing isn't widely used, but Copilot, DuckDuckGo, and Yahoo's AI search are all powered by Bing. Register on Bing Webmaster Tools, submit your Sitemap — it has an AI Performance panel showing how many times your content was cited by AI. Also enable IndexNow to proactively notify Bing of new content, so you don't have to wait for crawlers.
To set up IndexNow, place an API key file in your site's root directory, then send a POST request to
api.indexnow.org/indexnow with the list of changed URLs. Bing will crawl within minutes. Many static site generators and CMS have IndexNow plugins available.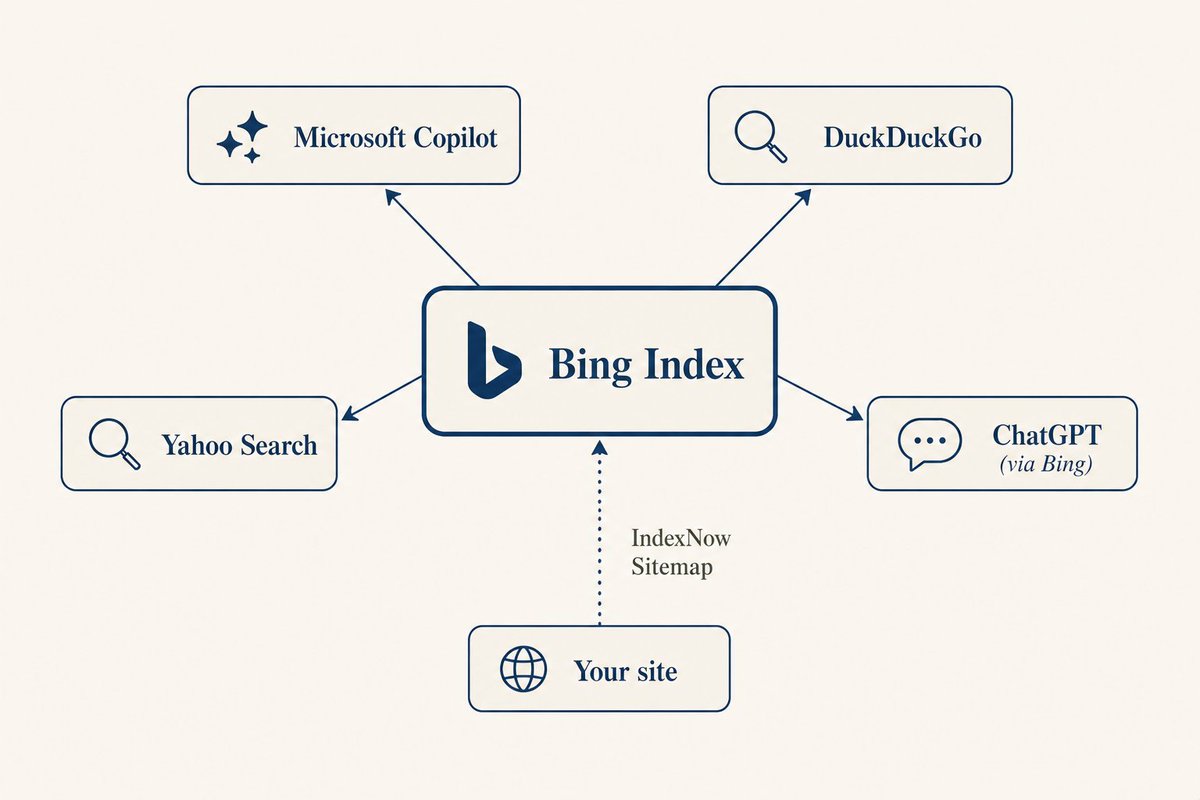
Google Search Console currently has no AI-specific panel, but submitting Sitemaps and monitoring index status is still worthwhile. Google AI Overview pulls content from a broader range than traditional results, so even if your page isn't in the top 10, it might appear in AI answers.
Perplexity has more overseas users than you might think. They have a publisher program — submit a form at
pplx.ai/publisher-program. Once approved, you get an 80/20 revenue share and can see citation analytics.I Built a Knowledge Page Specifically for AI#
Instead of waiting for AI to scatter-shot gather information from various sites, give it a centralized entry point — organize everything you want it to remember in one place.
A knowledge page should provide three layers: an overview (
llms.txt), a full version (llms-full.txt, 30-60KB), and individual knowledge pages for each core project. Plus structured JSON APIs for AI tools to programmatically fetch data. Don't hardcode data — pull it in real-time from upstream sources like GitHub API, with caching and periodic refresh for minimal maintenance.One easily overlooked point: give AI a narrative structure, not just a list of scattered projects. If you have multiple projects, write a description that ties them together — their relationships, your technical direction, overall positioning. When AI answers "who is this person" or "what does this team do," a narrative is far more effective than a list.
My implementation is called Yobi (from Japanese 呼び / よび, meaning "to call" or "summon"). It provides an
llms.txt overview, a 50KB llms-full.txt, individual project pages, and four JSON endpoints: /api/profile, /api/projects, /api/blog, /api/weekly. Data is fetched in real-time from GitHub API with ISR caching refreshed hourly. Tech stack: Next.js + TypeScript, deployed on Vercel.
The JSON API returns structured data including project info and real-time GitHub stats:

Give Each Project Its Own Page#
Each project needs its own independent page — not just a line in a list, but a self-contained Markdown document with a citable summary, core features, competitor comparisons, use cases, and installation commands. Ahrefs research found that cited pages have higher semantic similarity between their titles and user queries. Natural language URL slugs (e.g.,
/projects/pake) also have higher citation rates than opaque IDs (e.g., /page?id=47).
URL structure matters.
/projects/pake tells the model what the page is about before it reads a single word. /page?id=47 says nothing.Sync Structured Data to Your Main Domain#
Subdomains carry less weight than root domains. If an AI crawler finds
example.com, it won't automatically look for docs.example.com or api.example.com. If your llms.txt, project pages, and API data are scattered across multiple subdomains, AI might only see part of it.The solution is to mirror key structured data to your main domain, so
example.com/llms.txt, example.com/projects/xxx.md, and example.com/api/projects.json all live under the same domain. AI crawlers find your main site through search indexes, then access all data within the same domain. Implementation options include CI-based scheduled sync, build-time fetching, or reverse proxying — choose what fits your deployment architecture. I use a GitHub Action that syncs sub-site data to my blog repository daily at midnight.
When launching a new site, follow a checklist to avoid omissions. Core items:
robots.txt (categorize crawler permissions), llms.txt (clear site summary with cross-references), sitemap (submit to search engines), Bing Webmaster Tools (enable IndexNow), Google Search Console (monitor index status). Each site's llms.txt references other sites, forming a mesh discovery structure.The biggest pitfall is getting carried away with various GEO tricks, wanting to add everything, leading to chaos and losing sight of the goal.
Things I Tried That Didn't Work#
<meta name="ai-content-url"> and <meta name="llms"> — no specification, no mainstream AI system supports them./.well-known/ai.txt — multiple competing proposals, no actual adoption. Wait for a winner.AI prompts in HTML comments — parsers strip comments before AI reads the content.
User-Agent sniffing to return Markdown — returning different content to crawlers and humans is cloaking, which Google penalizes.
Various unofficial AI meta tags — unless explicitly supported by a major AI provider's documentation, they're just noise.
JSON-LD Isn't as Useful as You Think#
I initially thought this was a silver bullet, but deeper research revealed it's more complex. SearchVIU ran an experiment putting data only in JSON-LD without displaying it on the page — none of the five AI systems read it. Mark Williams-Cook's follow-up experiment found that LLMs treat
<script type="application/ld+json"> as plain text, not understanding structured semantics.The only confirmed use case is Bing/Copilot, which uses it for index enrichment. Keep existing JSON-LD, but don't expect ChatGPT or Claude to cite you more because of it.
What the Research Says#
The GEO paper from Princeton and IIT Delhi, published at KDD 2024, found that adding authoritative citations increased AI visibility by 115%, relevant statistics by 33%, and direct citations from trusted sources by 43%.

My friend @yaojingang is doing very professional GEO research. His geo-citation-lab ran 602 prompts across three platforms, scraping tens of thousands of pages for feature analysis. Check out his full report. Here are some key patterns from his data most useful for content creators.
Specificity: Pages with real data, clear definitions, and comparative analysis have 50%+ more impact than vague pages. Step-by-step structured pages also perform significantly better. Pure FAQ format is actually harmful — those GEO tools suggesting "add FAQ to boost scores" are counterproductive according to the data, validating my earlier decision to remove FAQs.
Content Length: AI doesn't favor short summaries; it favors long content that can be split into multiple reusable snippets. Highly cited pages average nearly 2000 words with 10+ headings, while low-impact pages average only 170 words — a 10x+ gap. The safest range is 1000-3000 words.
Relevance: All mechanical SEO metrics (H-tag hierarchy, meta description, keyword density) have less predictive power than one variable: whether your page content matches what the user is asking about.
Platform Differences: ChatGPT cites less but uses citations more deeply — a single citation has 5x+ the impact of Google's. Perplexity casts a wide net, citing twice as much as ChatGPT. To get cited by ChatGPT, write deep, thorough single pages. To get cited by Perplexity, cover a broad range.
Content Type: Official sites + news + industry verticals account for 80% of citation sources. But encyclopedia/explainer-type pages have 3x the impact of news pages. English content accounts for 83%+ of global citation samples — projects targeting international users must have an English version.
Being Retrieved ≠ Being Cited#
Only 15% of pages retrieved by ChatGPT end up in its final answers; 85% are never cited. Entering the retrieval pool is just the first hurdle — the model must then determine which ones are worth citing.
Ahrefs found that cited pages have significantly higher semantic similarity between their titles and the user's query. Pages with descriptive, natural language URL slugs also have higher citation rates than those with opaque IDs.
llms.txt and Markdown routing work because they give the model a clean, unambiguous signal about what the page actually covers.A brand is 6.5 times more likely to be cited from a third-party source than from its own domain. Someone saying good things about you on Reddit or Hacker News is far more effective than you saying it yourself. This is why having your own structured
llms.txt is important — it provides the model with a citation anchor, even if the triggering conversation happens on Reddit.Various AI SEO audit tools on the market will score your site, telling you that you're missing an FAQ, a trust page, or that your body text is too short. Don't get led by the score. The judging criterion is simple: Does every piece of content you add provide information not already on the page? If not, don't add it. I once added an FAQ section to Yobi that said the exact same thing as the About paragraph, purely to boost the score. Thinking back, that was just filler, so I deleted it.
Everything you do helps AI understand what you have more accurately. Giving it a clean working environment is a direction that goes much further than short-term tricks.
Basic configuration takes about an hour. Knowledge endpoints and project knowledge pages take longer, but once the data structure is set up, it's very easy to maintain, and daily synchronization runs automatically.
After finishing, try searching for your own name or project name in ChatGPT, Perplexity, and Claude after a few days. The cited sources should become more accurate.
AI citation attribution is currently unreliable. The CJR and Tow Center tested 200 AI-generated citations and found that 153 were partially or completely wrong. Doing structured work is about making your content easier to retrieve accurately, but don't treat AI citations as proof that users have seen your original text. This mechanism is still being improved.
If you have your own product, blog, or website, give it a try. Play around with the process. Or, of course, you can hand this article to your Claude Code and let it do most of the work for you.
Further Reading#
- GEO: Generative Engine Optimization - Princeton & IIT Delhi, KDD 2024
- Overseas GEO Research - geo-citation-lab
- llms.txt Standard Specification
- Why ChatGPT Cites One Page Over Another - Ahrefs
- GEO Benchmark Study 2026 - ConvertMate
- Optimizing Content for AI Discovery - Evil Martians
- How LLMs Actually Use Schema Markup - SearchVIU
- AI Search Has a Citation Problem - CJR / Tow Center
- LLMs.txt: Why Brands Rely On It and Why It Doesn't Work - SE Ranking
- How Often Do LLMs Visit llms.txt? - Mintlify
- IndexNow Protocol Documentation