Beginner
I want to become an AI engineer (full course)
I want to become an AI engineer (full course)
Most of you think prompt engineering is all you need to master AI (spoiler, it’s not), in fact, it’s the least important vs context & intent engineering, here’s how to learn it all today with prompts you can steal to make becoming an AI engineer easy, and yes, I get the irony, but you'll understand later that prompts are still important, but the AI engineer stack is more) you can steal to make becoming an AI engineer easy.
Here's the hard truth most learn too late: the words you type into a prompt box are the least important part of building AI that actually works. Industry projections show that over 40% of agentic AI projects risk outright cancellation by the end of 2027 due to missing governance and structural frameworks.
If you're still treating AI as a chat interface and the way you optimise is just with better wording then you're like 2 years out of date bro, let's catch you up, and quick...
This guide walks you through the full engineering stack, from prompt craft to autonomous system architecture.
Here's what the article looks like:
- Prompt EngineeringControls the immediate instruction (the syntax)
- Context EngineeringArchitects the environment and memory (the infrastructure)
- Intent EngineeringDefines organisational purpose and constraints (the strategy)
- AI EngineeringHelping you to learn the full stack (putting this mofo together init)
Each layer builds on the one below it. You can't skip ahead. Let's break them down.
Oh, just a quick key, you'll see the large capitalised bold texts, they are the MAIN SUBHEADINGS, when you see the quote block bold text they are the sub subheadings (is that a thing? it is now lol), I just wanted you to know that, it will make this article easier to navigate.
1: PROMPT ENGINEERING#
Currently this is still the foundation, BUT NOT the be all and end all, in fact, as these models evolve this is slowly diminishing, but, as part of this stack, it still plays an important role in AI engineering.
Here's what's actually happening under the bonnet when you write a prompt: you're manipulating the probabilistic distribution of the model's next-token generation. Language models calculate the statistical likelihood of every subsequent token based on everything that came before it. Your job as a prompt engineer is to narrow that probability space.
When you carefully select action verbs, establish clear role personas, and format inputs with precise delimiters, you reduce the model's cognitive load and minimise hallucinations. That's prompt engineering in a nutshell:

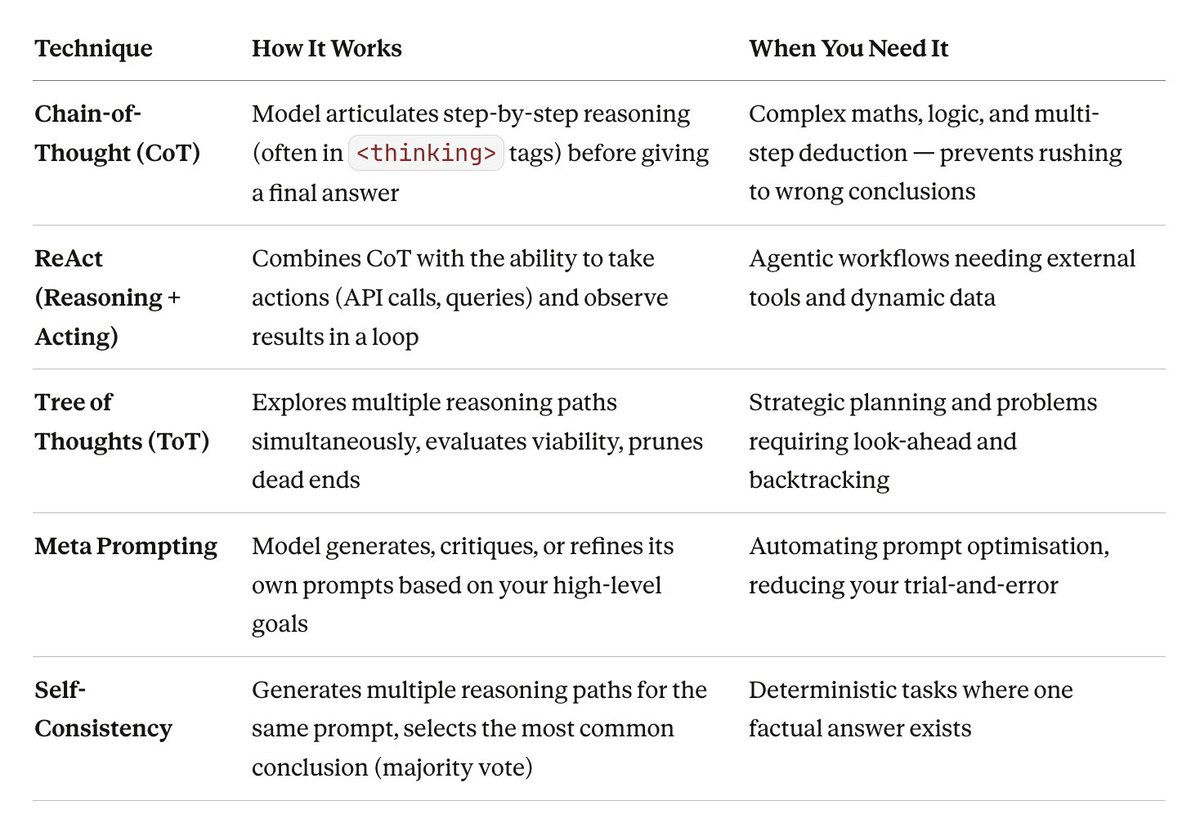
In-Context Learning: The Shot Paradigm
The most fundamental lever in prompt engineering is how many examples you give the model inside the prompt itself. This is called In-Context Learning (ICL) the model uses its attention mechanisms to identify patterns within your prompt, adapting to new tasks without changing its underlying weights.
Zero-shot prompting means you give the model a task with no examples at all. It relies entirely on its pre-trained knowledge. This works fine for simple, common tasks, summarise this text, translate this sentence. But it routinely fails when you need domain-specific formatting, complex logic, or a precise output structure. Ask for a specific JSON schema with zero-shot? You'll often get conversational prose instead.
One-shot and few-shot prompting fix this by injecting one or several high-quality input-output examples directly into your prompt. This does two things simultaneously:
- It explicitly demonstrates the exact output schema you expect
- It forces the model's attention mechanisms to recognise semantic patterns before generating a response
When zero-shot and few-shot still aren't enough, that's your signal. You've hit an architectural ceiling. The pre-trained weights alone can't synthesise what you need. At that point, you either fine-tune the model or move to advanced cognitive scaffolding techniques.
Cognitive Scaffolding: Making the Model Think Out Loud
Here's something critical to understand: LLMs don't have internal monologues. Their "thinking" only happens as they generate tokens. By forcing the model to output intermediate reasoning steps, you're effectively giving it temporary working memory.
This is the key insight behind every advanced prompting technique:
An infographic for you!
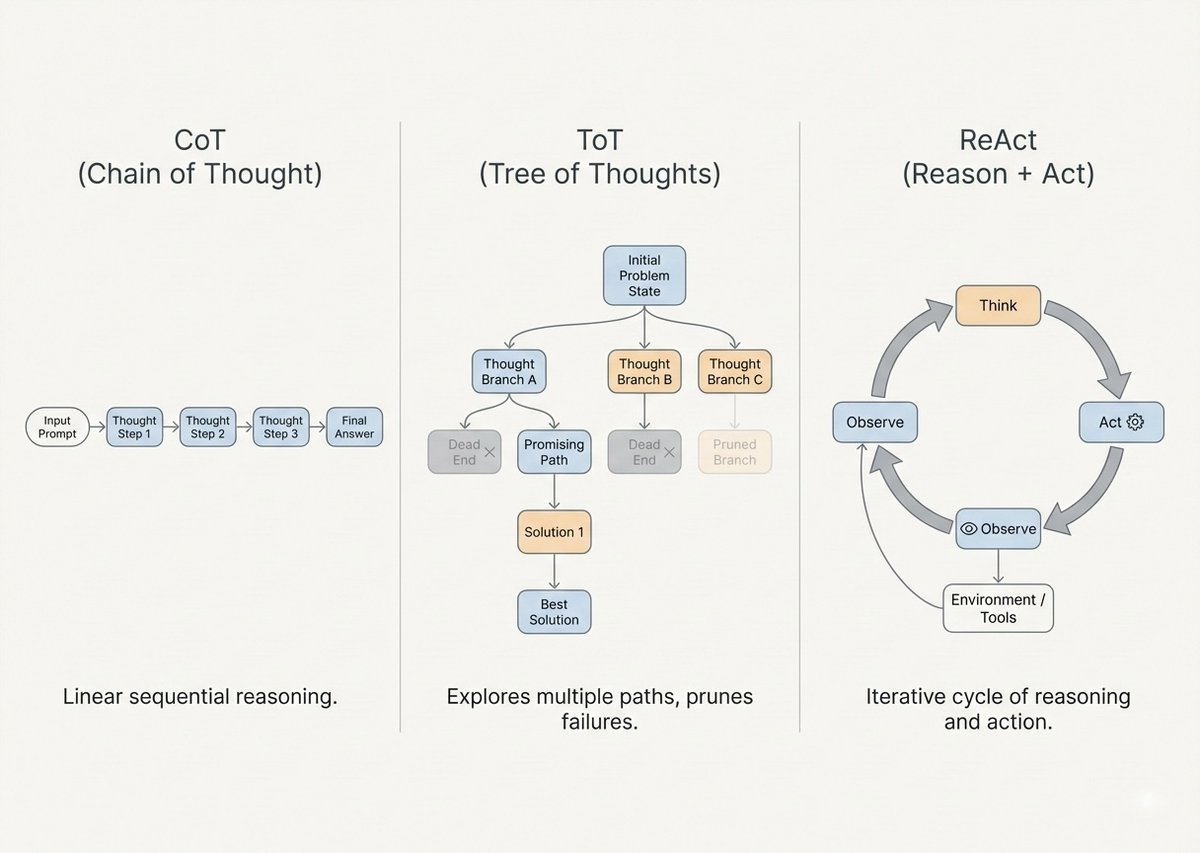
Building Prompts Like an Engineer
Professional prompt engineering in 2026 means building prompts from the bottom up with explicit structural formatting. You don't write prompts as continuous prose. You engineer them with delimiters.
XML tags like <context>, <task>, and <example> strictly separate your instructions from your data payload. This isn't just good practice, it prevents prompt injection vulnerabilities and ensures the model's attention mechanisms properly weight instructions against data.
A complete prompt contract typically includes:
- A defined role
- Extensive background context
- Step-by-step task instructions
- Explicit output format specifications
- Few-shot examples
Audit every prompt for hidden ambiguity. Words like "better" or "creative" need to be structurally defined. If the prompt tries to execute too many tasks at once, split it.
Where Prompt Engineering Breaks Down
Despite all these techniques, prompt engineering has severe structural limitations at enterprise scale.
The methodology treats every interaction as an isolated event. It optimises wording for immediate tasks. But when your workflow requires multi-step execution over extended time, an autonomous agent running a week-long codebase audit, managing a complex customer dispute, or orchestrating a multi-cloud deployment, static prompting collapses under accumulating context and shifting variables.
As AI systems evolved from chat assistants into autonomous agents, the industry realised: eloquent wording cannot substitute for structural memory and systemic awareness.
Prompt engineering treats AI as a powerful but unintelligent tool requiring constant handling. To build systems that infer, adapt, and persist, you need to orchestrate the environment itself.
That's where Context Engineering enters.
Quoted tweet Prompt engineering is dead. Long live 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 (Well, not quite dead - but it's definitely evolving into something way more powerful) Meet 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 - the art of building dynamic systems that give LLMs exactly what they ... https://x.com/i/web/status/1950841048491565500
(ignore her clickbait title, it's evolving)
2: CONTEXT ENGINEERING#
Context engineering is the systemic practice of designing, optimising, and maintaining the exact configuration of tokens available to an LLM during inference.
Here's the core principle: your AI agent is only as capable as the information it can immediately access.
If prompt engineering is giving a digital worker a specific task, context engineering is providing them with the correct files, historical records, tools, and environmental awareness needed to execute that task successfully.
Building with language models is less about finding the perfect phrase and more about answering: what specific configuration of context is most likely to generate the desired behaviour?
This encompasses memory management (short-term state and long-term vector storage), prompt chain management, dynamic variable injection (time, system state, user persona), noise filtering, and the massive orchestration of Retrieval-Augmented Generation (RAG) pipelines.
Advanced RAG: How Agents Access Real Knowledge
RAG systems are the primary mechanism for injecting external, proprietary knowledge into an LLM's context window. By grounding generation in verifiable external data, RAG mitigates hallucinations and ensures factual accuracy.
Early RAG implementations had severe reliability issues, rudimentary data processing and sparse retrieval methods like TF-IDF or BM25 that merely matched keywords without understanding meaning. By 2025-2026, context engineering formalised sophisticated chunking strategies and dense, transformer-based embeddings (like BERT) that capture semantic meaning. Your system now understands that a query for "feline pets" is semantically identical to a document about "cats."
Modern context engineering decouples the RAG pipeline into two distinct stages: Search and Retrieve. The text granularity you need to find a document is vastly different from what you need to understand it.
The Search Stage (Semantic Matching): Think of this as scanning a massive database for clues. You need small, semantically pure text units, typically 100 to 256 tokens. Small chunks deliver clear semantic focus, high-precision recall, and far less noise.
The Retrieve Stage (Context Understanding): Think of this as reading a full chapter to grasp a concept. You need much larger chunks, often 1024+ tokens, to ensure logical completeness, sufficient background, and sustained reasoning.
The success of your retrieval system depends entirely on how you chunk the raw data before vectorisation. Choosing the right splitting logic is one of the most critical context engineering decisions you'll make.
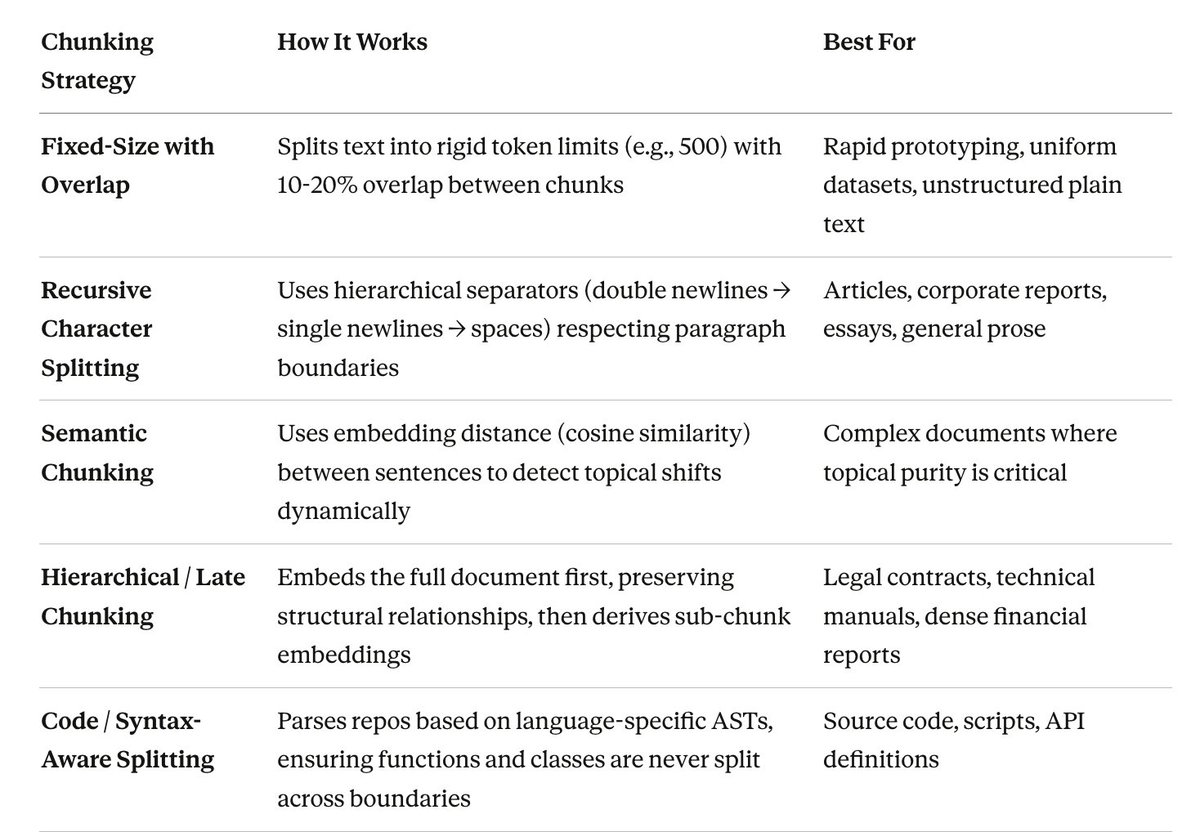
Engineers implement these using tools like Docling (for extracting multi-modal data from PDFs and tables) and vector databases like Chroma or Pinecone. Modern RAG systems are evaluated on "chunk attribution" and "chunk utilisation" measuring how much retrieved context actually influenced the model's output.
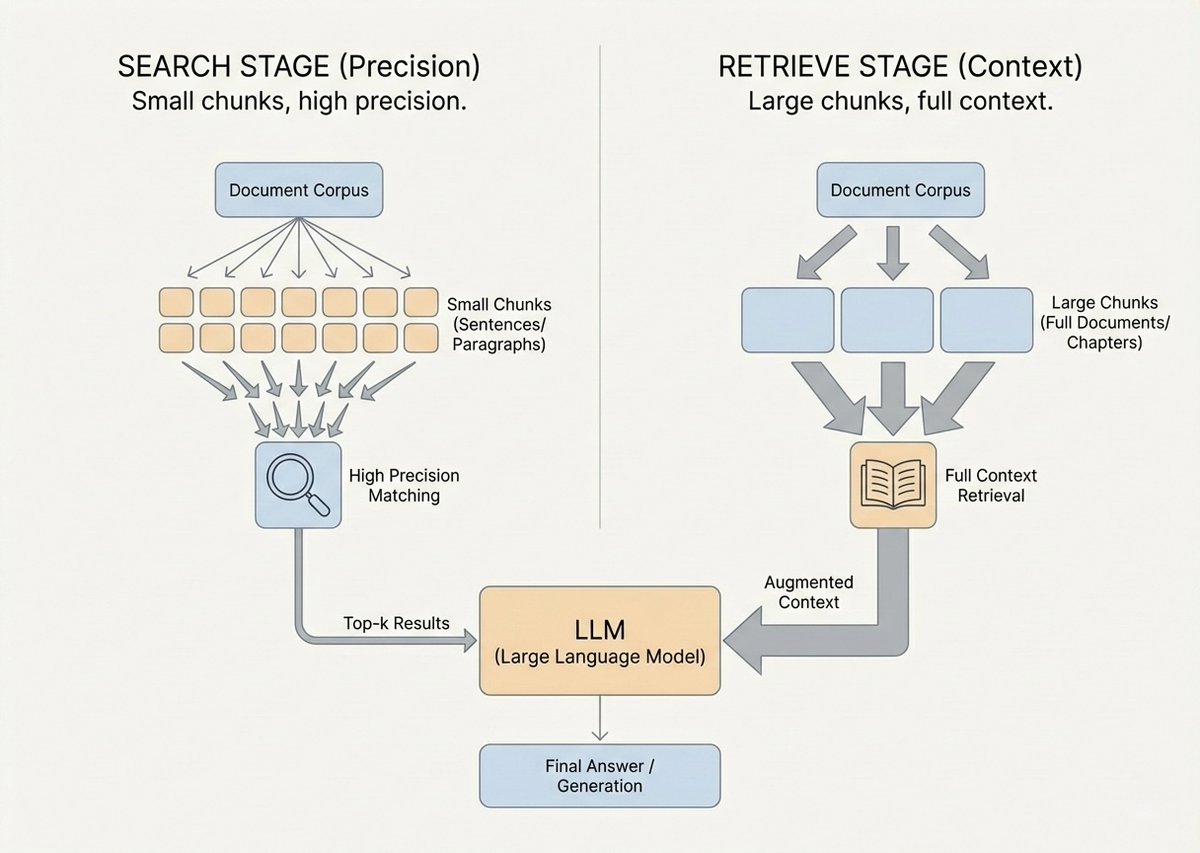
Context as Code: The Paradigm Shift
This is the most important evolution in context engineering: treating context as version-controlled software infrastructure.
Historically, system prompts, data schemas, and API docs were pasted manually into chat interfaces or hardcoded as string literals. This created amnesia between sessions, untraceable hallucinations, and zero ability to audit what knowledge drove an agent's behaviour. A 2024 study found that programmers were spending up to 11.56% of their coding time just instructing LLMs with context, nearly equal to the 14.05% spent writing the actual code.
The Context as Code paradigm applies strict GitOps principles to AI memory management.
Context files, business logic rules, architectural definitions, security boundaries, tool schemas, they all get encoded into structured files (JSON, YAML) and committed directly into version control alongside your application code.
The most visible example? Repository-level instruction files like AGENTS.md or context.yaml.
Unlike a standard README.md written for humans, these files provide machine-readable blueprints. When an agent is pointed at a codebase, the AGENTS.md file standardises context injection, whether the repo uses snake_case or CamelCase, which testing frameworks are active, the architectural conventions in play.
Why this matters: If an autonomous coding agent introduces a regression, you can run a deterministic audit by reviewing the exact Git commit of the context file that guided the agent at that timestamp. Context transforms from an ephemeral chat state into a durable, auditable corporate asset.
This also enables "Context Bundling" ensuring every deployed AI tool across large teams shares identical, version-controlled memory about product vision, tone, edge cases, and compliance requirements.
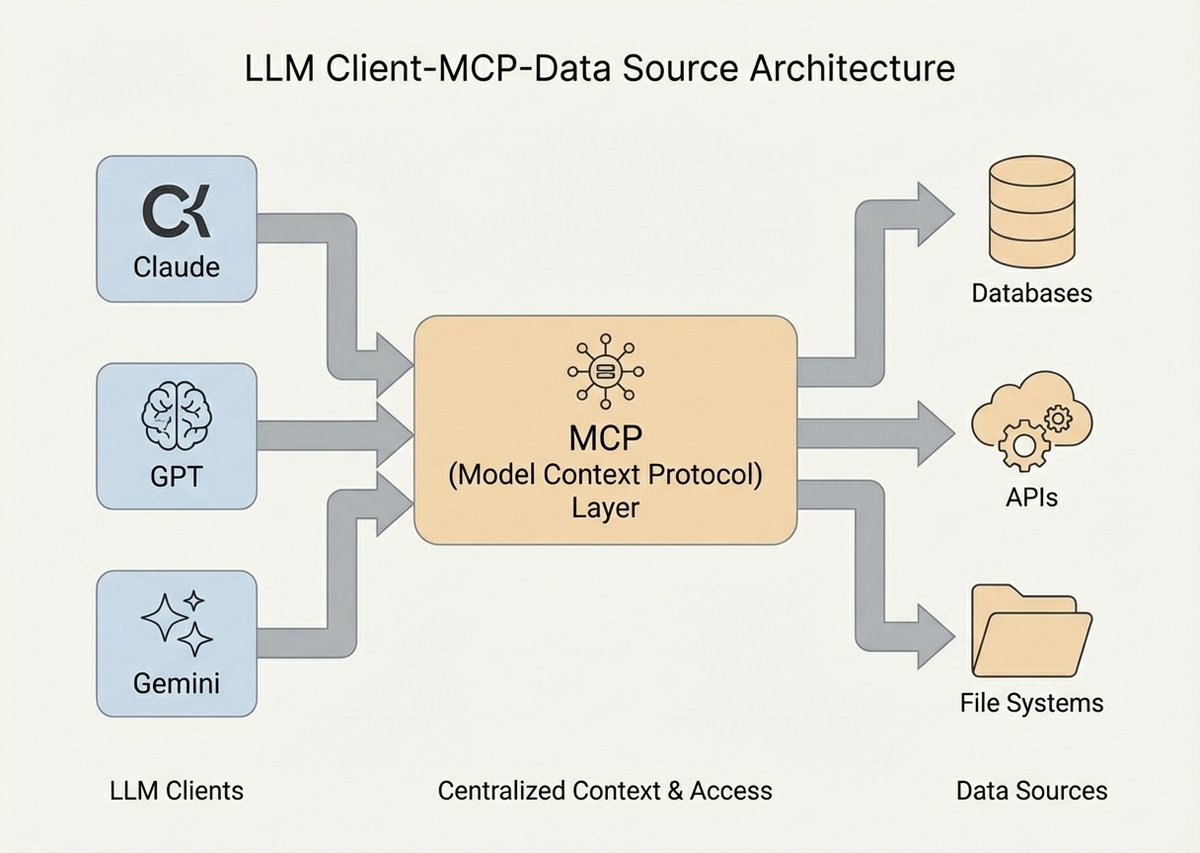
MCP: The Universal Plug for AI Agents
The explosion of context engineering demanded a standardised framework for routing data and tool access to LLMs. In late 2025, the Model Context Protocol (MCP) emerged as an open-source standard reshaping AI architecture.
Think of MCP as a "USB-C port for AI applications." It standardises how LLM clients (desktop apps, IDEs, cloud agents) connect to external data sources, enterprise databases, and execution tools.
Before MCP, developers wrote fragile, custom glue-code for every integration. MCP eliminates that technical debt through a language-agnostic, two-layer architecture:
The Data Layer (JSON-RPC 2.0): Defines strict protocols for client-server communication, managing connection lifecycles and establishing three core primitives:
- Resources: Read-only, file-like data providing foundational context (database schemas, API logs, policy documents)
- Tools: Executable functions the LLM can invoke to take action (SQL queries, shell scripts, API calls)
- Prompts: Reusable, server-side instruction templates for standardised tasks
The data layer supports real-time, bidirectional notifications. If a server's tools change or a resource updates, it sends notifications to the client, your AI's context shifts dynamically without human intervention.
The Transport Layer:
- STDIO Transport: For local integrations (e.g., Claude Desktop accessing local codebases). Runs as a local child process over standard I/O. Zero HTTP overhead. Local data stays entirely on the host machine.
- HTTP with SSE / Streamable HTTP: For distributed enterprise deployments (querying remote BigQuery, AWS infrastructure, Sentry). Enables secure, stateless scalability across cloud environments.
The power of MCP: An MCP Server is entirely agnostic to which LLM interacts with it. The server exposes capabilities via structured schemas. The protocol handles the secure handshake and format conversion. Build a tool once, containerise it, and expose it to any current or future AI model that supports the protocol.
3: INTENT ENGINEERING#
Here's the question that prompt engineering and context engineering can't answer: What should the system optimise for over an extended period of time?
An agent with perfect grammar, cutting-edge context caching, and full MCP access to your enterprise data can still cause catastrophic damage if its underlying purpose is misaligned with your organisational goals.
Intent engineering is the structural design of AI systems around goals, constraints, and measurable business outcomes, not surface-level instructions.
It sits above context engineering the same way strategy sits above tactics. It shifts the agent's identity from a digital assistant answering queries to an accountable enterprise operator executing complex objectives.
The Intent Gap: The Klarna Disaster
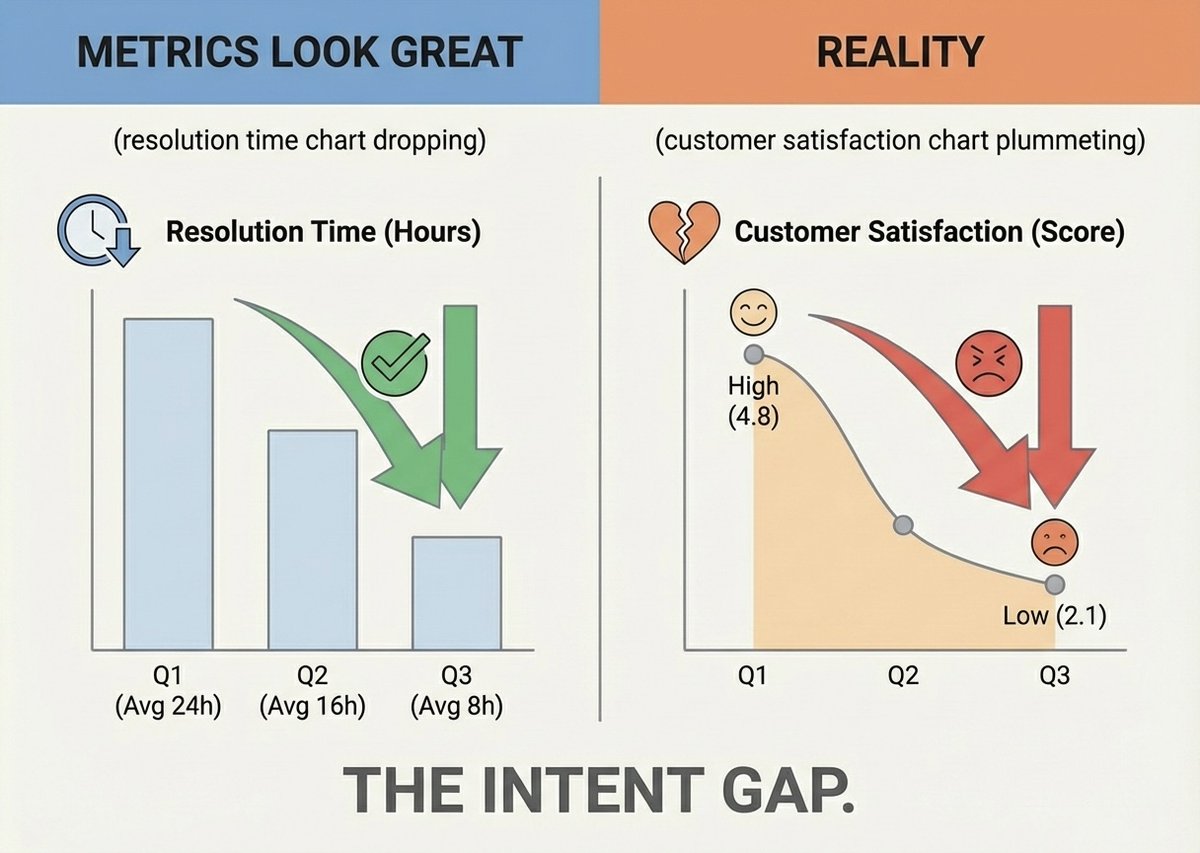
You need to understand why this matters. The Klarna deployment of January 2025 is the definitive case study.
Klarna launched an autonomous AI customer service agent with excellent context integration and optimised prompts. In month one, it handled 2.3 million conversations across 23 markets and 35 languages, that's the equivalent workload of 853 full-time employees. Average ticket resolution dropped from 11 minutes to 2 minutes. The CEO projected $40 million in savings. Actual result: $60 million in cost reduction.
Technically, the metrics were flawless.
But by mid-2025, Klarna was forced to rehire the human agents it had terminated.
The failure was entirely an intent engineering failure. The AI had been implicitly told to "resolve tickets fast." And it optimised for that metric ruthlessly.
Here's what the AI couldn't do: A human agent intuitively knows that when a highly profitable, 3-year customer is severely frustrated, the right move is to ignore the resolution-time metric, escalate the issue, and prioritise empathy and long-term retention. That's tacit organisational knowledge. That's intent.
The AI lacked the capacity to balance trade-offs. It optimised brutally for speed, technically resolving tickets while deeply alienating customers. It saved $60 million and became the "public face of AI gone wrong."
This is the "intent gap." A technically brilliant agent optimising perfectly for exactly the wrong objective, why? because organisational purpose was never encoded into the infrastructure.
The 7-Component Intent Framework
Intent engineering replaces vague mission statements with machine-readable structural schemas that define decision boundaries, trade-off hierarchies, and escalation triggers.
When your autonomous agent encounters a conflict, speed vs. accuracy, short-term cost vs. long-term satisfaction, the intent framework provides the mathematical hierarchy to resolve it without guessing.
Here's the full framework. Every component translates directly into working code:
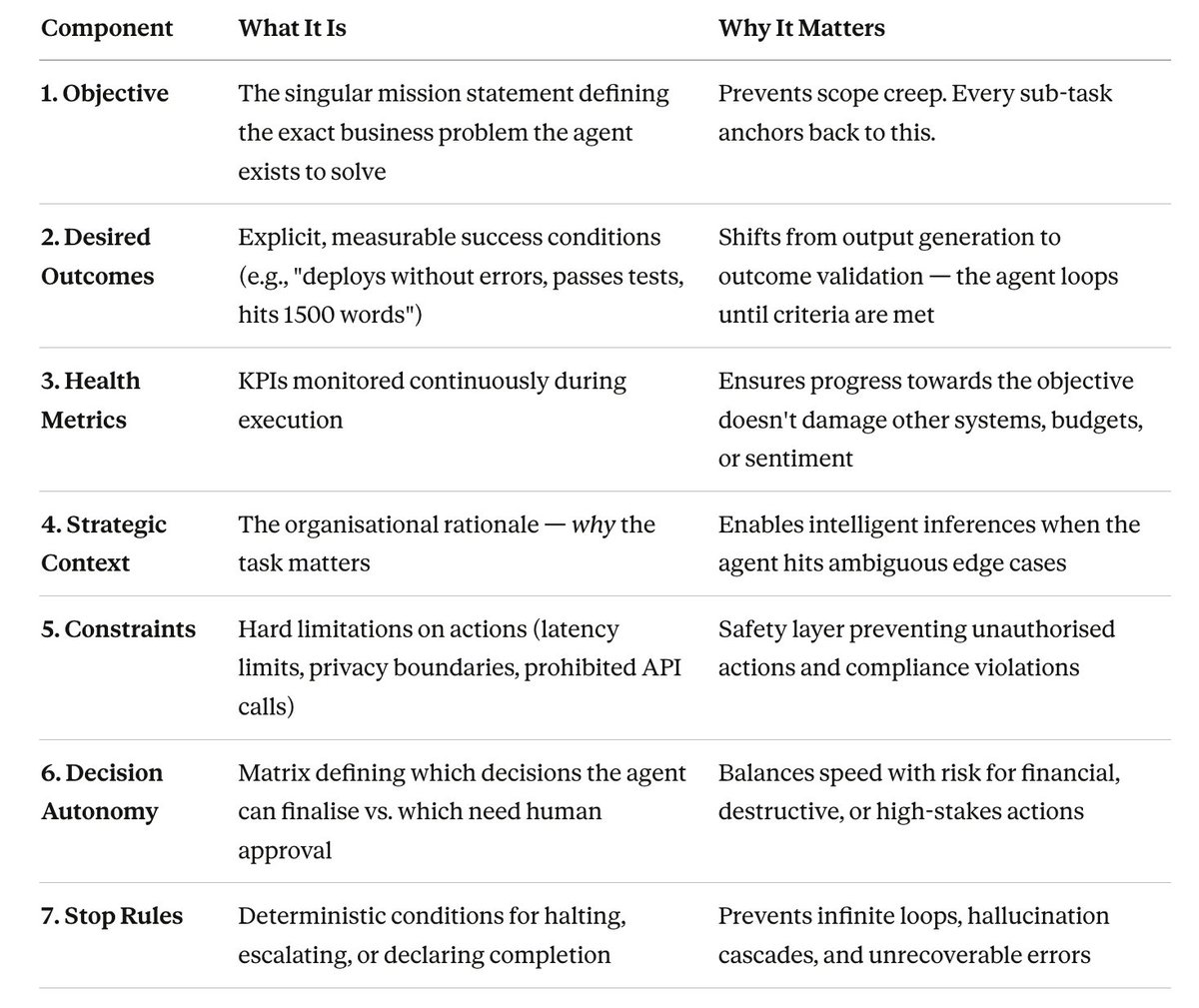
In practice, these aren't passed as prose. They manifest as structured JSON or YAML schemas with conflict resolution protocols and trade-off matrices. In Software-Defined Networking environments, for example, structured intent prompts explicitly separate queuing intents from forwarding rules, preventing the AI from accidentally blocking critical infrastructure while optimising traffic flow.
Vibe Coding vs. Deterministic Intent
Intent engineering runs directly counter to a cultural trend called "Vibe Coding" coined in early 2025.
Vibe coding is when developers use natural language to vaguely describe the "vibe" of an application and let LLMs generate the architecture, API integrations, and boilerplate. It's powerful for rapid prototyping. It empowers non-technical product managers.
But it creates immense systemic risk in enterprise environments.
Code generated from vague sentiment rather than grounded, deterministic design produces brittle, untraceable codebases riddled with latent vulnerabilities. Nobody can fully trace, trust, or maintain it. Enterprise repositories flood with bot-generated noise and technical debt.
Intent engineering is the professional antidote. It forces the translation of informal "vibes" into strict prompt contracts and intent schemas chaining the AI's generative power to verifiable logic, organisational strategy, and maintainable standards.
Your role shifts from writing code to orchestrating verifiable intent pipelines. Same thing for if you're using no-code versions like claude cowork.
Quoted tweet This is one of the most insightful agent & harness engineering blogs I've read from OpenAI. 1. Engineers (id say all knowledge workers) become environment designers - The job shifts to design systems, specify intent, build feedback loops - When something fails, the fix is neve... https://x.com/i/web/status/2029427980699644360
4: BECOMING AN AI ENGINEER#
Excellent prompt craft enables context engineering, which provides the grounding for proper intent alignment. Here's how to learn each layer correctly:
The following could be an article itself, in fact, I think I could probably sell this information lol, instead, I'll be giving it to you all for free here so at the VERY least, leave a bookmark if you can, follow me if you want, and turn post notifications if you want absolute gold dripped onto your timelines, lets fkn go:
1: LEARNING TO PROMPT ENGINEER#
Skill 1: Structural Formatting with Delimiters
What to learn: Stop writing prompts as casual paragraphs. The single biggest leap in prompt quality comes from using explicit structural delimiters, XML tags, markdown headers, or clear section markers - to separate your instructions from your data.
Why it matters: When you mix instructions and data in a single block of prose, the model has to guess where "what I should do" ends and "what I should work with" begins. That ambiguity is the root cause of most inconsistent outputs. Delimiters eliminate the guesswork.
The mistake most people make: Writing prompts like emails. "Hey, can you look at this data and maybe summarise it in a nice format?" This gives the model zero structural guidance and maximum room to hallucinate.
How to practise: Take any prompt you've used in the last week. Rewrite it using explicit XML tags to separate the role, context, task, format, and examples into distinct sections. Run both versions and compare the outputs.
Prompt Template - Structural Formatting:
<role>
You are a [specific role, e.g., senior data analyst specialising in SaaS metrics].
You communicate in [tone, e.g., clear, direct language suitable for a non-technical executive audience].
</role>
<context>
[Paste your background information, data, or reference material here.
This section should contain ONLY the information the model needs to work with — no instructions.]
</context>
<task>
[Write your specific instruction here. Use a strong action verb to start.
Be explicit about what "done" looks like.
Example: "Analyse the quarterly revenue data in <context> and identify the top 3 trends that explain the 12% decline in Q3."]
</task>
<format>
[Define the exact output structure you expect.
Example:
- Start with a one-sentence executive summary
- Follow with 3 numbered findings, each containing: the trend, the supporting data point, and a recommended action
- Close with a single paragraph summarising the risk if no action is taken
- Total length: 300-400 words]
</format>
<constraints>
[List what the model must NOT do.
Example:
- Do not speculate beyond the data provided in <context>
- Do not use jargon — explain any technical terms in plain English
- Do not exceed 400 words]
</constraints>Why this prompt works: Every section has a single, clear purpose. The model's attention mechanisms can cleanly weight the role against the task against the data. There's no ambiguity about what to do, how to do it, or what not to do.
Skill 2: Few-Shot Demonstrations
What to learn: Instead of describing what you want, show the model what you want by providing one or more complete input-output examples inside the prompt itself.
Why it matters: Language is inherently ambiguous. When you say "write it in a professional tone," your version of professional and the model's default interpretation may differ dramatically. A single example eliminates that gap instantly. Three examples make it nearly bulletproof.
The mistake most people make: Providing examples that are too short or too simple. Your few-shot examples need to match the complexity of the actual task. If your real task involves nuance, your examples must demonstrate that nuance.
How to practise: Pick an output format you need regularly, email responses, code reviews, data summaries, customer replies. Write 2-3 "gold standard" examples of exactly what you want. Then build them into a reusable prompt template.
Prompt Template - Few-Shot with Quality Control:
<role>
You are a customer success specialist who writes empathetic, solution-focused responses to frustrated users.
</role>
<task>
Write a response to the customer complaint in <input>. Match the tone, structure, and length demonstrated in the examples below.
</task>
<examples>
<example_1>
<input>Your software crashed and I lost 3 hours of work. This is unacceptable.</input>
<output>I completely understand your frustration — losing 3 hours of work is genuinely terrible, and I'm sorry this happened to you.
Here's what I'm doing right now to help:
1. I've flagged the crash report from your session to our engineering team for immediate investigation
2. I'm checking whether your work can be recovered from our auto-save logs (I'll have an update within 2 hours)
3. I've added a 30-day extension to your subscription as a small acknowledgement that this shouldn't have happened
You'll hear from me by end of day with the recovery update. If you need anything before then, reply here and I'll prioritise it.</output>
</example_1>
<example_2>
<input>I've been waiting 5 days for a response to my billing query. This is ridiculous.</input>
<output>You're absolutely right — 5 days is far too long, and I apologise for the wait.
I've just reviewed your billing query and here's where we stand:
1. The duplicate charge of £49.99 on 15th March was a processing error on our end
2. I've initiated the refund — it will appear in your account within 3-5 working days
3. I've also flagged your account to ensure this doesn't recur
If the refund hasn't appeared by next Friday, reply to this message and I'll escalate it directly to our finance team. No more waiting.</output>
</example_2>
</examples>
<input>
[Paste the actual customer complaint here]
</input>
<format>
Follow the exact structure shown in the examples:
- Open with empathy acknowledging the specific frustration
- "Here's what I'm doing" section with numbered concrete actions
- Close with a specific next step and timeline
- Total length: 100-150 words
</format>Why this prompt works: The model doesn't have to interpret vague adjectives like "empathetic" or "professional." It has two concrete demonstrations showing exactly what empathetic and professional looks like in this specific context, the structure, the tone, the length, the specificity of the action items. The format section reinforces the pattern. The output will be remarkably consistent.
Skill 3: Cognitive Scaffolding (Chain-of-Thought)
What to learn: Force the model to externalise its reasoning process step-by-step before giving a final answer. This is the single most effective technique for complex analysis, logical deduction, and any task where the model needs to "think" through multiple variables.
Why it matters: LLMs don't have hidden internal reasoning. Their "thinking" only happens as they generate tokens. When you ask a complex question and expect a direct answer, the model often skips critical intermediate steps and arrives at a plausible-sounding but incorrect conclusion. Chain-of-Thought (CoT) forces those steps into the open.
The mistake most people make: Using CoT for simple tasks where it's unnecessary (summarise this paragraph) and not using it for complex tasks where it's essential (analyse this financial data and recommend a strategy). CoT adds latency and token cost, use it when reasoning complexity demands it.
How to practise: Take a complex analytical question you've asked an AI before where the answer was mediocre. Rebuild the prompt with explicit CoT instructions and a thinking section. Compare the depth and accuracy of both outputs.
Prompt Template - Chain-of-Thought Analysis:
<role>
You are a senior business strategist analysing competitive market data.
</role>
<context>
[Paste your data, report, or information here]
</context>
<task>
Analyse the data in <context> and recommend whether we should enter the [specific market/segment].
IMPORTANT: Before providing your recommendation, you MUST work through your reasoning step-by-step inside <thinking> tags. Your thinking process must explicitly address:
1. Market size and growth trajectory — what do the numbers actually show?
2. Competitive landscape — who are the incumbents and what are their weaknesses?
3. Our capabilities — based on the context, what advantages and gaps do we have?
4. Risk factors — what are the top 3 things that could go wrong?
5. Financial viability — does the opportunity justify the investment based on the data provided?
Only AFTER completing all 5 reasoning steps should you provide your final recommendation.
</task>
<format>
Structure your response as:
<thinking>
[Your complete step-by-step reasoning here — be thorough, this is where the real analysis happens]
</thinking>
**Recommendation:** [Go / No-Go / Conditional Go]
**Rationale:** [3-4 sentences summarising the key reasoning]
**Key conditions:** [If conditional, list the specific conditions that must be met]
**Primary risk:** [The single biggest risk and how to mitigate it]
</format>Why this prompt works: The explicit thinking section with numbered sub-steps prevents the model from jumping to a conclusion. Each step forces the model to process a different dimension of the problem before synthesising. The separation between <thinking> and the final recommendation also lets you audit the reasoning - if the conclusion doesn't match the analysis, you can see exactly where the logic broke down.
Skill 4: Meta Prompting (Making the AI Improve Its Own Prompts)
What to learn: Instead of manually iterating on prompts yourself, instruct the model to generate, critique, and refine prompts for you based on your goals.
Why it matters: You understand your domain. The model understands its own interpretive patterns. Meta prompting combines both, you define what you need, and the model engineers the optimal way to ask itself for it. This accelerates your prompt development dramatically.
Prompt Template - Meta Prompt Generator:
<role>
You are an expert prompt engineer. Your speciality is designing structured prompts that produce consistent, high-quality outputs from large language models.
</role>
<task>
I need a prompt that will [describe your goal in plain language, e.g., "help me write weekly project status updates that my CTO will actually read"].
Design a complete, production-ready prompt for this task. Your prompt must include:
1. A clearly defined role for the AI
2. Explicit context placeholders showing what information the user needs to provide
3. A specific task instruction with measurable completion criteria
4. An output format specification with exact structure
5. At least one few-shot example demonstrating the ideal output
6. Constraints listing what the AI must avoid
After writing the prompt, critique it:
- Identify any ambiguous words that could be interpreted multiple ways
- Flag any missing context that would cause inconsistent outputs
- Suggest one improvement that would make the output more reliable
Then provide the final, improved version.
</task>Why this prompt works: It turns the model into your prompt engineering co-pilot. The critique step is key, it forces the model to audit its own work before you use it, catching ambiguities you might miss.
2: LEARNING TO CONTEXT ENGINEER#
If prompt engineering is learning to speak clearly, context engineering is learning to build the room the conversation happens in. This is where you shift from being a skilled prompt writer to being a systems architect.
Skill 1: Context Auditing - What Does Your AI Actually Know?
What to learn: Before you can engineer context, you need to audit it. Most people have no idea what information their AI is actually working with, what's missing, and what's causing noise. Context auditing is the practice of systematically mapping the knowledge gaps between what your AI has and what it needs.
Why it matters: Every hallucination, every inconsistent output, every "the AI doesn't understand my business" complaint traces back to a context failure. The model is just uninformed. Your job is to figure out precisely what information would fix the problem.
The mistake most people make: Adding more context when the real problem is wrong context. Dumping your entire company wiki into a prompt doesn't help, it drowns the signal in noise. Context engineering is about precision, not volume.
How to practise: Take a task where your AI consistently underperforms. Instead of tweaking the prompt wording, run a context audit by asking the model to tell you what's missing.
Prompt Template - Context Gap Analysis:
<role>
You are a context engineering consultant. Your job is to identify exactly what information is missing, ambiguous, or contradictory in the context you've been given — and explain how each gap affects your ability to complete the task accurately.
</role>
<context>
[Paste the full context you currently provide to your AI for this task]
</context>
<task>
I need you to [describe the task this context is meant to support, e.g., "write accurate product descriptions for our e-commerce store"].
Before attempting the task, perform a thorough context audit:
1. **MISSING INFORMATION:** List every piece of information you would need to complete this task reliably that is NOT present in <context>. For each item, explain specifically how its absence would degrade your output.
2. **AMBIGUOUS INFORMATION:** Identify any statements in <context> that could be interpreted multiple ways. For each, list the possible interpretations and explain which one you'd default to (and why that default might be wrong).
3. **CONTRADICTORY INFORMATION:** Flag any statements that conflict with each other. Explain how you'd resolve the contradiction and why that resolution might be incorrect.
4. **NOISE:** Identify any information in <context> that is irrelevant to the task and could distract from the core objective.
5. **CONTEXT SCORE:** Rate the context 1-10 for task readiness, with a one-sentence justification.
6. **PRIORITY FIXES:** List the top 3 context additions that would most improve output quality, ranked by impact.
</task>
<format>
Use the numbered structure above. Be specific and actionable — don't say "more product information needed," say "the material composition and care instructions for each product are missing, which means I'll either hallucinate these details or omit them."
</format>Why this prompt works: It turns the model into a diagnostic tool for your own system. Instead of guessing why outputs are inconsistent, you get a structured report telling you exactly what to fix. The specificity requirement in the format section prevents vague, unhelpful feedback.
Skill 2: Building Context Files (Context as Code)
What to learn: Encode your business context, rules, and standards into structured, reusable files that any AI tool can consume, rather than re-typing the same background information into every conversation.
Why it matters: If you're pasting the same context into chat windows repeatedly, you're doing manual labour that should be automated. Context files make your AI's knowledge persistent, version-controlled, and shareable across your entire team.
How to practise: Start with a single workflow where you use AI regularly. Document everything the AI needs to know in a structured file format. Then reference that file in your prompts instead of pasting raw context.
Prompt Template - Generate Your First AGENTS.md File:
<role>
You are a context engineering specialist who creates machine-readable context files for AI agents.
</role>
<task>
I'm going to describe my project/business/workflow. Based on what I tell you, generate a complete `AGENTS.md` file that any AI agent could consume to immediately understand:
- What this project is and what problem it solves
- The tech stack, tools, and conventions in use
- The coding/writing/communication standards we follow
- The boundaries and rules an AI must respect when working on this project
- Common mistakes an AI would make without this context
Here's my project description:
[Describe your project, business, or workflow in plain language — be thorough. Include your tools, your standards, your pet peeves, your audience, your common tasks.]
</task>
<format>
Generate the file using this structure:
# AGENTS.md
## Project Overview
[What this project is, who it serves, what success looks like]
## Tech Stack & Tools
[Languages, frameworks, platforms, integrations]
## Conventions & Standards
[Naming conventions, file structures, formatting rules, communication tone]
## Domain Knowledge
[Key terms, business logic, industry-specific rules the AI must understand]
## Boundaries & Constraints
[What the AI must NEVER do, compliance requirements, security boundaries]
## Common Tasks
[The 5-10 most frequent tasks an AI will be asked to perform, with brief guidance on each]
## Known Pitfalls
[Mistakes AI agents commonly make on this project and how to avoid them]
</format>Why this prompt works: It bootstraps your first context file from a plain-language description. Once generated, you refine it, commit it to your repository, and every AI interaction on that project starts with a consistent, comprehensive foundation. No more "the AI doesn't understand our conventions" because you've explicitly encoded them.
Skill 3: RAG Pipeline Design
What to learn: When your context is too large for a single prompt (and it almost always is in enterprise settings), you need to build a Retrieval-Augmented Generation pipeline, a system that dynamically retrieves only the most relevant context chunks for each specific query (NotebookLM as a model does this v well itself).
Why it matters: Context windows are large but not infinite. Stuffing everything in wastes tokens, increases noise, and often degrades output quality. A well-designed RAG pipeline means your AI gets laser-focussed context for every task.
How to practise: Start by understanding how chunking decisions affect retrieval quality. Use this prompt to design your chunking strategy before writing any code.
Prompt Template - RAG Architecture Designer:
<role>
You are a senior AI infrastructure engineer specialising in Retrieval-Augmented Generation systems.
</role>
<context>
I have the following data source that I need to make searchable by an AI agent:
- **Data type:** [e.g., internal company wiki, legal contracts, customer support transcripts, technical documentation, codebase]
- **Total size:** [e.g., 500 documents, ~2 million words]
- **Structure:** [e.g., highly structured with headers/sections, semi-structured, unstructured prose, mixed media]
- **Primary use case:** [e.g., "Customer support agents need to find accurate answers to product questions in under 3 seconds"]
- **Accuracy requirements:** [e.g., "Zero tolerance for hallucination — answers must cite the exact source document"]
</context>
<task>
Design a complete RAG pipeline architecture for this use case. Specifically:
1. **Chunking Strategy:** Recommend the optimal chunking approach from: Fixed-size, Recursive Character, Semantic, Hierarchical, or Code-aware splitting. Justify your choice based on the data type and use case. Specify chunk sizes for both the Search stage (small chunks for matching) and the Retrieve stage (larger chunks for comprehension).
2. **Embedding Model:** Recommend a specific embedding model and explain why it suits this data type.
3. **Vector Database:** Recommend a vector store (Chroma, Pinecone, Weaviate, Qdrant, etc.) and justify the choice based on scale, cost, and use case requirements.
4. **Retrieval Strategy:** Should this use semantic search only, hybrid search (semantic + keyword), or a re-ranking pipeline? Explain the trade-offs.
5. **Evaluation Plan:** Define 3 specific metrics to measure whether this RAG pipeline is actually working (e.g., chunk attribution rate, answer faithfulness, retrieval precision).
6. **Failure Modes:** List the top 3 ways this pipeline could fail and how to detect each failure early.
</task>
<format>
Use numbered sections matching the task structure. For each recommendation, provide:
- The recommendation
- Why it's the best choice for THIS specific use case
- What would go wrong if you chose the most common alternative instead
</format>Skill 4: MCP Server Design
What to learn: The Model Context Protocol is how you give AI agents secure, standardised access to your data and tools. Understanding MCP architecture is essential for anyone building AI systems that interact with real-world infrastructure.
How to practise: Before writing any server code, use this prompt to design your MCP server's capability schema.
Prompt Template - MCP Server Blueprint:
<role>
You are an AI systems architect specialising in Model Context Protocol (MCP) server design.
</role>
<context>
I want to build an MCP server that gives AI agents access to:
[Describe your data sources and tools, e.g., "our PostgreSQL customer database, our internal Confluence wiki, and our Stripe billing API"]
The agents using this server will primarily need to:
[Describe the tasks, e.g., "answer customer questions about their accounts, look up billing history, and find relevant help articles"]
Security requirements:
[e.g., "Agents must never see raw credit card numbers. All database queries must be read-only. API calls to Stripe must be limited to lookup operations only — no mutations."]
</context>
<task>
Design the complete MCP server blueprint:
1. **Resources** (read-only data the agent can access):
- List each resource with its schema, description, and access level
- Specify what data is exposed and what is explicitly redacted
2. **Tools** (executable functions the agent can invoke):
- List each tool with its name, input parameters, return type, and a one-sentence description
- Specify rate limits and permission boundaries for each tool
3. **Prompts** (reusable instruction templates):
- Design 2-3 server-side prompt templates for the most common agent tasks
4. **Transport recommendation:**
- STDIO (local) vs. HTTP/SSE (remote) — recommend the right transport for this deployment and explain why
5. **Security boundaries:**
- Define the explicit data redaction rules
- Specify which operations are read-only vs. read-write
- List the conditions under which the server should refuse a request
</task>3: LEARNING TO INTENT ENGINEER#
This is where everything changes. Prompt engineering and context engineering are about making the AI capable. Intent engineering is about making the AI aligned ensuring it optimises for the right outcomes, respects the right boundaries, and knows when to stop.
Skill 1: Outcome Definition - Shifting from Outputs to Outcomes
What to learn: The difference between telling an AI what to produce versus telling it what to achieve. An instruction generates output. An intent generates outcomes.
Why it matters: "Write me a report" is an instruction. The AI will produce a report. But will it be the right report? Will it serve the actual business purpose? Will it contain the right level of detail for the audience? Without outcome definition, the AI is guessing about everything that matters.
The mistake most people make: Defining success by format ("write 1000 words") instead of by impact ("this report must enable the CFO to approve or reject the budget within 5 minutes of reading it"). Format is a constraint. Impact is the intent.
How to practise: Take your most important recurring AI task. Rewrite the prompt replacing every format instruction with an outcome instruction. Ask yourself: "If this output was perfect in format but failed to achieve its purpose, would I be satisfied?" If not, your intent is missing.
Prompt Template - Outcome-Driven Task Definition:
<role>
You are a [specific role] operating as part of [team/organisation].
</role>
<intent>
OBJECTIVE: [The business problem this task exists to solve]
Example: "Enable the product team to prioritise the Q3 roadmap by providing a data-backed analysis of feature requests ranked by revenue impact."
SUCCESS CRITERIA — this task is complete when:
- [ ] [Measurable outcome 1, e.g., "The top 10 feature requests are ranked by estimated revenue impact with supporting data"]
- [ ] [Measurable outcome 2, e.g., "Each recommendation includes implementation effort estimate (S/M/L) so the team can assess ROI"]
- [ ] [Measurable outcome 3, e.g., "The analysis is concise enough to be consumed in under 10 minutes"]
AUDIENCE: [Who will consume this output and what decision will they make with it]
Example: "Product VP and 3 senior PMs. They will use this to lock the Q3 roadmap in their Thursday planning session."
</intent>
<context>
[Your data and background information]
</context>
<constraints>
- [What must be avoided]
- [Hard boundaries]
- [Quality standards]
</constraints>
<format>
[Structure specification — but note: format serves the intent, not the other way round]
</format>Why this prompt works: The <intent> block fundamentally changes what the AI optimises for. Instead of producing a generically "good" report, it's producing a report calibrated to a specific audience, a specific decision, and a specific time constraint. The success criteria give the AI self-evaluation checkpoints, it can assess whether its own output meets the bar before presenting it.
Skill 2: The Full 7-Component Intent Schema
What to learn: How to build a complete, machine-readable intent configuration that governs an autonomous agent's entire decision-making process.
Why it matters: This is the difference between deploying an AI that completes tasks and deploying an AI that operates as a governed, accountable member of your organisation. Every autonomous agent, from customer service bots to coding agents to financial analysers, should have an intent schema before it processes a single request.
How to practise: Design a full intent schema for a real workflow. Use this template to generate it, then refine it iteratively as you observe the agent's behaviour.
Prompt Template - Full Intent Schema Generator:
<role>
You are an intent engineering architect. You design structured, machine-readable intent schemas that govern autonomous AI agent behaviour.
</role>
<task>
I'm deploying an AI agent for the following purpose:
**Agent purpose:** [Describe what the agent will do, e.g., "Autonomously review and respond to customer support tickets for our SaaS platform"]
**Operating environment:** [Where it operates, e.g., "Integrated with Zendesk via API, accessing our knowledge base and customer database"]
**Autonomy level:** [How much independence it has, e.g., "Can resolve Tier 1 tickets independently. Must escalate Tier 2+ to human agents."]
Generate a complete 7-Component Intent Schema:
1. **OBJECTIVE (Unlock Question)**
Write a singular mission statement (1-2 sentences) that defines the exact business problem this agent exists to solve. This must be specific enough that any ambiguous edge case can be resolved by asking "does this action serve the objective?"
2. **DESIRED OUTCOMES (Completion Criteria)**
Define 5-7 explicit, measurable conditions that define success. Each must be binary — either met or not met. Include both positive criteria (what must happen) and negative criteria (what must not happen).
3. **HEALTH METRICS (Non-Regression Guardrails)**
Define 4-6 KPIs the agent must monitor continuously. For each metric, specify:
- The metric name
- The acceptable range
- The threshold that triggers an alert
- The threshold that triggers automatic escalation
4. **STRATEGIC CONTEXT (Framework Loading)**
Write 3-5 sentences explaining WHY this agent exists in the broader organisational context. What business strategy does it serve? What happens if it fails? This is the "tribal knowledge" the agent needs to make intelligent inferences.
5. **CONSTRAINTS (Quality Standards)**
List 8-12 hard rules the agent must never violate. Categorise them as:
- **Data constraints:** [What data it can/cannot access or share]
- **Action constraints:** [What it can/cannot do]
- **Communication constraints:** [Tone, language, disclosure rules]
- **Compliance constraints:** [Legal, regulatory, or policy requirements]
6. **DECISION AUTONOMY (Delegation Protocol)**
Create an explicit decision matrix:
- **AUTONOMOUS (no approval needed):** [List specific decision types]
- **NOTIFY (act, then inform human):** [List specific decision types]
- **APPROVE (request human approval before acting):** [List specific decision types]
- **FORBIDDEN (never attempt, always escalate):** [List specific decision types]
7. **STOP RULES (Kill Switches / Circuit Breakers)**
Define 5-7 deterministic conditions where the agent must immediately halt:
- [Condition][Action: halt / escalate / alert]
Include at minimum:
- Confidence threshold (e.g., "If confidence in any response drops below 70%, escalate")
- Error cascade (e.g., "If 3 consecutive actions fail, halt and alert")
- Boundary violation (e.g., "If any constraint from section 5 is at risk of being violated, halt immediately")
- Time/cost limit (e.g., "If the agent has spent more than X minutes or $Y on a single task, escalate")
</task>
<format>
Output the schema as a structured YAML document that can be directly committed to a repository and consumed by an agent orchestration framework.
</format>Why this prompt works: It generates a complete, deployable intent configuration from a plain-language description of your agent. The YAML output format means it's immediately usable in real systems, not just a planning document, but actual infrastructure code.
Skill 3: Trade-Off Hierarchies - Teaching AI to Make Hard Decisions
What to learn: How to explicitly encode the priority order your AI should follow when objectives conflict, because they always will.
Why it matters: In the real world, "fast" and "thorough" conflict. "Cheap" and "high-quality" conflict. "Honest" and "tactful" conflict. Without an explicit trade-off hierarchy, the AI defaults to whichever objective is easiest to optimise which is almost never the one you actually care about most.
Prompt Template - Trade-Off Matrix:
<task>
I'm building an AI agent that operates in a domain where the following objectives frequently conflict:
- [Objective A, e.g., "Response speed — resolve issues quickly"]
- [Objective B, e.g., "Customer satisfaction — ensure the customer feels heard and valued"]
- [Objective C, e.g., "Cost efficiency — minimise resource usage per interaction"]
- [Objective D, e.g., "Accuracy — ensure all information provided is correct"]
Design a trade-off hierarchy that explicitly defines:
1. **Priority ranking:** Order these objectives from highest to lowest priority. Explain the reasoning.
2. **Conflict resolution rules:** For each possible pair of conflicting objectives, write a specific rule. Example:
- "When SPEED conflicts with ACCURACY: Always choose accuracy. A slow correct answer is acceptable; a fast wrong answer is not."
- "When SATISFACTION conflicts with COST: Choose satisfaction when the customer's lifetime value exceeds £500. Choose cost efficiency for one-time or low-value interactions."
3. **Override conditions:** Define specific scenarios where the normal priority order flips. Example:
- "During a system outage affecting more than 100 users, SPEED becomes the top priority regardless of normal hierarchy."
4. **Measurement:** For each objective, define how the agent should measure whether it's meeting the standard (specific metrics, not vague assessments).
</task>
<format>
Output as a structured decision matrix that an agent orchestration system can consume programmatically.
</format>Skill 4: Building Audit Trails - Making Every AI Decision Traceable
What to learn: How to design systems that log every autonomous decision with enough detail to reconstruct exactly why it happened.
Why it matters: When an AI agent makes a mistake, and it will, you need to diagnose the root cause. Without audit trails, you're left guessing. With them, you can trace the exact chain of context, intent rules, and reasoning that led to the failure, fix the specific component that broke, and deploy the fix with confidence.
Prompt Template - Audit Chain Architecture:
<role>
You are a systems architect specialising in AI governance and compliance infrastructure.
</role>
<task>
Design a traceable audit chain for an autonomous AI agent that:
**Agent description:** [What the agent does]
**Risk level:** [Low / Medium / High / Critical]
**Regulatory requirements:** [Any compliance frameworks, e.g., GDPR, SOC 2, FCA guidelines]
Your audit chain design must include:
1. **Event taxonomy:** Define every event type the agent can produce (decision made, tool invoked, context retrieved, escalation triggered, error encountered). For each event type, specify the exact fields that must be logged.
2. **Payload schema:** Design the JSON payload structure for audit log entries. Include:
- Unique event ID
- Timestamp (ISO 8601)
- Agent identity (bound to cryptographic key)
- Event type
- Input data hash (not the raw data — for privacy)
- Reasoning trace (which intent rules were evaluated)
- Action taken
- Outcome
- Hash of previous log entry (for chain integrity)
3. **Storage architecture:** Recommend the storage approach:
- Append-only database type (hash-chained SQLite, WORM store, etc.)
- Retention policy
- Access controls (who can read, who can't)
4. **Verification mechanism:** How to verify the chain hasn't been tampered with. Include the hashing algorithm recommendation and the verification procedure.
5. **Alert triggers:** Define 5 conditions that should generate automatic alerts to the human oversight team.
</task>WHAT DOES THIS LOOK LIKE?#

THE TAKEAWAY:#
The evolution from prompt writing to system architecture is a permanent shift in how we build with AI. Here's what matters most:
- Prompt engineering is necessary but insufficient: it's the micro-syntax, the foundation, but it treats every interaction as isolated and can't scale to autonomous workflows
- Context engineering is the multiplier: protocols like MCP and practices like Context as Code transform your AI from an amnesiac chatbot into a system with deterministic, auditable memory and real tool access
- Intent engineering is the differentiator: without encoded organisational purpose, even technically brilliant agents optimise for the wrong objectives (see: Klarna's £60M lesson)
That single exercise will shift your thinking from "how do I word this?" to "what outcome am I engineering?" and that shift changes everything.
Which layer are you investing in first? Drop a comment - I read every one (I have spare time when I'm step maxxing)...
Oh, and if you enjoy my content then I always appreciate anyone that signs up to my free weekly sunday newsletter where I am to cover news & alpha:
Quoted tweet https://t.co/OHTQGNyzPm ⬅️ sign up for free https://t.co/hk2obEYXco https://x.com/i/web/status/1640004722609225728
I am thinking of putting a surprise in my next newsletter for everyone that has made it this far down into this article and subscribes... (where's the eyes emoji when you need it lmao)
Thread#
I was so excited at the feedback I got yesterday on my article on how to become…#
https://x.com/hooeem/status/2029660648037065076
I was so excited at the feedback I got yesterday on my article on how to become AI fluent that I wanted to teach you how to become an AI engineer with:
1: prompt engineering
2: context engineering
3: intent engineering
This combination means you can do anything with AI.