Beginner
Don't Build a Thousand Agents: How Ramp Handles Financial Automation with One Agent
Don't Build a Thousand Agents: How Ramp Handles Financial Automation with One Agent
Don't Build a Thousand Agents: How Ramp Handles Financial Automation with One Agent#
Ramp is one of the fastest-growing corporate financial platforms in the US, valued at $32 billion, with over 50,000 customers and processing over $100 billion in annual transaction volume. At The Pragmatic Summit, Ramp sent a team of four to share their practical experience in AI over the past year: EVP of Engineering Nik Koblov, Director of Applied AI Viral Patel, and Staff Engineers Will Koh and Ian Tracey.
They discussed five things: why they shifted from "building a bunch of agents" to "one agent + a thousand skills," the journey of the Policy Agent from zero to launch, how to define "correctness," how to build internal AI infrastructure, and an internal coding agent that generates over 50% of merged PRs.
Original video link: https://www.youtube.com/watch?v=NMs8C2_3M0w
Key Takeaways#
- Last year, Ramp let teams freely experiment with agents, resulting in four different implementations and five conversational interfaces. They concluded they should converge to an architecture of "one agent + a thousand skills."
- The biggest source of error for the Policy Agent isn't the model itself, but insufficient context provided to the model. Context like employee level, receipt details, and merchant information is more impactful than switching models.
- User approval behavior cannot be used as the standard for "correctness." Ramp built a cross-functional team to label data weekly to define their own ground truth.
- Ramp's internal coding agent "Inspect" generated over 50% of merged PRs last month, with users including non-engineering teams like product, design, legal, and marketing.
- The value of engineers in the AI era isn't coding speed, but judgment: knowing what to build and knowing where the AI-built things are wrong.
The 15 Minutes Behind a Cup of Coffee#
Nik Koblov opened with a scenario everyone can understand: a coffee purchase.
Buying a cup of coffee takes about 15 minutes of administrative time in a traditional process. Writing notes, categorizing it according to the company's chart of accounts, finding and attaching the receipt, normalizing the merchant name into the company's merchant library. These tasks accumulate at the company level.
Nik Koblov used "a cup of coffee" to explain the often-overlooked manual process costs in corporate finance.

What Ramp does, in the simplest terms, is compress those 15 minutes to near zero. From swiping the card to writing notes, categorization, and receipts, everything is automated by an Agent. This is something Ramp started doing about three years ago, initially using AI for single-step processing, like normalizing merchant names or auto-writing notes. As model capabilities improved, the results got better.
But this was just the beginning. Almost every role on the Ramp platform does a lot of manual work: AP specialists process invoices, finance teams reconcile accounts, procurement teams compare prices, data teams run reports. Nik mentioned a detail: Ramp used to have a Slack channel called
help-data, where people would request data and someone would write SQL queries. This channel was replaced by AI about a year and a half ago.From card expenses and procurement to closing the books and analysis, Ramp aims to hand over these fragmented tasks scattered across teams to Agents.
Don't Build a Thousand Agents#
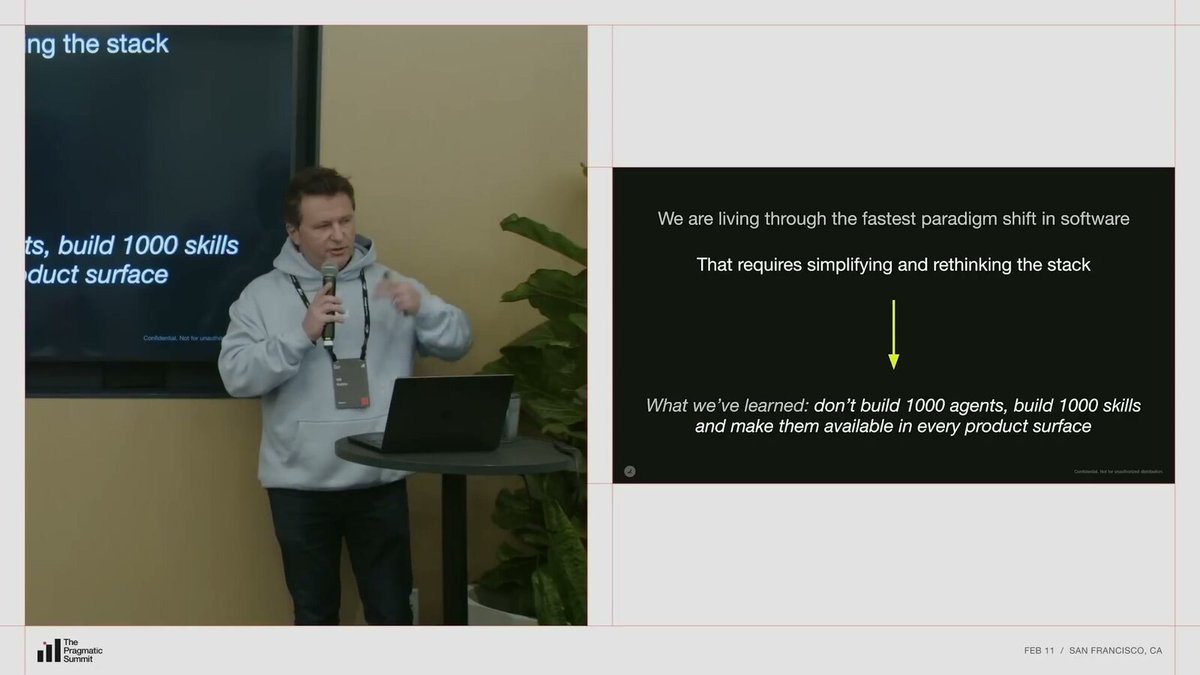
Nik said Ramp is experiencing the most exciting paradigm shift in the software industry regarding AI. This shift requires a complete rethink and also means simplifying the tech stack.
The lesson they learned is:
> You don't need to build a thousand agents. Instead you want to drive your framework towards a single agent with a thousand skills.
Ramp's architectural judgment is straightforward: converge agents, expand skills.
Last year, Ramp intentionally let teams experiment freely. They found about four different ways of doing the same thing internally, with several implementations each for synchronous and background agents. At the same time, conversational interfaces ballooned to five.
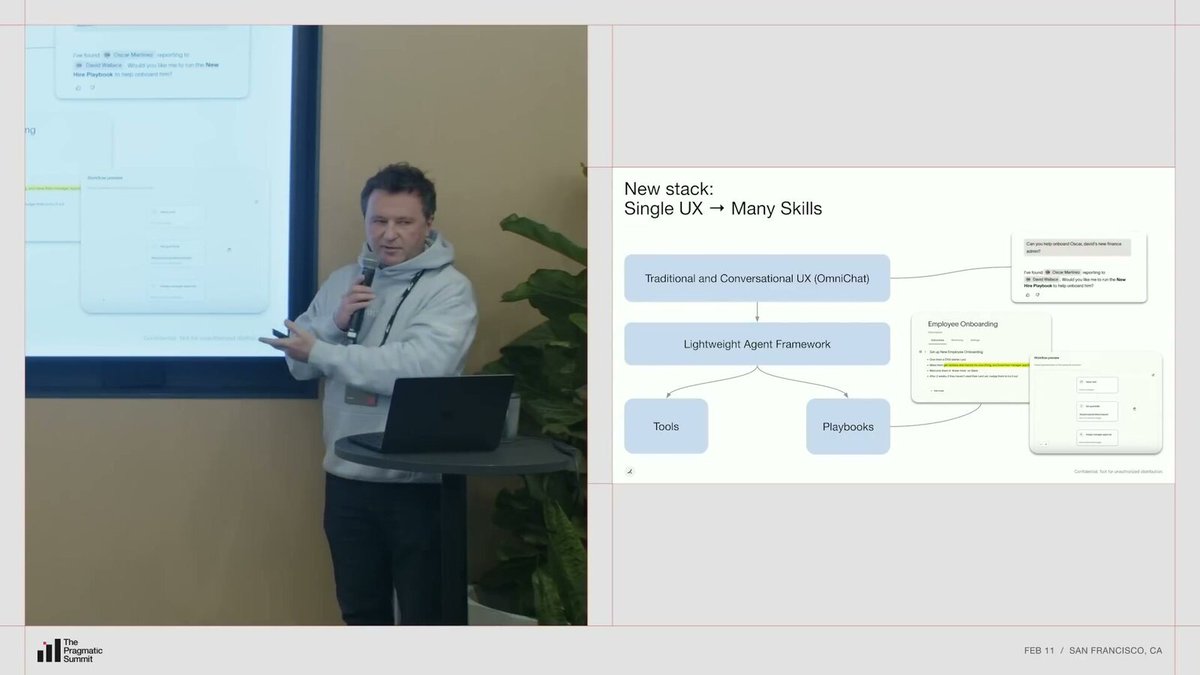
Now Ramp is converging all conversational interactions into a unified interface called Omnihat. "Omni" suggests omnipresence, and it's being deployed on every product interface. It works alongside traditional UX because you don't always want to "talk" to software; sometimes tables and buttons are enough.
Nik showed an example: typing "Please help me onboard a new employee" in Omnihat. The Agent automatically parses the employee ID, queries the organizational structure via an HRIS tool, then finds a previously created workflow "New Employee Onboarding Handbook" and asks if you want to use this process for onboarding.
Behind this is a lightweight Agent framework built by Ramp, providing orchestration capabilities and tools. Engineers can quickly build new tools. Recently, a product manager built about 20 tools through vibe coding, completely without engineer involvement.
A unified conversational entry point, a lightweight framework, and a tool layer constitute what Ramp calls "one agent + a thousand skills."
For complex processes, like employee onboarding involving four steps (issuing a card, setting receipt requirements, welcoming on Slack, following up after two weeks), users can describe the desired process in natural language on Ramp. The system compiles it into a runnable deterministic workflow, then hands it to the Agent for execution.
Expense Policy is "Code"#
Ramp's Policy Agent is one of their most popular Agent products.
Viral Patel took over, first showing a real scenario: finance teams review hundreds or thousands of receipts daily. He held up a receipt and said if he had to judge by eye whether this transaction should be approved or rejected, he'd probably get it wrong.
But the Policy Agent reasoned about this receipt: identified 8 guests (Viral said he could barely see the number), confirmed it was below the company's internal per-person $80 limit, judged it was a team welcome dinner, and recommended approval. Another transaction for OpenAI, where an employee was testing ChatGPT features, was judged by the Policy Agent as a reasonable business expense and approved. A $3 bakery purchase was rejected because it wasn't for overtime work or on a weekend.
The product philosophy behind these cases came from an opportunity: a Fortune 500 client approached Ramp with a long list of rules saying, "Help us approve and reject according to these."
The Policy Agent doesn't just read rules; it also coordinates with other Agents like accounting and bookkeeping to actually implement decisions in the system.

Ramp could have continued down the old path, hardcoding these rules as deterministic logic, adding them one by one into the product. But they chose a different direction. Viral quoted Andrej Karpathy: English is the new programming language. They decided to make the expense policy document itself the rules, letting the Agent directly read and execute based on natural language policy documents.
[Note: Andrej Karpathy is an OpenAI co-founder and former Tesla AI head. "English is the hottest new programming language" is a tweet he posted in 2023, later becoming a signature quote of the AI era.]
[Note: Ramp's official data shows that as of October 2025, the Policy Agent made over 26 million decisions on over $10 billion in spending, blocked 510,000 non-compliant transactions, and saved approximately $290 million.]
AI Products Can't Be One-Shotted#
Viral and Will Koh both emphasized a core lesson:
> AI products cannot be one-shotted. You need to start with something simple.
Viral believes this is a cultural consensus: product managers, designers, and engineers must all accept that day one won't be perfect.
They initially wanted to go big, "Let's automate the entire finance review." But when they actually started, they chose the smallest entry point: reimbursing a cup of coffee. These small, single transactions are low-risk, and finance teams don't care much about them.
Ramp minimized the first step: first solve a high-frequency, low-risk, but annoying approval scenario.

Ramp did a lot of internal dogfooding first, using the company's internal transaction data to train and test the Policy Agent.
A key discovery changed their thinking:
> A lot of the reason that policy agent would be wrong would be less on the models themselves and more about the context that we were giving to LLMs.
They could have sat down initially to figure out all the needed context, but they found the best way was to learn from actual internal data. For example, they found that an employee's level and title significantly impact expense approval. C-level executives (CEO, CFO, etc.) might have higher spending limits and can fly business class. If this information isn't included in the context, the Agent makes wrong judgments.
So they started extracting more information from receipts, pulling in employee profiles from HRIS systems. Every time they discovered a new contextual dimension, they added it and observed the effect.
From Simple Pipeline to Agentic Autonomous Loop#
Will detailed the three evolutionary stages of the Policy Agent architecture.
The first stage was simple: an expense comes in, retrieve relevant context, pass it through a series of well-defined LLM calls to judge "is it compliant," "why is it compliant," "how to show the compliance reason to the user," then output the result.
The second stage introduced conditional branching. They found each expense type differed greatly: travel, meals, entertainment each had different judgment logic. So they added expense categorization, conditional prompts and context retrieval based on type, and gave the LLM some tools so it could autonomously decide "I need to check flight info" or "I need to check this employee's level."
After several iterations, they reached the third stage: a fully agentic workflow. The Agent can read all data on the Ramp platform and has a shared internal toolbox (not just for the Policy Agent, all Agents can use it). It now doesn't just read, but can also write: write approval decisions, write reasoning, directly approve expenses for users. And it works in a loop, able to call tools multiple times, gather information, and make judgments.
This slide is essentially Ramp's methodology: start with a simple pipeline, then gradually add conditional branching, tools, and autonomous loops.
Will admitted this brings a classic trade-off: capability and autonomy increase, but traceability and explainability decrease. A small black box becomes a big black box. You can look at reasoning tokens, but essentially you can't control what it will do.
Users Aren't Always Right#
Since the black box is growing, auditability becomes especially important. Will proposed a principle: even if you know how the system works internally, assume you can only see inputs and outputs, then verify if the output is correct.
But this leads to a more fundamental question: what is "correct"?
> Turns out the users are actually incorrect. They're wrong.
Initially, they thought user behavior was the standard answer: if a user approved, the Agent should approve; if a user rejected, the Agent should reject. But in reality, many users don't understand company expense policies, some trust subordinates too much and don't scrutinize, some approve on weekends and just click through. Finance teams would later come back and say, "This shouldn't have been allowed."
So Ramp had to establish its own definition of correctness. Their approach was to hold weekly cross-functional data labeling meetings, involving engineers, PMs, designers, etc.
Ramp removed "user actions" from the answer and instead used cross-functional labeling to define their own ground truth.

This brought two benefits. First, they had a benchmark dataset they could continuously test against, confident these labels were correct. Second, everyone aligned their understanding. If the Agent was wrong, everyone knew where; if the Agent lacked context, everyone knew what was missing. This reduced communication overhead, allowing the team to quickly focus on real priorities.
Using Claude Code to Build the Labeling Tool in One Go#
But gathering a group weekly and having them label 100 data points is costly. Will said everyone has their own work, and sometimes people come to meetings without finishing their "homework."
So they wanted to make the labeling process as simple as possible. They looked at third-party tools first, finding some too specialized, others too generic, and just trying different tools would take weeks. So they decided to build their own.
Using Claude Code and Streamlit, they basically built the entire labeling tool in one go. The biggest advantage was low maintenance cost and low risk. It sits in an isolated corner of the codebase and can be fixed immediately if broken. Deployment is almost instant. Non-engineers can also modify it, directly vibe coding.
Ramp didn't dwell on the labeling platform for too long; instead, they used Claude Code and Streamlit to first build a working internal tool.

[Note: Streamlit is an open-source Python framework for quickly building web interfaces for data applications.]
Eval Starts with 5 Samples#
With a ground truth dataset, iteration speed increased dramatically. Found a need for employee level information? Add it, run through the dataset, see if it correctly captures new scenarios.
Will said he thinks the concept of eval is now widely known, but he wanted to emphasize "do it early." Don't aim for perfection; you don't need 1000 data points from the start. They started with 5, ensuring these 5 would absolutely not be wrong, then kept accumulating.
A few practical points: ensure anyone can easily run the eval command, ensure results are clear at a glance (good vs. bad easily distinguishable), integrate it into CI so it runs automatically with every code merge.
Ramp's eval system isn't "build big first," but first enabling the team to run repeatedly, dare to switch models, dare to continuously add context.

Giving LLMs more context and more tools often brings unexpected side effects. Context rot (too much context degrading model performance), vague or contradictory tool descriptions—these issues can't be discovered without running evals.
Online evaluation (online eval) also has value. They have an "uncertain" decision type, meaning the Agent believes there's insufficient information to make a judgment. Monitoring changes in this ratio is a simple but effective system health indicator.
Also, with a robust eval system, switching models becomes confident. Whenever a new model is released, run the eval to know whether to switch. New models might improve some problems but worsen others. Without eval, you wouldn't dare to change.
Let Users Modify Their Own "Claude.md"#
After the Policy Agent launched, Will shared a discovery: when engineers use Claude Code, they can modify the
Claude.md file to control Agent behavior. Finance personnel actually have the same need, but their "Claude.md" is the company's expense policy document.[Note:
Claude.md is the project configuration file for Claude Code, where developers can write project conventions and preferences to guide the AI's behavior.]If the Policy Agent's decision is wrong, Ramp's suggestion is: "Go update your expense policy document." This was initially intimidating for finance personnel. Expense policies are formal documents, not casually editable; changes require approval processes.
But once they saw immediate effects after modification, their attitude completely reversed. This instant feedback loop excited them.
Ramp's product feedback loop resembles engineers tuning an Agent: write strategy into the document, see immediate changes in system behavior after modification.
Trust building happens in stages. Ramp started by pushing to large Fortune 500 clients first, because these enterprises have the highest expense volume, deepest approval pain, and can most intuitively feel the product value. Initially, they only provided "recommendations," no automatic actions.
Then clients themselves approached and said: "For transactions under $20, your judgments are basically always right. I don't want to look at them anymore; let me auto-approve them directly."
So Ramp gave them an "autonomy slider," letting clients decide how far to automate. Trust isn't designed by product managers; it's built by users through usage.
Will made an analogy: just as LLMs can get feedback loops and iterate by testing code, users need the same feedback loop within the product. Give them tools to modify policy documents and adjust Agent behavior, and they'll be more proactive and engaged than you expect.
Let Model Switching Require Just One Line of Configuration#
Ian Tracey took over the infrastructure part. He said a core question Ramp is thinking about is: how to get leverage for Ramp itself? Not just for customers, but also for internal engineers and cross-functional teams.
The core of Ramp's internal AI is a service called Applied AI Service. At a high level, it's like an LLM proxy, similar to unified interface tools like LiteLLM, but with three important extensions.
[Note: LiteLLM is an open-source tool that lets developers call different LLM providers (OpenAI, Anthropic, Google, etc.) with a unified API.]
First, unified structured output and a consistent API/SDK across model providers. Different model providers' APIs change rapidly; Ramp doesn't want downstream product teams worrying about these. If you want to switch from GPT-5.3 to Opus, or try Gemini 3 Pro, change one line of configuration, and you can immediately run semantic similarity tests or sandbox experiments.
Applied AI Service encapsulates all the underlying hassles: model switching, structured output, batch processing, and cost governance.

Second, batch processing and workflows. For scenarios like batch document analysis or eval, how to handle rate limits, choose online vs. offline tasks—downstream teams don't need to consider these.
Third, cross-team and cross-product cost tracking. This lets them identify the Pareto curve of performance and cost (finding the optimal balance between performance and cost): which model offers the best cost-performance for what? Which teams' usage patterns are unsustainable long-term