Beginner
How to Fine-Tune LLMs in 2026
How to Fine-Tune LLMs in 2026
How to Fine-Tune LLMs in 2026#
Every team building with LLMs hits the same wall eventually.
You write a detailed system prompt, add few-shot examples, tune the temperature, and your agent still gets it wrong 30-40% of the time.
The worst part? It never learns from those mistakes.

Fine-tuning is how you break through it.#
If you're using GPT or Claude, you're using the same model as everyone else, with the same capabilities, the same cost, and no competitive edge.
But take a small open-source model and fine-tune it on your specific task? It can outperform a model 100x its size, at a fraction of the cost and latency.
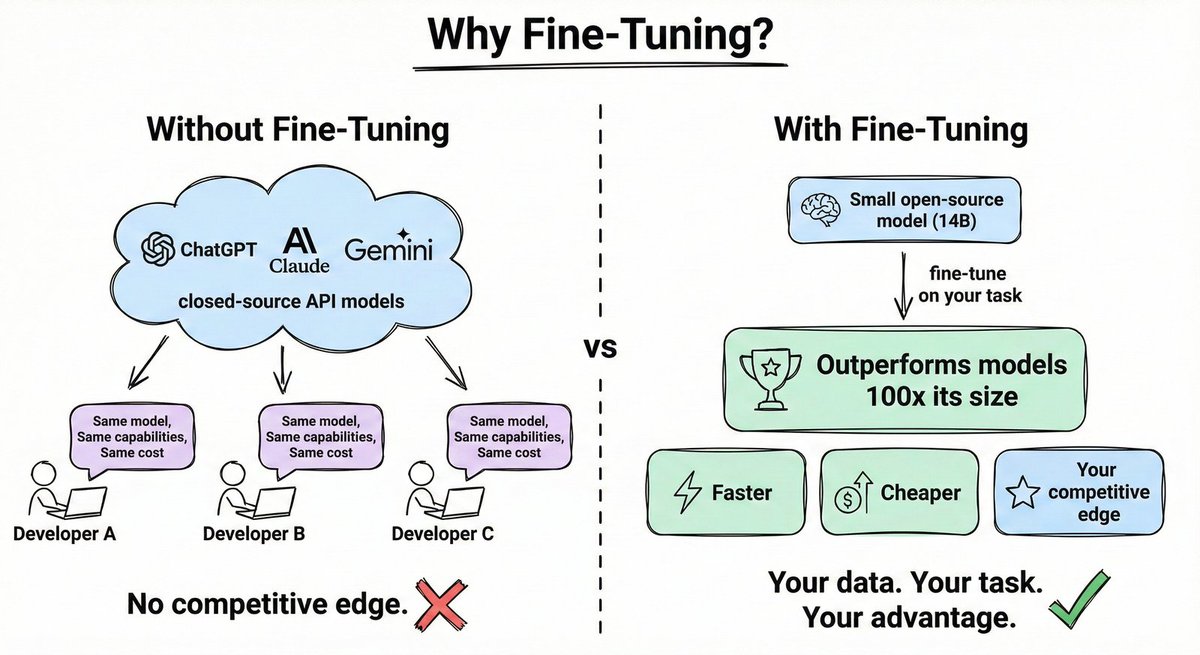
Most developers associate fine-tuning with a painful setup: curated datasets, labeled outputs, hand-crafted reward functions.
In 2026, that's no longer the case.
Modern fine-tuning using GRPO and RULER has changed what's possible. You can now train agents that genuinely improve through experience, without writing a single reward function or collecting a single labeled example.
This article walks through exactly how.
SFT vs. Reinforcement Fine-Tuning#
Most developers know Supervised Fine-Tuning (SFT). You collect input-output pairs and the model learns to imitate them.
The problem? SFT teaches the model what to say, not how to succeed.
For agents that search, call APIs, and reason across multiple steps, imitation isn't enough. You want improvement through trial and error.
Think of it this way:
- SFT = studying a textbook (memorizing answers to known questions)
- RL = on-the-job training (learning from trial, error, and feedback)
This is Reinforcement Fine-Tuning (RFT). You give the model a reward signal and let it discover the best strategies on its own.

How GRPO Works#
So what's the algorithm behind all of this?
GRPO (Group Relative Policy Optimization) is the most popular RFT algorithm today. It's the same algorithm that powered DeepSeek-R1's reasoning capabilities.
The core idea is simple. Instead of training a separate model to score responses, GRPO generates multiple completions and grades them relative to each other.
Here's how it works for each prompt:
- Sample a group: Generate N completions from the current model
- Score each one: A reward function evaluates each attempt
- Normalize within the group: Calculate relative advantage vs. the group average
- Update the model: Reinforce above-average behaviors, suppress below-average ones
GRPO only needs relative rankings, not absolute scores. Whether completions score 0.3, 0.5, and 0.7 or 30, 50, and 70 doesn't matter. Only the ordering drives learning.

ART: Agent Reinforcement Trainer#
GRPO is powerful, but how do you actually apply it to a real-world agent?
ART (Agent Reinforcement Trainer) is a 100% open-source framework by that brings GRPO to any Python application.
Most RL frameworks are built for simple chatbot interactions: one input, one output, and the job is done. Real agents are fundamentally different. They search documents, invoke APIs, and reason across multiple steps before producing an answer.
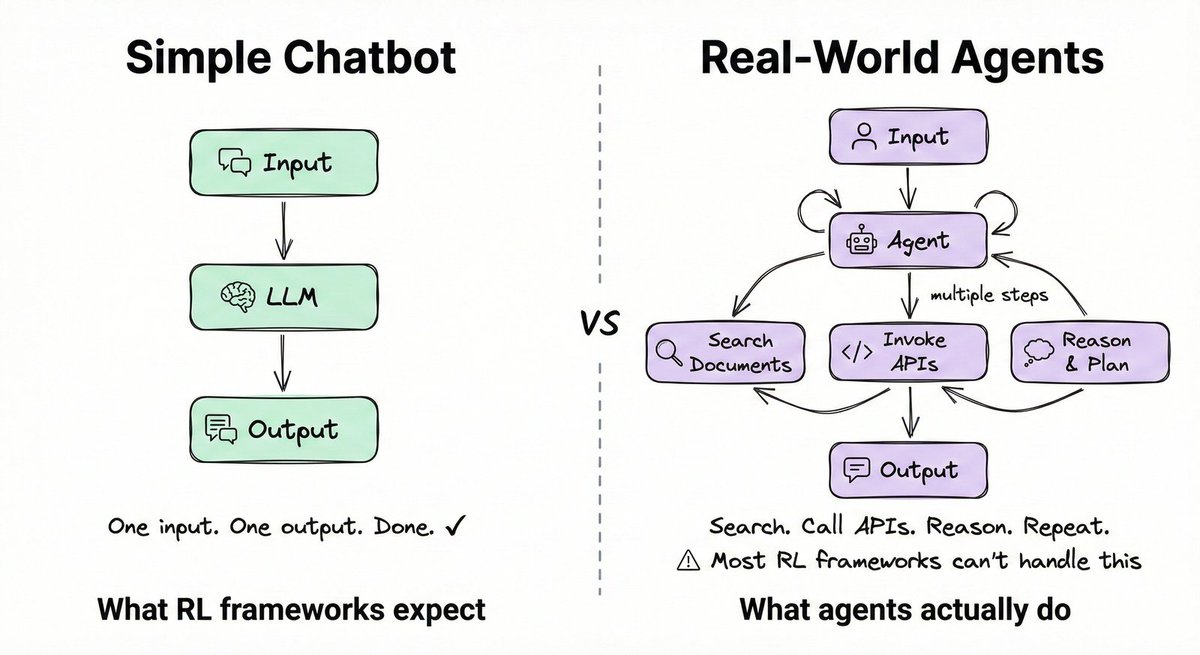
ART is built for exactly this. It provides:
- Native support for tool calls and multi-turn conversations
- Integrations with LangGraph, CrewAI, and ADK
- Efficient GPU utilization during training
Architecture#
ART splits into two parts: a Client and a Backend.
The Client is where your agent code lives. It sends inference requests to the backend and records every action into a Trajectory, the complete history of one agent run.
The Backend is where the heavy lifting happens. It runs vLLM for fast inference and Unsloth-powered GRPO for training. After each training step, a new LoRA checkpoint loads automatically into the inference server.

The full training loop works like this:#
- Client sends an inference request
- Backend generates model outputs
- Agent takes actions in the environment (tool calls, searches, etc.)
- Environment returns a reward
- Trainer updates the model via GRPO
- A new LoRA checkpoint loads into the inference server
- Repeat, with each cycle the model getting a little better than before
RULER: No More Manual Reward Functions#
Here's the part most people dread.
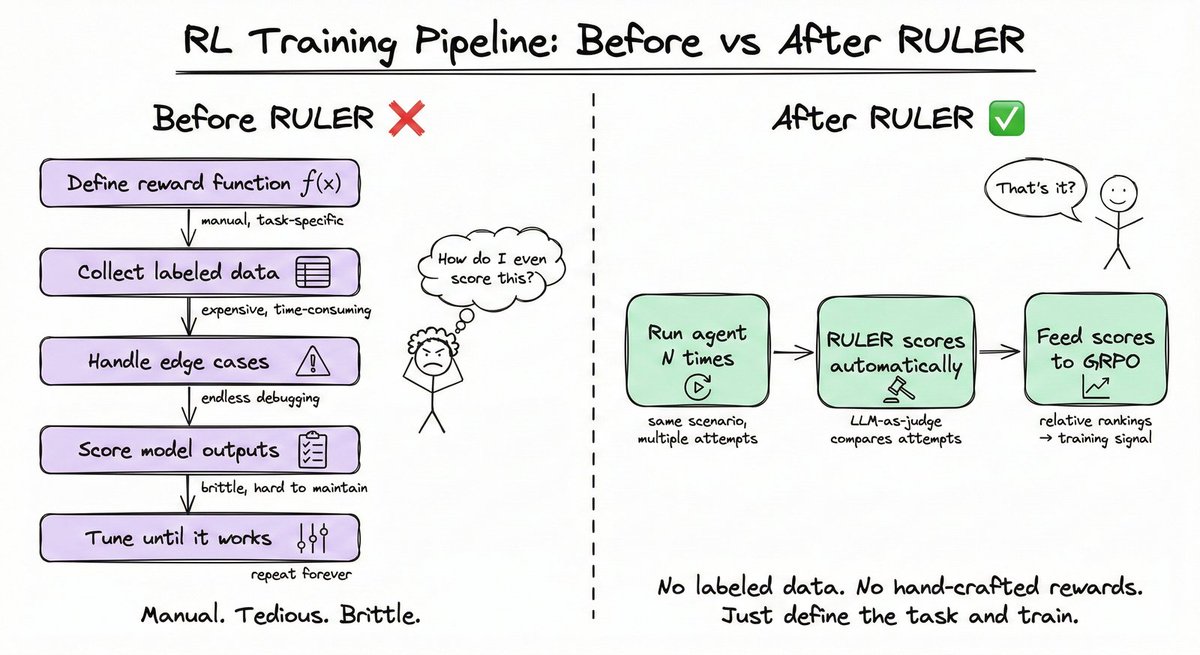
Defining a good reward function has always been the hardest part of RL. Training an email agent requires labeled correct answers. Training a code agent requires test suites. Each one is its own unique engineering project.
RULER (Relative Universal LLM-Elicited Rewards) eliminates this bottleneck entirely. It uses an LLM-as-judge to compare multiple agent trajectories and rank them, with no labeled data required.
It works because of two key insights:
- Asking an LLM "rate this 0-10" produces inconsistent results
- Asking "which of these 4 attempts best achieved the goal?" is far more reliable
And since GRPO only needs relative scores, the absolute values don't matter anyway.
The process is three steps:
- Generate N trajectories for a scenario
- Pass them to an LLM judge, which scores each from 0 to 1
- Use those scores directly as rewards in GRPO
No reward functions to write. No labeled data to collect.
Putting It Together: A practical example#
I put together a fully working notebook that trains a 3B model to master how to use any MCP server through reinforcement learning using ART.
Simply provide an MCP server URL and the notebook will:
- Query the server's tools
- Generate a set of input tasks that use those tools
- Train the model on those tasks using automatic RULER evaluation
You can find more example to adapt and get started in ART GitHub repo.
(don't forget to star 🌟)

Thanks for reading!