初級
ハーネス・エンジニアリングはサイバネティクスである
ハーネス・エンジニアリングはサイバネティクスである
OpenAIのハーネス・エンジニアリングに関する投稿を読みながら、どこかで見たような感覚が拭えませんでした。そして、はっと気づきました。このパターンは以前に見たことがある。一度ではなく、三度も。
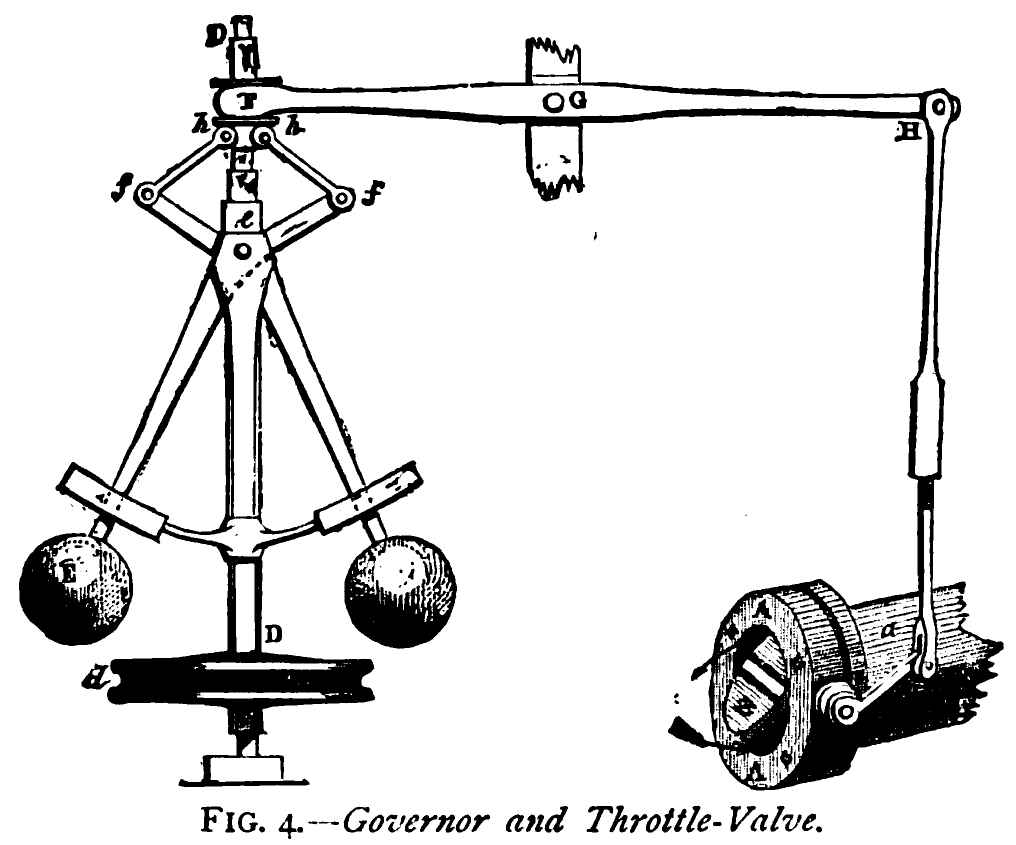
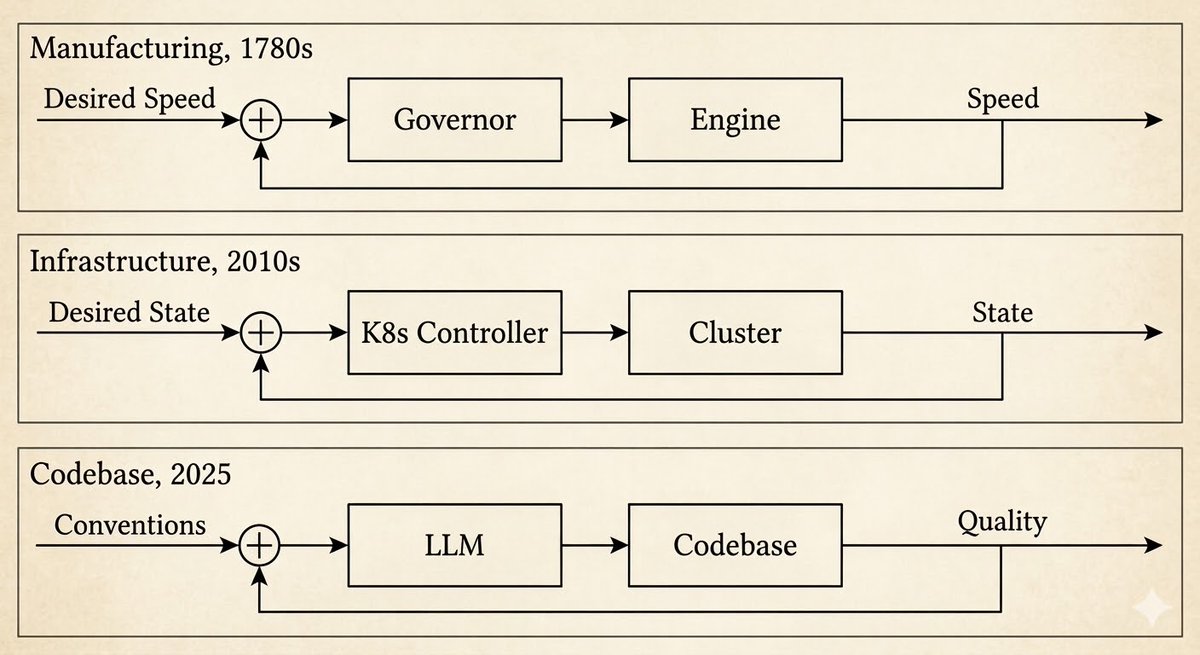
最初は1780年代のジェームズ・ワットの遠心調速機です。それ以前は、作業員が蒸気機関のそばに立ち、手動でバルブを調整していました。その後、重り付きのフライボール機構が回転速度を感知し、自動的にバルブを調整するようになりました。作業員は消えませんでした。仕事が変わったのです:バルブを回すことから、調速機を設計することへ。
二度目はKubernetesです。望ましい状態(レプリカ3つ、このイメージ、これらのリソース制限)を宣言します。コントローラーは実際の状態を継続的に監視します。それらが乖離したとき、コントローラーは調整を行います:クラッシュしたポッドを再起動し、レプリカをスケールし、不良なデプロイメントをロールバックします。エンジニアの仕事は、サービスを再起動することから、システムが調整の基準とする仕様を書くことへと移行しました。
三度目が今です。OpenAIは、もはやコードを書かないエンジニアについて述べています。代わりに、環境を設計し、フィードバックループを構築し、アーキテクチャ上の制約をコード化します。その後、エージェントがコードを書きます。5ヶ月で100万行、手書きはゼロです。彼らはこれを「ハーネス・エンジニアリング」と呼んでいます。
毎回同じパターンです。ノーバート・ウィーナーが1948年に名付けました:サイバネティクス、ギリシャ語のκυβερνήτης(操舵手)から。Kubernetesがその名を得たのと同じ語源です。あなたはバルブを回すのをやめます。あなたは舵を取るのです。
このパターンが現れるたびに、それは誰かがそのレイヤーでループを閉じるのに十分な強力なセンサーとアクチュエーターを構築したからです。
なぜコードベースが最後まで残ったのか#
コードベースにはフィードバックループがありましたが、それは下位レベルのみでした。コンパイラは構文に関するループを閉じます。テストスイートは振る舞いに関するループを閉じます。リンターはスタイルに関するループを閉じます。これらは本物のサイバネティックな制御です。しかし、それらは機械的にチェックできる特性に対してのみ作用します。コンパイルは通るか?テストは通るか?ルールに従っているか?
それより上のすべてのこと — この変更はシステムのアーキテクチャに適合しているか?このアプローチは正しいか?この抽象化はコードベースの成長に伴って問題を引き起こすか? — にはセンサーもアクチュエーターもありませんでした。そのレベルで作用できるのは人間だけでした。品質を判断する側も、修正を書く側も。
LLMはその両方を一度に変えました。LLMは人間がかつて所有していたレベルで感知でき、同じレベルで作用できます:モジュールを再構築し、一貫性のないインターフェースを再設計し、実際に重要な契約を中心にテストスイートを書き直す。重要な意思決定が行われる場所で、フィードバックループが閉じられるのは初めてのことです。
しかし、ループを閉じることは必要条件であって、十分条件ではありません。ワットの調速機は調整が必要でした。Kubernetesコントローラーには適切な仕様が必要です。そして、あなたのコードベースで作業するLLMには、提供するのがさらに難しい何かが必要です。
センサーとアクチュエーターの較正#
基本的なフィードバックループを機能させること — エージェントが実行できるテスト、解析可能な出力を提供するCI、修正を指し示すエラーメッセージ — は最低限の条件です。Carliniがこれを実証しました。彼が16の並列エージェントにCコンパイラを構築させたときのことです:非常にシンプルなプロンプトでしたが、注意深く設計されたテストインフラストラクチャがありました。「私の努力のほとんどは、Claudeの周りの環境 — テスト、環境、フィードバック — の設計に費やされました」
より難しい問題は、あなたのシステムに固有の知識でセンサーとアクチュエーターを較正することです。ここでほとんどの人が行き詰まり、エージェントを責めます。
「間違ったことをし続ける。私たちのコードベースを理解していない」その診断はほぼ間違っています。エージェントが失敗するのは、能力が不足しているからではありません。エージェントが必要とする知識 — あなたのシステムにとって「良い」とは何か、どのパターンがあなたのアーキテクチャに適しているか、避けるべきか — があなたの頭の中に閉じ込められており、あなたがそれを外部化していないからです。エージェントは浸透によって学びません。あなたがそれを書き留めなければ、エージェントは100回目の実行でも1回目と同じ間違いを犯します。
この作業は、あなたの判断を機械可読にすることです。実際のレイヤリングと依存関係の方向を記述するアーキテクチャ文書。修正手順が組み込まれたカスタムリンター。あなたのチームのセンスをコード化した黄金原則。OpenAIはまさにこれを見出しました:彼らは毎週金曜日の20%を「AIの雑な仕事」を片付けることに費やしていました — 彼らが自分たちの基準をハーネス自体にコード化するまで。
唯一の前進の道#
この作業が要求する実践 — ドキュメンテーション、自動化テスト、コード化されたアーキテクチャ上の決定、迅速なフィードバックループ — は、常に正しいものでした。過去30年間に書かれたすべてのエンジニアリング本がそれらを推奨しています。ほとんどの人はそれをスキップします。なぜなら、スキップするコストは遅く、拡散していたからです:徐々に品質が低下し、苦痛なオンボーディング、静かに複利で増える技術的負債。
エージェント型エンジニアリングはそのコストを極端なものにします。ドキュメンテーションをスキップすると、エージェントはあなたの慣習を無視します — 1つのPRだけでなく、すべてのPRで、機械の速度で、24時間体制で。テストをスキップすると、フィードバックループはまったく閉じられません。アーキテクチャ上の制約をスキップすると、ドリフトはあなたが修正できるよりも速く蓄積します。そして、ここに罠があります:エージェントが「きれい」がどのようなものかを知らなければ、エージェントを使ってその混乱を片付けることはできません。較正がなければ、問題を作り出した機械はそれを解決することもできません。
実践は変わっていません。それを無視することに対するペナルティが耐えられないものになったのです。
生成と検証の非対称性 — P対NP問題の背後にある直感であり、CobbeらによってLLMに対して経験的に実証されたもの — は、これがどこに向かうかを示しています。正しい解決策を生成することは、それを検証することよりも難しい。あなたは機械を実装で上回る必要はありません。評価で上回る必要があります:「正しい」がどのように見えるかを指定し、出力がそれを外れたときに認識し、方向性が正しいかどうかを判断する。
ワットの調速機を設計した労働者たちは、バルブを回す仕事に戻りませんでした。彼らができなかったからではありません。もはや意味をなさなかったからです。