초급
심층 분석: AI 에이전트 하네스의 해부학
심층 분석: AI 에이전트 하네스의 해부학
인용된 트윗 https://t.co/VoQByJUrBU https://x.com/i/web/status/2041146899319971922
작성자: @akshay_pachaar
이 글에서는 Anthropic, OpenAI, Perplexity, LangChain이 실제로 무엇을 구축하고 있는지 자세히 살펴봅니다. 오케스트레이션 루프, 도구, 메모리, 컨텍스트 관리, 그리고 "상태 비저장(stateless)" 대규모 언어 모델(LLM)을 유능한 에이전트로 변환하는 기본 메커니즘에 대해 이야기하겠습니다.
아마도 여러분은 이전에 챗봇을 만들어 본 적이 있을 것이고, 몇 가지 도구를 사용하여 ReAct 루프(ReAct: Reason + Act, 모델이 행동하기 전에 추론하는 패턴)를 설정해 본 적도 있을 것입니다. 데모에서는 훌륭해 보이지만, 일단 프로덕션에 들어가면 시스템이 무너지기 시작합니다. 모델이 세 단계 전에 무엇을 했는지 잊어버리고, 도구 호출은 조용히 실패하며, 컨텍스트 창은 의미 없는 쓰레기로 가득 차게 됩니다.
문제는 모델 자체가 아니라 모델을 둘러싼 인프라에 있습니다.
LangChain이 이를 증명했습니다. 동일한 모델과 동일한 매개변수를 사용하여 LLM을 감싸는 기본 아키텍처를 단순히 변경함으로써, 그들은 TerminalBench 2.0(명령줄 작업을 처리하는 AI 에이전트의 능력을 측정하는 벤치마크)에서 시스템 순위를 30위권 밖에서 5위로 끌어올렸습니다. 또 다른 연구에서는 LLM이 이 아키텍처 자체를 최적화하도록 하여 인간이 설계한 시스템조차 능가하는 76.4%의 통과율을 달성했습니다.
이 인프라는 이제 공식적으로 AI 에이전트 하네스(AI Agent Harness) 라고 불립니다.
이 용어는 2026년 초에 공식화되었지만, 핵심 개념은 이미 한동안 존재해 왔습니다. 하네스는 LLM을 감싸는 완전한 소프트웨어 아키텍처입니다. 여기에는 오케스트레이션 루프, 도구, 메모리, 컨텍스트 관리, 상태 지속성, 오류 처리 및 안전장치가 포함됩니다. Anthropic은 Claude Code 문서에서 SDK가 "Claude Code를 구동하는 에이전트 하네스"라고 명확히 밝히고 있습니다. OpenAI의 Codex 팀도 동일한 언어를 사용하여 "에이전트"와 "하네스"를 동등하게 취급하며, LLM을 실질적으로 유용하게 만드는 비모델 아키텍처를 지칭합니다.
LangChain의 Vivek Trivedi가 제시한 정의 공식이 마음에 듭니다. "당신이 모델이 아니라면, 당신은 하네스입니다."
여기서 흔히 혼동되는 점이 있습니다. "AI 에이전트"는 사용자가 인지하는 행동적 발현체입니다. 즉, 목표를 가지고 도구를 사용하며 스스로 수정하는 개체입니다. "하네스" 는 이러한 행동을 만들어내는 기본 메커니즘입니다. 누군가 "에이전트를 만들었다"고 말할 때, 실제로 의미하는 바는 "하네스를 만들고 모델에 연결했다"는 것입니다.
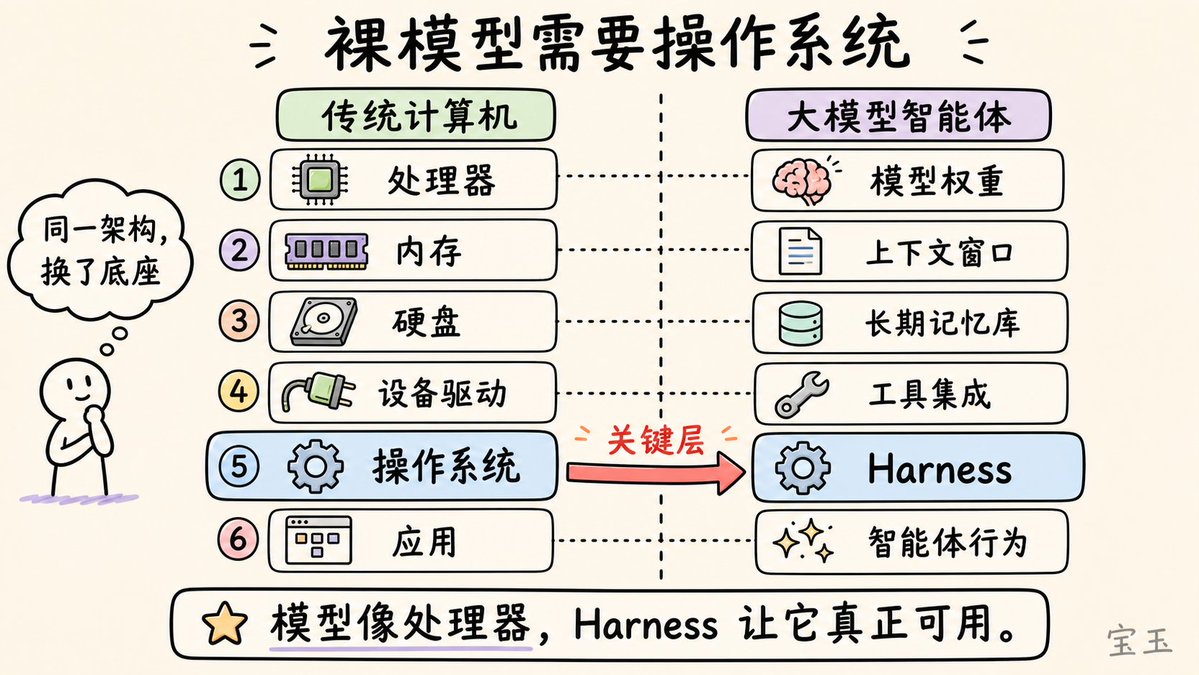
Beren Millidge는 2023년 블로그 게시물에서 정확한 비유를 제시했습니다. 기본 LLM은 메모리, 하드 드라이브, 입출력 장치가 없는 CPU와 같습니다. 여기서 컨텍스트 창은 RAM(빠르지만 제한적) 역할을 하고, 외부 데이터베이스는 하드 드라이브(크지만 느림) 역할을 하며, 도구 통합은 장치 드라이버 역할을 합니다. 하네스는 운영 체제입니다. Millidge가 썼듯이, "우리는 폰 노이만 아키텍처를 재발명했습니다." 이는 모든 컴퓨팅 시스템에 가장 자연스러운 추상화이기 때문입니다.
모델을 중심으로 한 엔지니어링은 세 가지 동심원 계층으로 시각화할 수 있습니다.
- 프롬프트 엔지니어링: 모델이 수신하는 지침을 신중하게 구성합니다.
- 컨텍스트 엔지니어링: 모델이 무엇을, 언제 보는지 관리합니다.
- 하네스 엔지니어링: 위의 두 가지를 모두 포함하며, 전체 애플리케이션 아키텍처(도구 오케스트레이션, 상태 지속성, 오류 복구, 검증 루프, 안전한 실행, 수명 주기 관리)를 포괄합니다.
하네스는 단순히 프롬프트를 감싸는 AI 래퍼가 아니라, 에이전트가 자율적으로 행동할 수 있도록 하는 완전한 시스템입니다.
Anthropic, OpenAI, LangChain 및 광범위한 커뮤니티의 실제 경험을 종합하면, 프로덕션 등급의 에이전트 하네스는 12개의 개별 구성 요소로 구성됩니다. 하나씩 살펴보겠습니다.

1. 오케스트레이션 루프#
이것은 시스템의 "심장"입니다. Thought-Action-Observation(TAO) 루프라고도 알려진 ReAct 루프를 구현합니다. 이 루프는 작업이 완료될 때까지 지속적으로 실행됩니다. 프롬프트 조합 -> LLM 호출 -> 출력 구문 분석 -> 도구 호출 실행 -> 결과 피드백 -> 반복.
기술적으로는 종종 단순한
while 루프입니다. 그러나 복잡성은 루프 자체가 아니라 처리해야 하는 다양한 상태와 로직에 있습니다. Anthropic은 런타임을 "멍청한 루프"라고 설명합니다. 모든 지능은 모델에 있고, 하네스는 단순히 턴을 관리합니다.2. 도구#
도구는 에이전트의 "손"입니다. 이는 구조화된 스키마(이름, 설명, 매개변수 유형)로 정의되어 모델의 컨텍스트에 주입되므로 모델이 사용 가능한 도구를 알 수 있습니다. 도구 계층은 등록, 형식 검증, 매개변수 추출, 샌드박스 환경 내 실행, 결과 캡처, 마지막으로 결과를 모델이 읽을 수 있는 "관찰" 형식으로 포맷하는 작업을 처리합니다.
Claude Code는 파일 작업, 검색, 실행, 웹 액세스, 코드 분석, 하위 에이전트 생성의 6가지 주요 도구 범주를 제공합니다. OpenAI의 Agents SDK는
@function_tool을 통해 정의된 함수 도구, 웹 검색, 코드 인터프리터, 파일 검색과 같은 호스팅 도구, MCP(Model Context Protocol, 도구 통합을 위한 개방형 표준) 서버 도구를 지원합니다.3. 메모리#
메모리는 다양한 시간 규모로 작동합니다. 단기 메모리는 단일 세션 내의 대화 기록입니다. 장기 메모리는 여러 세션에 걸쳐 지속됩니다. Anthropic은 프로젝트 파일과 자동 생성된
memory.md 파일을 사용하고, LangGraph는 네임스페이스별로 구성된 JSON 저장소를 사용하며, OpenAI는 SQLite 또는 Redis로 백업된 세션 저장소를 지원합니다.Claude Code는 3계층 메모리 아키텍처를 구현합니다. 항상 로드되는 경량 인덱스(항목당 약 150자), 필요에 따라 로드되는 상세 주제 파일, 검색을 통해서만 액세스 가능한 원시 대화 로그입니다. 핵심 설계 원칙은 에이전트가 자신의 메모리를 "프롬프트"로 취급하고, 행동하기 전에 실제 상태와 대조하여 확인해야 한다는 것입니다.
4. 컨텍스트 관리#
이것은 많은 에이전트가 조용히 실패하는 지점입니다. 핵심 문제는 컨텍스트 저하입니다. 중요한 정보가 창 중간에 있을 때 모델 성능이 30% 이상 떨어집니다(스탠포드가 발견한 "중간에서 길을 잃음" 현상). 백만 토큰(모델이 처리하는 가장 작은 텍스트 단위, 대략 단어 또는 문자 일부에 해당) 창이 있더라도 컨텍스트가 커질수록 명령 수행 능력이 저하됩니다.
프로덕션 전략은 다음과 같습니다.
- 압축: 한계에 도달하면 대화 기록을 요약합니다(Claude Code는 중복된 도구 출력을 버리면서 아키텍처 결정 및 수정되지 않은 버그는 유지).
- 관찰 마스킹: 오래된 도구 출력은 숨기지만 도구 호출 기록은 유지합니다.
- 적시 검색: 가벼운 식별자만 유지하고 데이터를 동적으로 로드합니다(Claude Code는 전체 파일을 로드하는 것보다
grep또는head명령을 선호). - 하위 에이전트 위임: 각 하위 에이전트가 심층 탐색을 수행하지만 1000~2000 토큰의 압축된 요약만 반환하도록 합니다.
Anthropic의 컨텍스트 엔지니어링 가이드는 목표를 다음과 같이 명시합니다. 목표 달성 확률을 최대화하는 가장 강력한 신호를 가진 가장 작은 토큰 집합을 찾는 것입니다.
5. 프롬프트 구성 (Prompt Construction)#
이는 모델이 각 단계에서 보게 되는 내용을 정확히 결정합니다. 계층 구조로 되어 있습니다: 시스템 프롬프트, 도구 정의, 메모리 파일, 대화 기록, 그리고 현재 사용자 메시지입니다.
OpenAI의 Codex는 엄격한 우선순위 스택을 사용합니다: 서버 제어 시스템 메시지(최우선 순위), 도구 정의, 개발자 지침, 사용자 지침, 그리고 마지막으로 대화 기록입니다.
6. 출력 파싱 (Output Parsing)#
최신 Harness는 네이티브 도구 호출을 활용합니다. 여기서 모델은 수동 파싱이 필요한 자유 텍스트 대신 구조화된
tool_calls 객체를 반환합니다. Harness는 다음을 확인합니다: 도구 호출이 있는가? 있다면, 실행하고 루프를 계속합니다. 없다면, 현재 출력이 최종 답변입니다.구조화된 출력을 위해 OpenAI와 LangChain 모두 Pydantic 모델(데이터 검증 및 형식 지정을 위한 Python 라이브러리)을 통해 스키마 제약 조건을 지원합니다.
7. 상태 관리 (State Management)#
LangGraph는 상태를 그래프 노드를 통해 흐르는 타입이 지정된 딕셔너리로 모델링합니다. 시스템은 주요 단계에서 "체크포인팅(Checkpointing)"을 수행하여 중단 시 복구와 "타임 트래블(time travel)" 디버깅까지 가능하게 합니다. OpenAI는 네 가지 전략을 제공합니다: 인메모리, SDK 세션, 서버 측 API, 또는 경량 응답 ID 체인입니다. Claude Code는 다른 접근 방식을 취합니다: Git 커밋을 체크포인트로, 진행 파일을 구조화된 스크래치패드로 사용합니다.
8. 오류 처리 (Error Handling)#
왜 이것이 중요할까요? 단계별 성공률이 99%인 10단계 프로세스라도 최종 성공률은 약 90.4%에 불과합니다. 오류는 눈덩이처럼 불어납니다.
LangGraph는 오류를 네 가지 유형으로 분류합니다: 일시적 오류(지연 후 재시도), 모델 복구 가능 오류(모델이 조정할 수 있도록 오류를 도구 메시지로 반환), 사용자 수정 가능 오류(인간의 개입을 위해 일시 중지), 예상치 못한 오류(디버깅을 위해 에스컬레이션).
9. 가드레일 및 안전 (Guardrails and Safety)#
OpenAI의 SDK는 세 가지 수준을 구현합니다: 입력 가드레일(첫 번째 에이전트 실행 시 확인), 출력 가드레일(최종 결과 확인), 도구 가드레일(모든 도구 호출 전 확인). "트립와이어(Tripwire)" 메커니즘이 트리거되면 에이전트는 즉시 중지됩니다.
Anthropic은 아키텍처적으로 "권한 실행"과 "모델 추론"을 분리합니다. 모델은 하고 싶은 것을 결정하지만, Harness는 허용되는 것을 결정합니다.
10. 검증 루프 (Verification Loops)#
이것이 "장난감 데모"와 "프로덕션 등급 에이전트"를 구분짓는 핵심 요소입니다. Anthropic은 세 가지 방법을 권장합니다: 규칙 기반 피드백(테스트, 린팅), 시각적 피드백(Playwright를 통한 UI 스크린샷 촬영), LLM-as-judge(다른 하위 에이전트가 출력을 평가하도록 함).
Claude Code의 창시자 Boris Cherny는 모델이 자신의 작업을 검증할 수 있도록 하면 출력 품질이 2~3배 향상된다고 언급합니다.
11. 하위 에이전트 오케스트레이션 (Subagent Orchestration)#
Claude Code는 세 가지 모드를 지원합니다: Fork(부모 컨텍스트 복제), Teammate(파일 기반 사서함을 통해 통신하는 독립 창), Worktree(독립 Git 브랜치). OpenAI는 에이전트를 도구(특정 하위 작업을 처리하는 전문가) 또는 핸드오프(전문가가 이후 제어권을 인계)로 지원합니다.
이제 구성 요소를 이해했으니, 이것들이 단일 루프에서 어떻게 함께 작동하는지 살펴보겠습니다.

- 1단계 (프롬프트 조립): Harness가 완전한 입력을 구성합니다.
- 2단계 (모델 추론): 조립된 내용이 모델 API로 전송됩니다. 모델이 토큰을 생성합니다: 텍스트 또는 도구 호출 요청입니다.
- 3단계 (출력 분류): 도구 호출이 없으면 루프가 종료됩니다. 있으면 실행 단계로 진행합니다.
- 4단계 (도구 실행): Harness가 매개변수를 검증하고, 권한을 확인하며, 샌드박스에서 도구를 실행하고, 결과를 캡처합니다.
- 5단계 (결과 패키징): 결과를 모델이 읽을 수 있는 메시지로 형식화하고, 오류를 캡처하여 모델이 스스로 복구할 수 있도록 합니다.
- 6단계 (컨텍스트 업데이트): 결과를 기록에 추가하고, 필요한 경우 압축을 트리거합니다.
- 7단계 (루프): 종료 조건이 충족될 때까지 1단계로 돌아갑니다.

- Anthropic (Claude Agent SDK): 간단한
query()함수를 통해 Harness를 노출합니다. 런타임은 "멍청한 루프"이며, 모든 지능은 모델에 있습니다. - OpenAI (Agents SDK): "코드 우선" 전략을 채택합니다. 워크플로 로직은 복잡한 그래프 언어가 아닌 Python으로 직접 표현됩니다.
- LangGraph: Harness를 명시적 상태 그래프로 모델링하여 프로세스에 대한 세밀한 제어를 강조합니다.
- CrewAI: 역할 기반 다중 에이전트 협업을 구현하며, 결정론적 백본 로직을 처리하는 "프로세스 레이어"에 의해 관리됩니다.
- AutoGen: Microsoft에서 개발했으며, 순차 실행, 그룹 채팅, 핸드오프, 동적 작업 관리와 같은 여러 오케스트레이션 패턴을 지원합니다.
"스캐폴딩(scaffolding)" 은유는 장식적이지 않으며 매우 정확합니다. 건설용 비계는 작업자가 다른 방법으로는 도달할 수 없는 높이에 도달할 수 있게 해주는 임시 인프라입니다. 비계 자체가 집을 짓는 것은 아니지만, 비계 없이는 작업자가 위층으로 갈 수 없습니다.

핵심 통찰은 이것입니다: 집이 지어지면 비계는 제거됩니다. 모델 성능이 향상됨에 따라 Harness의 복잡성은 감소해야 합니다.
이것이 공진화 원칙입니다: 현재 모델은 이미 Harness의 존재를 염두에 두고 훈련되었습니다. Harness가 잘 설계되었다면 모델이 업그레이드될 때 복잡성을 추가할 필요가 없으며, 성능은 자동으로 향상됩니다.
모든 Harness 설계자는 다음 일곱 가지 선택에 직면합니다:
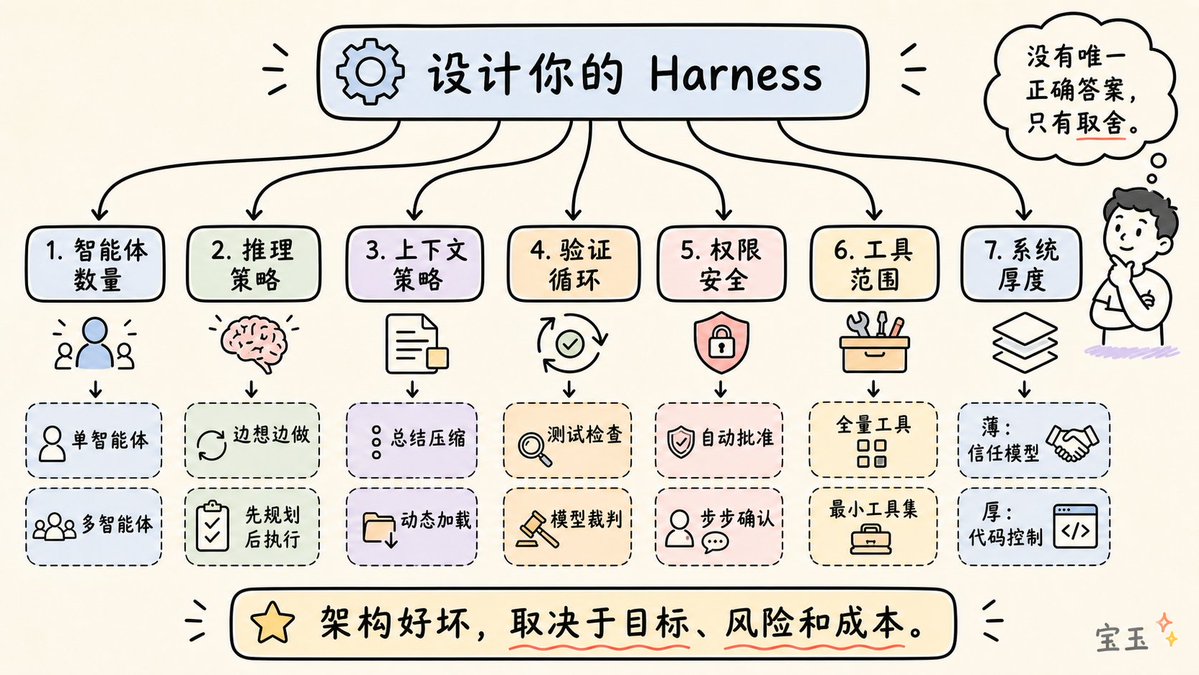
- 단일 에이전트 vs. 다중 에이전트: 공식 조언: 먼저 단일 에이전트의 잠재력을 완전히 탐색하십시오. 다중 에이전트 시스템은 오버헤드와 정보 손실을 초래합니다.
- ReAct vs. Plan-then-Execute: ReAct는 유연하지만 비용이 많이 듭니다. "Plan-then-Execute"는 더 빠릅니다.
- 컨텍스트 관리 전략: 대화를 요약할 것인가, 아니면 데이터를 동적으로 로드할 것인가?
- 검증 루프 설계: 하드 코드 테스트를 사용할 것인가, 아니면 다른 LLM이 점수를 매기도록 할 것인가?
- 권한 및 보안 아키텍처: 자동 승인으로 속도를 우선시할 것인가, 아니면 단계별 확인으로 안전을 우선시할 것인가?
- 도구 범위 관리: 더 많은 도구가 항상 더 좋은 것은 아닙니다. 현재 단계에 필요한 최소한의 도구 집합을 노출하는 것이 종종 최상의 결과를 가져옵니다.
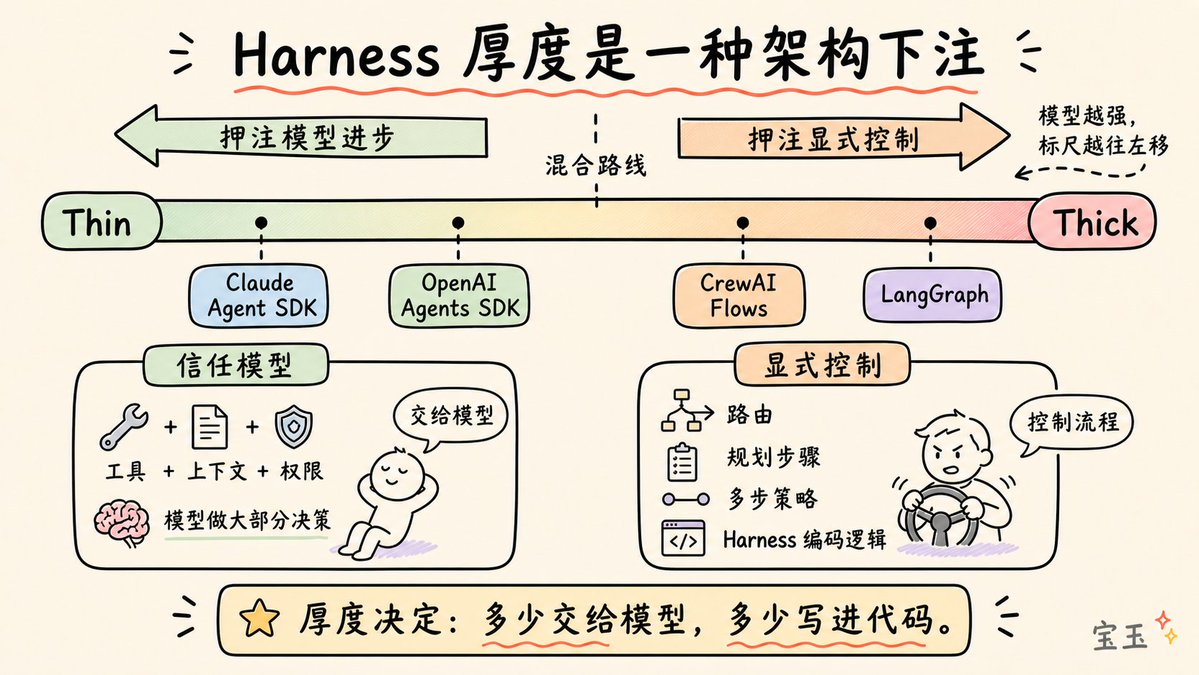
- Harness 두께: 시스템에 얼마나 많은 로직이 하드코딩되어 있고, 얼마나 많은 부분을 모델이 스스로 해결하도록 남겨둘 것인가?
정확히 동일한 모델을 사용하는 두 에이전트라도 Harness 설계만으로 인해 성능이 크게 달라질 수 있습니다. TerminalBench 증거는 명확합니다: 단순히 Harness를 변경하는 것만으로 순위가 20자리 이상 바뀔 수 있습니다.
Harness는 해결된 문제도, 범용 상품 계층도 아닙니다. 그것은 하드코어 엔지니어링의 구현체입니다: 컨텍스트를 희소 자원으로 어떻게 관리할 것인가? 오류 누적을 방지하기 위해 검증 루프를 어떻게 설계할 것인가? 환각을 일으키지 않는 메모리 시스템을 어떻게 구축할 것인가?
모델이 더욱 강력해짐에 따라 Harness는 더 얇아지겠지만, 결코 사라지지는 않을 것입니다. 가장 강력한 모델조차도 윈도우를 관리하고, 코드를 실행하고, 상태를 저장하고, 작업을 검증할 시스템이 필요합니다.
다음에 에이전트가 제대로 작동하지 않을 때, 모델만 탓하지 마십시오. Harness를 확인하십시오.