초급
+29k 스타, 벡터 없음: PageIndex가 LLM 추론으로 임베딩을 대체하는 방법
+29k 스타, 벡터 없음: PageIndex가 LLM 추론으로 임베딩을 대체하는 방법
VectifyAI의 트리 기반 RAG, FinanceBench에서 98.7% 달성. 문서에 언급된 MCTS는 오픈소스 코드에 없음.#
PageIndex는 벡터리스 RAG 프레임워크로, 문서에서 계층적 트리를 구축하고 LLM이 쿼리에 답변할 페이지를 추론하도록 합니다.
VectifyAI가 2025년 4월 1일에 오픈소스로 공개했습니다. 저장소는 GitHub에서 +29k 스타를 돌파했으며, GitHub 트렌딩에서 일일 1위를 기록했습니다.
PageIndex 위에 구축된 금융 QA 시스템인 Mafin 2.5는 FinanceBench의 전체 10,231개 질문 세트에서 98.7%를 기록했으며, 평가 코드는 별도 저장소에 공개되어 있습니다. 증거는 아래에 있습니다.
저장소 스냅샷#

이것이 중요한 이유#
벡터 RAG는 쿼리와 유사해 보이는 텍스트를 검색하지만, 쿼리에 답변하는 텍스트는 검색하지 않습니다. 임베딩된 청크와 임베딩된 질문 간의 코사인 유사도 매칭은 구문적 이웃일 뿐, 의미적 답변이 아닙니다.
이 격차는 개발자들이 RAG가 가장 필요로 하는 곳에서 나타납니다: 600페이지 분량의 10-K 보고서, 수천 페이지 분량의 규정 준수 바인더, 밀도 높은 기술 사양서. PageIndex는 프레임을 뒤집습니다. 문서는 구조적 트리를 얻고, LLM은 읽을 노드를 선택하며, 답변은 최근접 이웃 검색이 아닌 구조에 대한 추론에서 나옵니다.
배경#
Mingtian Zhang과 Yu Tang이 설립한 VectifyAI는 2025년 4월 1일에 PageIndex를 출시했습니다. 13개월 후, 저장소는 +29k 스타, 2,476개의 포크, 138개의 열린 이슈, 11명의 기여자, 그리고 GitHub 트렌딩에서 일일 1위를 기록했습니다. 기여자 중 두 명인 rejojer와 zmtomorrow는 총 281개 커밋의 89.3%를 차지합니다.
라이선스는 MIT입니다. 패키지는
pageindex/ 디렉토리에 있는 6개 파일에 걸쳐 2,579줄의 Python 코드로 구성되어 있습니다.PageIndex 작동 방식#
파이프라인은 두 단계로 실행됩니다.

1단계: 트리 인덱스 구축.
PyPDF2(기본값) 또는 PyMuPDF가 PDF를 페이지별 텍스트로 파싱합니다. LLM이 처음 20페이지를 스캔하여 목차를 감지합니다. 세 가지 처리 모드가 분기됩니다: 페이지 번호가 있는 TOC, 페이지 번호가 없는 TOC, 또는 TOC가 전혀 없는 경우.
시스템은
verify_toc()를 실행하여 LLM 기반 퍼지 제목 매칭으로 모든 TOC 항목을 할당된 실제 페이지와 비교합니다. fix_incorrect_toc_with_retries()는 일치하지 않는 항목을 최대 3회 재시도합니다. 정확도가 60% 미만으로 유지되면 시스템은 다음 처리 모드로 폴백합니다. 10페이지 이상 AND 20,000토큰을 초과하는 노드는 동일한 LLM 기반 추출을 사용하여 재귀적으로 분할됩니다.2단계: 추론 기반 검색.
검색 모듈은 에이전트 런타임을 위해 세 가지 도구 함수를 노출합니다: 메타데이터용
get_document(), 텍스트 콘텐츠를 제외한 트리용 get_document_structure(), 특정 페이지용 get_page_content().LLM은 트리를 받고, JSON 응답에서 노드 ID를 선택하며, 시스템은 해당 노드의 텍스트를 가져오고, LLM은 최종 답변을 작성합니다. 노드는 다음과 같습니다:
{
"title": "Financial Stability",
"node_id": "0006",
"start_index": 21,
"end_index": 22,
"summary": "The Federal Reserve...",
"nodes": [
{
"title": "Monitoring Financial Vulnerabilities",
"node_id": "0007",
"start_index": 22,
"end_index": 28,
"summary": "..."
}
]
}문서에서 언급되지만 오픈소스 코드에는 구현되지 않은 한 가지: MCTS.
트리 검색 튜토리얼에 따르면 클라우드 대시보드와 검색 API는 "LLM 트리 검색과 가치 함수 기반 몬테카를로 트리 검색(MCTS)의 조합"을 사용합니다. 오픈소스 코드는 LLM 프롬프트 트리 검색 변형만 제공합니다. MCTS는 호스팅 서비스에 있습니다.
시작하는 방법#
클론부터 작동하는 에이전틱 검색 데모까지 5단계.
- 클론 및 설치.
git clone https://github.com/VectifyAI/PageIndex.git
cd PageIndex
pip3 install --upgrade -r requirements.txt-
API 키 설정. 프로젝트 루트에
OPENAI_API_KEY=your_key가 포함된.env파일을 생성합니다.CHATGPT_API_KEY는 하위 호환 가능한 별칭으로 지원됩니다. -
PDF에서 트리 생성.
python3 run_pageindex.py --pdf_path /path/to/document.pdf출력 JSON은
./results/{filename}_structure.json에 저장됩니다. 기본 모델은 gpt-4o-2024-11-20이며, --model로 재정의 가능합니다.- 에이전틱 RAG 데모 실행. 이것은 트리 전용 검색 형식이 왜 유용한지 이해하기 위한 핵심 예제입니다.
pip3 install openai-agents
python3 examples/agentic_vectorless_rag_demo.py데모는 arXiv PDF를 다운로드하고, 작업 공간 지속성을 가진 PageIndexClient를 통해 인덱싱하며, 세 가지 검색 도구에 연결된 OpenAI Agent를 생성한 다음, 질문에 답변할 때 에이전트의 추론과 도구 호출을 스트리밍합니다.
- 선택 사항: 프로그래매틱 API.
from pageindex import PageIndexClient
client = PageIndexClient(workspace="./workspace")
doc_id = client.index("document.pdf")
structure = client.get_document_structure(doc_id)
content = client.get_page_content(doc_id, "5-7")증거: FinanceBench에서 98.7%#
VectifyAI의 PageIndex 기반 금융 QA 시스템인 Mafin 2.5는 전체 10,231개 질문 FinanceBench 벤치마크(arXiv:2311.11944)에서 98.7%의 정확도를 보고합니다. 평가 코드(
eval.py)와 원시 결과 JSON은 VectifyAI/Mafin2.5-FinanceBench 저장소에 공개되어 있습니다. 98.7% 수치는 두 가지 기본 LLM(GPT-4o 및 DeepSeek v3)에서 유지됩니다.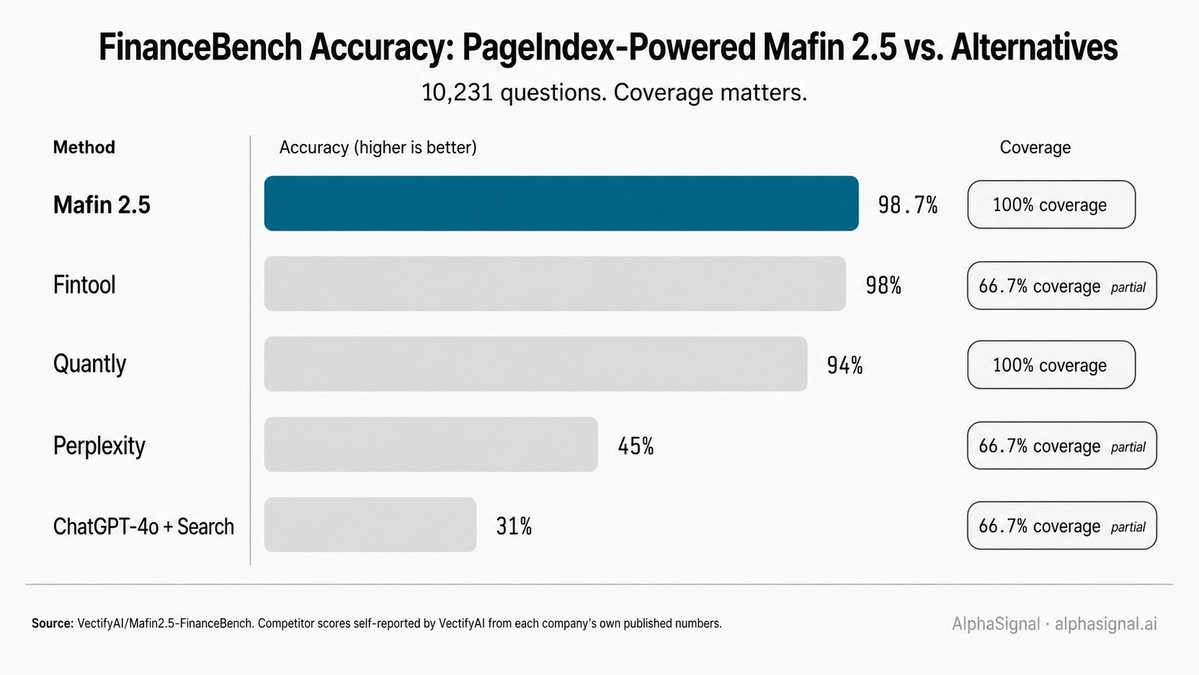
참고 사항. VectifyAI가 비교 테이블을 자체 보고합니다. 경쟁사 점수는 해당 회사가 발표한 자체 수치에서 가져온 것이며, 독립적으로 재실행되지 않았습니다. 커버리지 열이 중요합니다: 비교 대상 중 세 곳은 벤치마크의 66.7%만 실행한 반면, Mafin 2.5는 100%를 커버했습니다.
PageIndex vs. 벡터 RAG vs. 긴 컨텍스트 LLM#
PageIndex는 모델이 아닌 프레임워크이므로 리더보드에 직접 들어가지 않습니다. 중요한 아키텍처 비교는 다음과 같습니다:

또한, OpenAI Agents SDK를 사용한 자체 호스팅 PageIndex의 벡터리스 RAG 예제도 있습니다.
PageIndex의 승리 조건은 길고 구조화된 코너입니다. 문서에 TOC 또는 계층적 제목이 있고, 답변이 특정 섹션에 있으며, 벡터 저장소는 쿼리와 유사해 보이지만 답변이 포함된 섹션을 건너뛰는 이웃을 표면화할 것입니다.
현재 한계점#
MCTS 검색은 클라우드 전용입니다.
README와 튜토리얼에서는 가치 함수 기반 MCTS 검색 계층을 언급하지만, 오픈소스 코드에는 LLM 프롬프트 트리 검색 변형만 포함되어 있습니다. 클라우드 서비스와 동일한 검색 깊이를 기대하고 저장소를 가져오는 실무자들은 더 얇은 버전을 사용하게 됩니다.
OSS PDF 파싱에는 OCR이 없습니다.
표준 PyPDF2와 PyMuPDF만 제공됩니다. 스캔된 PDF, 이미지 전용 문서, 노이즈가 많은 금융 서류는 전처리나 클라우드 OCR 서비스가 필요합니다.
자체 호스팅 안정성 한계.
TOC 검증 루프는 최대 3회 수정 시도로 제한됩니다(
pageindex/page_index.py의 fix_incorrect_toc_with_retries). 세 가지 처리 모드를 모두 거친 후에도 정확도가 60% 이하로 유지되면 시스템은 Processing failed 예외를 발생시킵니다. README의 유일한 안정성 관련 언급은 "복잡한 PDF 사용 사례의 경우 클라우드 서비스에서 향상된 OCR, 트리 구축 및 검색을 제공합니다"라는 문구입니다. 비정형 레이아웃의 실제 PDF는 실패 경로에 도달할 수 있습니다.SECURITY.md 없음, 6개의 공개 보안 이슈.
저장소에는 문서화된 보안 정책이 없습니다. 6개의 공개 이슈가 보안 정책을 요청하거나(#85, #240) 취약점을 보고합니다(#79, #80, #81, #174). LiteLLM 공급망 사고는 패치되었습니다:
requirements.txt는 손상된 임계값 이상인 litellm==1.83.7로 고정되어 있습니다.AlphaSignal 평가#
평결: 주목할 가치 있음.
PageIndex는 README 헤드라인이 약속한 트리 구축 기능을 제공합니다. 검색 스토리는 불완전합니다. 오픈소스 코드는 개발자에게 프롬프트와 세 가지 도구 함수를 제공하지만, 문서에서 시스템의 일부로 명명된 MCTS 계층은 공개 코드에 없습니다.
유지보수 상태는 혼합적입니다. 11명의 기여자 중 89.3%의 커밋이 두 사람에게서 나왔고, 138개의 열린 이슈(안정성 수정 요청 #188 포함, 댓글 36개)가 있으며 SECURITY.md가 없습니다.
네 가지 사항이 충족되면 평결이 프로덕션 준비 완료로 변경됩니다: MCTS가 오픈소스 경로에 포함, SECURITY.md 및 외부 감사, 팀 자체의 공개된 지연 시간 벤치마크, 오픈소스 파서의 OCR.
그때까지는 프레임워크의 구조적 문서 정확도가 실제 워크로드에서 테스트하기에는 충분하지만, 프로덕션 시스템을 걸기에는 아직 충분하지 않습니다. PageIndex 2.0 또는 MCTS-OSS 릴리스를 트리거로 주목하세요.
혜택을 받는 사람과 그렇지 않은 사람#
혜택을 받는 경우: 긴 구조화된 문서(10-K 보고서, 규정 준수 바인더, 계약서, 기술 매뉴얼)에 대한 QA를 구축하는 ML 및 백엔드 엔지니어, 긴 문서에 대한 벡터 RAG의 재현율 한계에 부딪힌 팀, 이미 프론티어 모델 API 호출 비용을 지불하고 있으며 쿼리 지연 시간을 검색 정확도와 맞바꿀 수 있는 팀.
적합하지 않은 경우: 짧은 문서에 대한 지연 시간에 민감한 실시간 채팅, 검색 규모에서 LLM API 예산이 없는 팀, OCR이 필요한 스캔 문서 워크플로우, 문서화되지 않은 보안 태세가 장애물인 프로덕션 배포.
실무자 시사점#
PageIndex의 트리 추론 접근 방식이 FinanceBench의 전체 10,231개 질문 세트에서 98.7%를 달성함에 따라, 이제 단일 벡터를 임베딩하지 않고도 600페이지 분량의 10-K 보고서에 대한 질문에 답할 수 있습니다.
링크#
- PageIndex 저장소 (+29k 스타, MIT, ~5분 설정)
- Agentic RAG 데모 (OpenAI Agents SDK 통합)
- Mafin2.5-FinanceBench 평가 저장소 (공개 평가 코드 및 원시 결과)
- pageindex-mcp (MCP 서버)
- PageIndex 프레임워크 소개 (공식 심층 분석)
더 많은 콘텐츠를 보려면 @AlphaSignalAI를 팔로우하세요.
매일 AI 시그널을 받으려면 AlphaSignal.ai에서 구독하세요. 280,000명 이상의 개발자가 읽고 있습니다.
질문과 답변#
Q: PageIndex란 무엇인가요?
VectifyAI의 벡터리스 트리 기반 RAG 프레임워크입니다. 문서에서 계층적 트리를 구축하고 LLM이 어떤 노드에 답변이 포함되어 있는지 추론하도록 하며, 임베딩이나 벡터 저장소를 사용하지 않습니다.
Q: PageIndex는 벡터 RAG와 어떻게 다른가요?
벡터 RAG는 임베딩 유사성으로 청크를 검색하여 구문적 이웃을 최적화합니다. PageIndex는 임베딩을 완전히 건너뛰고 구조적 트리에 대한 LLM 추론에 의존하여 쿼리에 답할 가능성이 가장 높은 섹션을 선택합니다.
Q: PageIndex가 달성한 벤치마크는 무엇인가요?
PageIndex 기반의 Mafin 2.5는 VectifyAI의 공개 평가 저장소에 따르면 FinanceBench의 전체 10,231개 질문 세트에서 98.7%를 보고했습니다. 이 수치는 GPT-4o와 DeepSeek v3 기본 LLM 모두에서 유지됩니다.
Q: PageIndex를 자체 호스팅할 수 있나요?
네. 저장소는 MIT 라이선스입니다.
git clone 후 pip3 install -r requirements.txt, 그리고 .env 파일에 OpenAI API 키를 추가하는 것이 전체 과정입니다. 스캔된 PDF의 OCR은 클라우드 전용입니다.Q: PageIndex는 프로덕션 준비가 되었나요?
주목할 가치는 있지만 아직 프로덕션 수준은 아닙니다. README는 초기 베타임을 명시합니다. SECURITY.md가 없고, 문서에서 참조하는 MCTS 검색 계층이 오픈소스 코드에 포함되어 있지 않습니다.