初级
为LLM应用设计评估数据集
为LLM应用设计评估数据集
本文是我们作为 Langfuse Academy 系列的一部分发布的其中一篇,该系列将带你了解完整的AI工程生命周期。如果你是第一次接触这个系列,建议从 AI工程循环 开始阅读。
AI工程循环简要回顾#
AI工程循环是团队持续改进AI系统的方式。它将生产环境中发生的情况(追踪、监控)与开发过程中的结构化迭代(数据集、实验、评估)连接起来。每次交付的改进都会产生新数据,团队会持续循环这个过程。
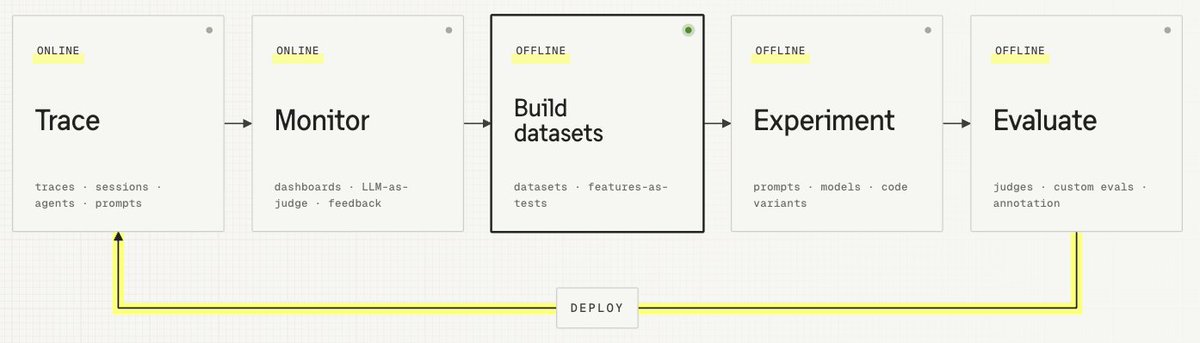
更多详情请参阅 此处。
数据集如何融入循环#
现在的问题是:当你发现值得改进的地方时,如何在部署到生产环境之前测试变更?循环接下来的三个步骤正好解决了这个问题,而这一切从数据集开始。
数据集是一组测试用例的集合,每次进行变更时,你都会用这些用例来运行你的应用程序(即"实验")。与其直接部署并寄希望于一切顺利,不如通过一组代表实际使用情况的输入,获得可重复、一致的检查。
数据集项#
数据集由多个项组成,每个项代表一个测试用例:你的应用程序应该能够处理的一种情况。通常,一个项包含三个字段:
- 输入(必需)
- 预期输出(可选)
- 元数据(可选)
数据集项的三个字段#

一个好的思维模型:

常见的预期输出模式#
是否需要预期输出,以及它应该是什么样子,取决于你使用的评估器类型。
基于参考与无参考评估器
有些评估器会根据预定义的预期输出(基于参考)来检查输出。其他评估器则无需真实值进行比较即可评估输出(无参考)。
精确匹配
预期输出是字面上的正确答案。例如:
- 分类任务中,正确标签是
billing_inquiry - 提取任务中,预期实体是
["Paris", "Thursday"]
参考答案
预期输出是一个黄金标准响应,展示了良好输出的样子。评估器可以将测试输出与此示例进行比较,例如通过检查语义相似性或关键点是否匹配。
评估标准
预期输出是一系列输出应满足的检查项或要求。例如:
- "必须提及退款政策"
- "必须包含帮助中心链接"
评估器会检查输出是否满足这些标准。
无预期输出
有时根本不需要预期输出。如果你只是检查:
- 语气是否专业
- 响应是否安全
- 输出是否符合要求的格式
那么你的数据集项只需要输入即可,因为你会使用无参考评估器。
上述组合
由于你可以在单个数据集项上运行多种评估器的组合,因此数据集项的预期输出字段也可以包含多种类型的参考数据。预期输出是一个 JSON 字段,因此你可以毫无问题地存储多种类型的参考数据。
什么是好的数据集#
一个好的数据集能够反映你的系统在生产环境中会遇到的情况。如果通过数据集测试能让你在部署前充满信心,那么它就完成了任务。
范围清晰。每个数据集应有明确定义的范围。如果你将内部步骤视为实现细节,那么范围可以是端到端的;也可以针对单个步骤,如检索或摘要,如果这是你试图改进的部分。你最终可能会拥有多个数据集,每个都有明确的用途。

适合工作流的规模。有些数据集足够小且运行速度快,可以作为 CI/CD 流水线的一部分在每次推送时运行。其他数据集更大、更全面,适合定期运行,但对于每次小变更来说太慢。

从何处开始#
从你拥有的最具体示例开始,一旦你了解要测试什么,再扩展覆盖范围。
- 从生产追踪中提取你发现并希望改进的示例,可以原样使用,也可以匿名化或由AI转换。
- 根据预定义需求、边缘情况或你的智能体必须可靠处理的行为,添加手写案例。
- 一旦你了解想要更广泛覆盖哪些维度,使用AI生成合成示例。
下一步#
一旦你有了数据集,下一步就是运行你的系统来测试它,看看变更如何影响输出质量。这正是 实验 的用途。