Beginner
2026年你必须搞懂的20个AI核心概念
用大白话解释神经网络、Token、Embeddings、Transformer、RAG、AI Agents、RLHF、LoRA、量化和扩散模型等 20 个 AI 核心概念。
20 mins
每个人都在用 AI。
但几乎没人真正理解它是怎么运行的。
人们总是把 Transformer、嵌入 (Embeddings)、检索增强生成 (RAG)、智能体 (Agents)、人类反馈强化学习 (RLHF) 这些词挂在嘴边……
……就好像大家早就心领神会了一样。
但实际上,绝大多数人对此一头雾水。
说实话,只要你掌握了它的基本思考模型,AI 并没有想象中那么复杂。
无论是 ChatGPT、Claude、Midjourney,还是 Cursor 和各种编程助手,
只要读完下面这 20 个概念,你就能彻底看懂它们。
不需要你有博士学位,不整学术黑话,只有大白话和直观的解释。
建议收藏,你以后一定会反复用到它。
PART 1: AI到底是怎么运行的?(一切黑科技的底层基石)#
1. 神经网络 (Neural Networks)#

这就是所有 AI 模型的“大脑”。
神经网络就像是一条由多层关卡组成的流水线:
→ 数据进入“输入层” → 穿过一层层的“隐藏层” → 最终在“输出层”给出一个预测结果。
在这条流水线上,每个连接点都有一个“权重 (Weight)”——这是一个微小的数值,决定了一个神经元对下一个神经元的影响有多大。
所谓的“训练 (Training)”,其实就是不断微调这数以亿计的权重,直到模型的预测结果足够精准。
这个原理听上去很简单,但当它的规模大到一定程度时,就会产生不可思议的魔力。
比如,GPT-4 拥有大约 1.8 万亿个参数 (Parameters);Claude 3 Opus 也有数千亿个。
它们如此强大,但底层的核心逻辑都是一样的:多层神经元,配合可调节的连接权重。
2. 分词 (Tokenization)#
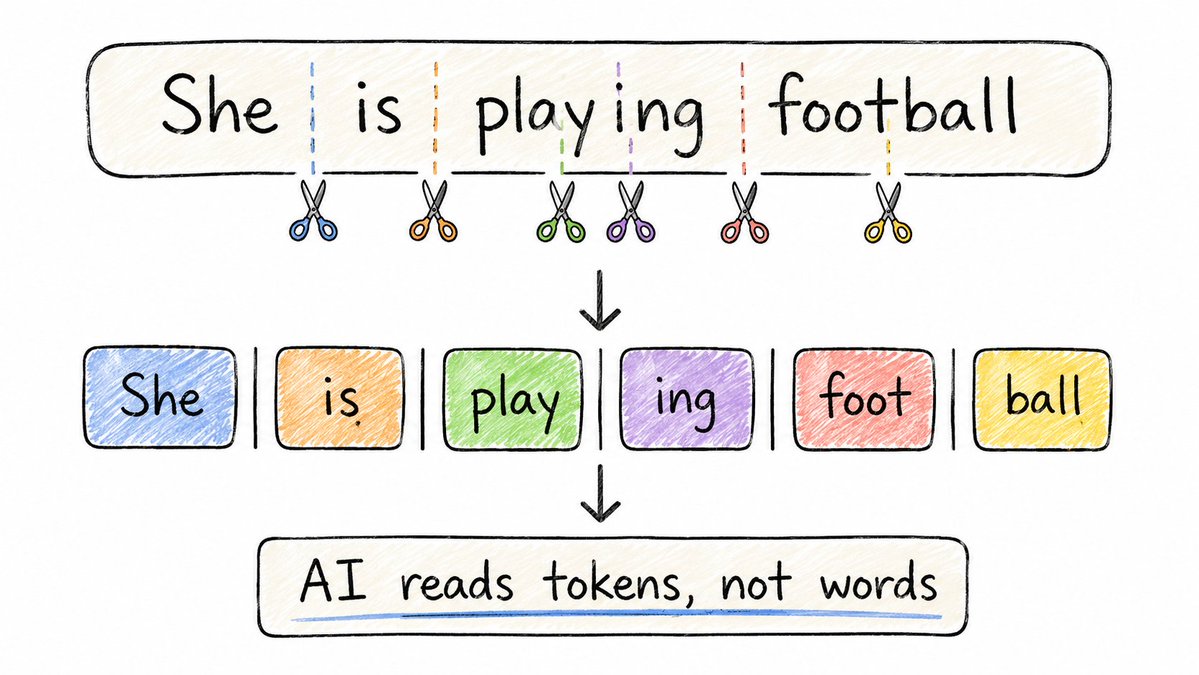
在 AI 阅读你的文字之前,它必须先把它切成一块块的小碎片,这些碎片就叫“Token”(通常被称为分词或标记)。
Token 并不总是完整的单词。
比如:
- "playing" 会被切成 "play" + "ing"
- "ChatGPT" 会被切成 "Chat" + "G" + "PT"
- "dog" 本身比较短,就会保持原样 "dog"
为什么要多此一举,不直接使用完整的单词呢?
因为人类语言太复杂了。每天都会有新词诞生,还有拼写错误、中英夹杂等等。如果把每个词都硬生生塞进一个固定的词汇表,这个词汇表会大到无法想象。
而 Token 就像是乐高积木,可以重复利用。
即使 AI 遇到了一个它从未见过的生词,它也可以通过把这个词拆解成自己熟悉的积木块来理解它。
这里有一个粗略的换算规律:1 个 Token 大约相当于 0.75 个英文单词。也就是说,1000 个 Token 大约是 750 个英文单词。
3. 嵌入 (Embeddings)#

当文本被切成 Token 之后,每个 Token 都会被转换成一串数字。
这串数字就是“Embedding”——我们称之为嵌入,它是一个代表词义的“向量 (Vector)”。
你可以把它想象成“词汇世界的谷歌地图”:
→ “医生 (Doctor)”和“护士 (Nurse)”在地图上的位置非常近;
→ “医生”和“披萨 (Pizza)”的距离就很远;
→ 甚至可以做数学计算:“国王 (King)”减去“男人 (Man)”加上“女人 (Woman)”,在地图上定位到的位置刚好就是“女王 (Queen)”。
AI 并不像人类那样理解文字的字面意思。
它理解的是“距离”和“方向”。
这正是以下功能幕后的功臣:
→ 语义搜索 (Semantic search)
→ 个性化推荐 (Recommendations)
→ 检索增强生成 (RAG) 系统
简而言之,所有能“理解你意图”的系统,底层都在使用嵌入技术。
4. 注意力机制 (Attention)#

“苹果 (Apple)”这个词在不同的语境下代表完全不同的东西:
→ “我吃了一个苹果” —— 这是一种水果。
→ “我买了苹果的股票” —— 这是一家公司。
光靠嵌入是无法区分这两种情况的。
但“注意力机制”可以。
注意力机制让句子中的每一个词都能“看”一眼其他的词,并决定哪些词和自己最相关。
比如在“她买了苹果的股票”这句话里:
→ “苹果”会把极高的注意力分配给“股票”和“买”;
→ 于是模型得出结论:这里的苹果是指公司,而不是水果。
在注意力机制诞生之前,AI 模型只能从左到右一个词一个词地死记硬背。速度慢,效果差。
有了注意力机制,模型可以瞬间把整句话尽收眼底。
正是这一个颠覆性的想法,开启了现代 AI 的新纪元。
5. Transformer 架构 (Transformers)#

这是如今几乎所有 AI 模型的骨架。
它诞生于 2017 年一篇名为《Attention Is All You Need》(注意力就是你所需要的一切)的传奇论文。
它的核心突破在于:不再像以前那样一个词一个词地死板处理,而是利用注意力机制,实现所有文字的并行处理。
它的工作流程是这样的:
→ 原始文本 → 拆分成 Token → 转换成 Embedding(嵌入向量) → 经过多层注意力机制的层层筛选 → 输出结果。
在这一层层的堆叠中,模型的理解会被不断提炼:
→ 浅层(前几层):理解语法、基础结构;
→ 中层:理解词与词之间的关系;
→ 深层:进行复杂的逻辑推理。
其结果就是:模型训练速度呈指数级提升,输出效果也变得好得多。
不管是 GPT、Claude、Gemini、Llama 还是 Mistral,它们通通都是 Transformer。
只要你搞懂了这一个架构,你就搞懂了现代 AI 的大半壁江山。
PART 2: 大语言模型是如何工作的?(当你在和AI聊天时,背后发生了什么)#
6. 大语言模型 (LLMs - Large Language Models)#

大语言模型本质上就是一个在海量文本上训练出来的 Transformer 模型。
这些文本包括书籍、网站、代码、维基百科、Reddit 论坛等,总计包含数万亿个 Token。
它的训练任务听起来简单到让人难以置信:
→ 预测下一个 Token。
仅此而已。
但当你在数万亿的文本案例中重复这个看似单调的训练时,神奇的事情发生了。
模型先是学会了语法,接着学会了逻辑推理,然后学会了写代码、翻译语言、解答复杂的数学题。
没有任何人硬性教它这些规则。
这些能力,都是在超大规模的“预测下一个词”训练中自然涌现出来的。
这里的“大 (Large)”意味着数百亿甚至数千亿的参数量,以及动辄数百万美元的训练成本。
ChatGPT、Claude、Gemini——全都是大语言模型。
7. 上下文窗口 (Context Window)#

每个 AI 模型都有它的记忆极限。
这个极限就被称为“上下文窗口”。
它指的是模型在同一时间能够“看”到的最大 Token 数量——这包括你发的信息、它给的回复,以及你们之前的聊天历史。
- 早期的 GPT:大约 4,000 个 Token;
- GPT-4:128,000 个 Token;
- Claude 3.5:200,000 个 Token;
- Gemini 1.5 Pro:1,000,000 个 Token。
窗口越大,意味着模型可以参考的信息越多,给出的回答也就越精准。
但这里有一个致命的陷阱。
模型并不是平等地阅读窗口里的所有内容。
它们往往极度关注上下文的开头和结尾。
至于中间的内容?经常会被选择性忽视。
这就是著名的“迷失在中间 (Lost in the Middle)”问题。
所以,大上下文窗口并不等于完美的记忆力。
这也解释了为什么有时候你明明在聊天中间提到了某个要求,AI 却转头就忘了。
8. 温度 (Temperature)#

当 AI 在生成文本时,它并不仅仅是死板地挑选概率最高的那一个词。
它身上有一个调节灵感火花的旋钮,叫做“温度”。
→ 温度 = 0:AI 永远选择最稳妥、最可以被预测的词。回答严谨但死板。
→ 温度 = 1:AI 会尝试更多有创意的词汇,回答更加丰富多变。
→ 温度 = 2 或更高:AI 开始放飞自我,思维天马行空,甚至变得胡言乱语。
低温度适用于:写代码、核对事实、总结文章。
高温度适用于:头脑风暴、创意写作、寻找灵感。
虽然大多数 AI 工具会自动帮你设置好这个参数,但了解它能让你明白:为什么 AI 有时候听起来像个无聊的复读机,而有时候又会给你惊艳的意外之喜。
9. 幻觉 (Hallucination)#

AI 会一本正经地胡说八道。
这并不是它故意骗你,而是它在底层运行逻辑上根本无法避免。
原因在于:
大语言模型(LLM)并不懂得去检索事实的真相。
它所做的一切,都只是在预测下一个最可能出现的 Token。
如果一个完全虚假的事实,在句式搭配和训练模式上看起来“顺理成章”,AI 就会毫不犹豫地把它生成出来。
它没有确认机制,也不会去翻阅事实。这只是纯粹的模式匹配。
所以它会:
→ 杜撰一篇根本不存在的学术论文;
→ 发明一个从未被创建过的 API 函数;
→ 极其自信地跟你讲一段虚假的历史“事实”。
这种现象就叫做“幻觉”。
应对幻觉的铁律:永远不要盲目相信 AI 给出的事实性内容,必须亲自动手验证。 或者,使用 RAG 技术(概念 16)让它立足于真实的数据。
10. 提示词工程 (Prompt Engineering)#

你怎么提问,决定了它怎么回答。
同一个模型,同一个问题,只要你的提问框架变了,得到的结果可能天差地别。
- 糟糕的提示词:“解释一下 API。” → 结果:得到一段笼统、空泛、教科书式的苍白回答。
- 优秀的提示词:“请解释 REST API 是如何处理身份验证的。请给出一个带代码的具体实例。假设我是一个初级开发人员。” → 结果:得到一段针对性强、结构清晰且拿来即用的高质量回答。
提示词工程本质上就是清晰高效的沟通。
以下是一些极其有效的提问技巧:
→ 提供上下文(“我正在为 X 开发一个 SaaS 服务……”)
→ 分配一个角色(“请扮演一位资深的后端架构师……”)
→ 给出具体示例(“这是我喜欢的排版格式:____”)
→ 明确输出要求(“请以数字列表的形式给我 5 个方案”)
→ 化繁为简(把复杂的任务拆解成多步进行)
提示词工程不是什么玄学外挂,它是你和 AI 模型沟通的最核心方式。
PART 3: AI模型是如何进化的?(从毛坯模型到好用产品的秘密)#
11. 迁移学习 (Transfer Learning)#

从零开始训练一个 AI 模型,成本是天文数字。
它需要海量的数据、庞大的算力,以及长达数周甚至数月的训练时间。
而“迁移学习”拯救了这一切。
它的逻辑是:我们先拿一个已经在通用任务上训练得非常好的模型,然后稍加改造,让它去适应某个特定的新任务。
这并不是从头开始,而是在巨人的肩膀上做加法。
可以用一个生活中的例子来理解:
→ 你已经学会了骑自行车。
→ 接下来让你去学骑摩托车,你会上手得非常快,因为两者的平衡感是相通的。
→ 这就是你把已有的知识“迁移”了过去。
如今几乎所有的 AI 产品都是这样运作的:
→ OpenAI 先训练好一个庞大的通用基座模型 (Foundation Model);
→ 其它企业在这个基座上,针对自己的具体业务进行微调;
→ 这为企业节省了数百万美元的算力成本和数月的研发时间。
在今天,已经没有公司会从零开始训练一个大模型了。
12. 微调 (Fine-Tuning)#
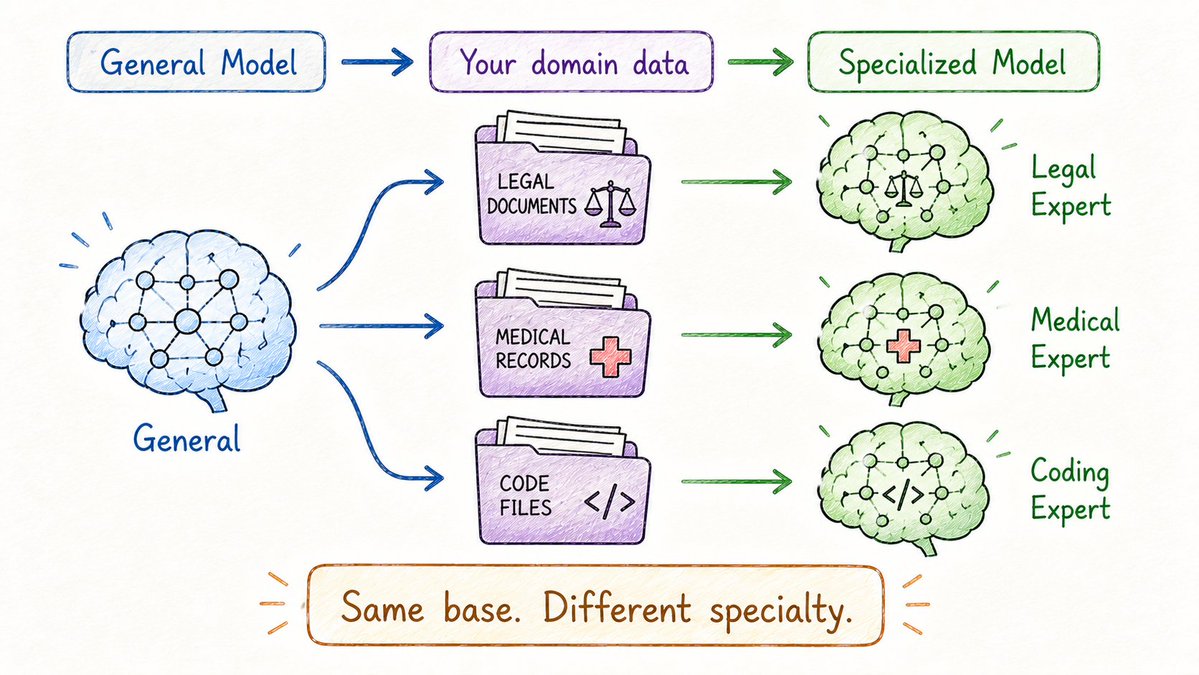
迁移学习是一种方法论,而“微调”则是具体的实操手段。
微调的过程是:把一个已经训练好的预训练模型 (Pretrained Model) 拿过来,用一个规模较小、但高度专业的数据集对它进行二次训练。
这个模型本身已经具备了通用的“语言表达能力”。
而你现在要做的,是教会它你所在的垂直领域的专业知识。
例如:
→ 用临床病历来微调它,得到一个医疗诊断助手;
→ 用法律合同来微调它,得到一个合同审核专家;
→ 用 GitHub 的优质代码来微调它,得到一个编程高手。
这样微调出来的模型,在特定场景下的表现会极其出色。
不过,微调也是有代价的:你需要修改模型内部数以亿计的参数。这需要消耗非常可观的算力,需要配备多张 GPU 以及专业的计算基础设施。(这也是为什么下一个概念 LoRA 如此重要的原因)。
13. 人类反馈强化学习 (RLHF - Reinforcement Learning from Human Feedback)#

微调让模型变得专业,而 RLHF 则让模型变得懂礼貌、更安全。
如果没有 RLHF:模型只会单纯地预测文本。虽然字字通顺,但它可能根本不听指挥,甚至说出不合时宜、不安全的话。
有了 RLHF:模型学会了人类真正喜欢的交流方式。
它的工作流程如下:
→ 给模型一个提示词;
→ 让模型生成几种不同的回答;
→ 由人类对这些回答进行好坏排序;
→ 模型在排序中不断调整,学习如何去迎合人类的偏好。
这个过程会重复成千上万次。
渐渐地,模型建立起了一套关于“什么是好回答”的标准:
→ 结构清晰
→ 有所帮助
→ 诚实不欺
→ 安全无害
这就是为什么 ChatGPT 和 Claude 听起来像是一个贴心的工作助理,而不是一个随机吐字的文本生成器。
没有 RLHF,它们依然很聪明,但绝对不会像今天这样好用、可信且易于控制。
14. LoRA 极低参数微调 (LoRA - Low-Rank Adaptation)#

正如前面所说,传统的全参数微调非常昂贵。
动辄需要多张 GPU 显卡和复杂的服务器架构。
而 LoRA 彻底改变了这一现状。
LoRA 的巧妙之处在于:
→ 它把原始模型的参数全部“冻结”住(不去做任何修改);
→ 在模型之上贴上一个极小的、可训练的“外挂层”;
→ 这个外挂层的参数量仅仅是原模型的一个零头。
LoRA 背后有一个深刻的洞察:绝大多数的微调,参数变化其实都是微乎其微的。你根本不需要重写整个模型,只需要在关键地方打上补丁即可。
LoRA 带来的颠覆性改变:
→ 低门槛:现在你甚至可以在一张普通的消费级家用显卡上完成微调;
→ 高灵活性:你可以只保留一个超大基座模型,然后根据需要随时切换不同的 LoRA 插件;
→ 低成本:无需占用海量存储空间,就能同时运行多个专门用途的模型。
LoRA 是开源 AI 生态在近年来迎来大爆发的幕后推手。突然之间,任何人都能在自己的笔记本电脑上微调出强大的专属模型。
15. 量化 (Quantization)#
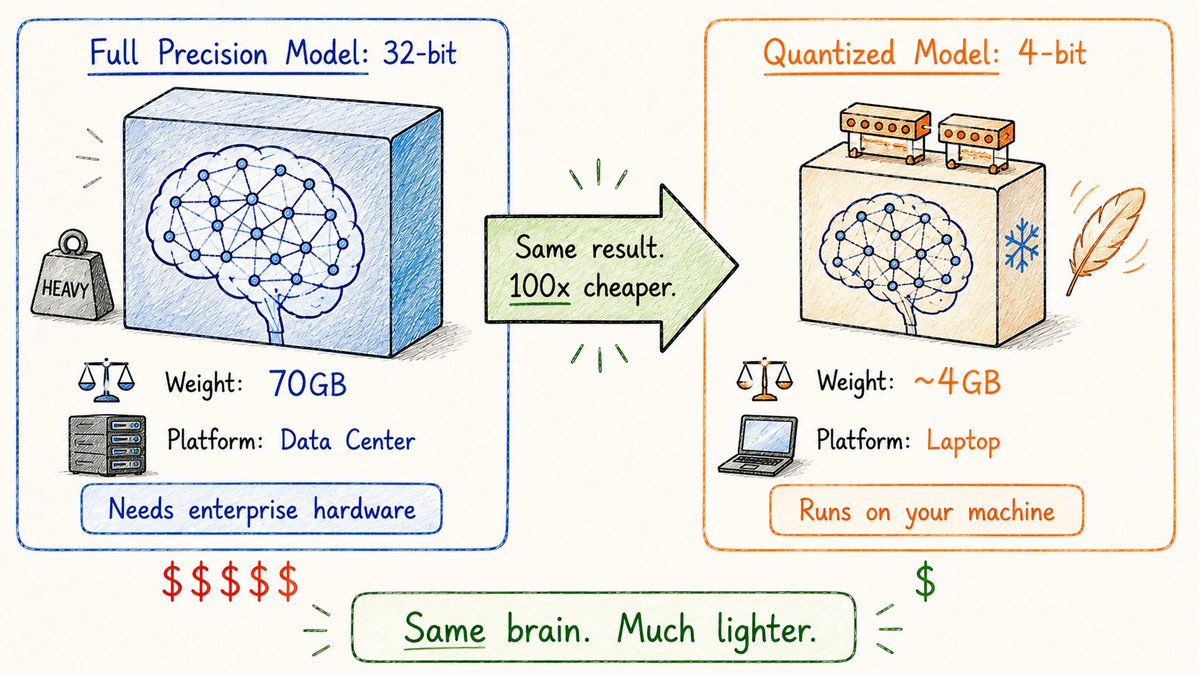
AI 模型正变得越来越庞大。
想要运行它们,需要的内存和算力简直是个无底洞。
而“量化”技术能把这些模型变小变轻,让运行成本大幅降低。
它的原理很简单:降低模型中每个权重的数值精度。
在正常情况下,一个完整精度的权重需要占用 32 位 (32-bit) 的存储空间。
如果将它量化压缩到 4 位 (4-bit)——体积直接缩减到原来的八分之一(8x 变小)。
令人惊叹的是,在这个过程中,模型回答质量的下降幅度小到几乎可以忽略不计。
多亏了量化技术,现在我们才可以:
→ 在一台普通的 MacBook 上流畅运行大模型 LLaMA;
→ 在家用显卡上本地部署并使用 Mistral;
→ 甚至直接在智能手机上本地运行功能强大的 AI 模型。
没有量化,大模型就会被永远锁在巨头们昂贵的数据中心里;有了量化,它们才能真正飞入寻常百姓家。
PART 4: 真实的AI系统是如何搭建的?(你所使用的AI产品背后的工程奥秘)#
16. RAG 检索增强生成 (RAG - Retrieval-Augmented Generation)#

为什么 LLM 容易产生幻觉?因为它们完全是在凭着脑海中的记忆来回答问题。
而 RAG(检索增强生成)解决了这个问题,它让 AI 在回答前,可以先“查资料”。
你可以把它想象成:
→ 闭卷考试(没有 RAG):AI 全凭记忆作答,经常记错或瞎编。
→ 开卷考试(有 RAG):AI 可以先去翻书查阅最准确的资料,再根据资料条理清晰地回答。
它的运行步骤是:
- 用户提出一个问题;
- 系统自动在你的本地知识库里,搜索出和这个问题最相关的文档;
- 将这些文档作为背景资料,连同问题一起喂给 AI 模型;
- AI 模型参照这些真实的文献,给出最准确的回答。
为什么它如此强大?
→ 无需重新训练:当你的数据发生变化时,你只需要更新本地文档,而不用重新去训练昂贵的大模型;
→ 始终保持最新:AI 能够时刻掌握最新的、时效性极强的信息;
→ 大幅消灭幻觉:AI 的回答有据可依,不再信口开河。
现在,每一个严肃的 AI 落地产品都在使用 RAG 技术,包括客服机器人、法律合同助手、医疗问诊、企业内部知识库等。
17. 向量数据库 (Vector Databases)#

既然 RAG 需要先“查资料”,那么它怎么才能在海量的文档里瞬间找到最相关的那一页呢?
如果只靠死板的“关键词匹配”,效果会很差。
这时候,我们需要“向量数据库”。
它们的工作流程是:
- 把知识库里的每一篇文档都转换成 Embedding(向量,也就是一串数字);
- 把这些代表语义方向的数字存入向量数据库中;
- 当用户提问时,系统也把这个问题转换成一个向量;
- 数据库在多维空间里,快速找出和提问向量距离最近、方向最一致的文档向量;
- 把这些语义最吻合的文档调取出来。
为什么这比单纯检索关键词要聪明得多?
→ 当你搜索“心脏病治疗方法”时,系统能自动匹配到包含“心肌梗死临床护理方案”的文档。
→ 尽管这两个短语里没有一个字是重合的,但它们的意思是高度契合的。
常见的向量数据库工具有 Pinecone、Qdrant、Weaviate、pgvector 等。它们是让 AI 系统具备真正的“语义理解”而不是机械比对的关键。
18. AI 智能体 (AI Agents)#
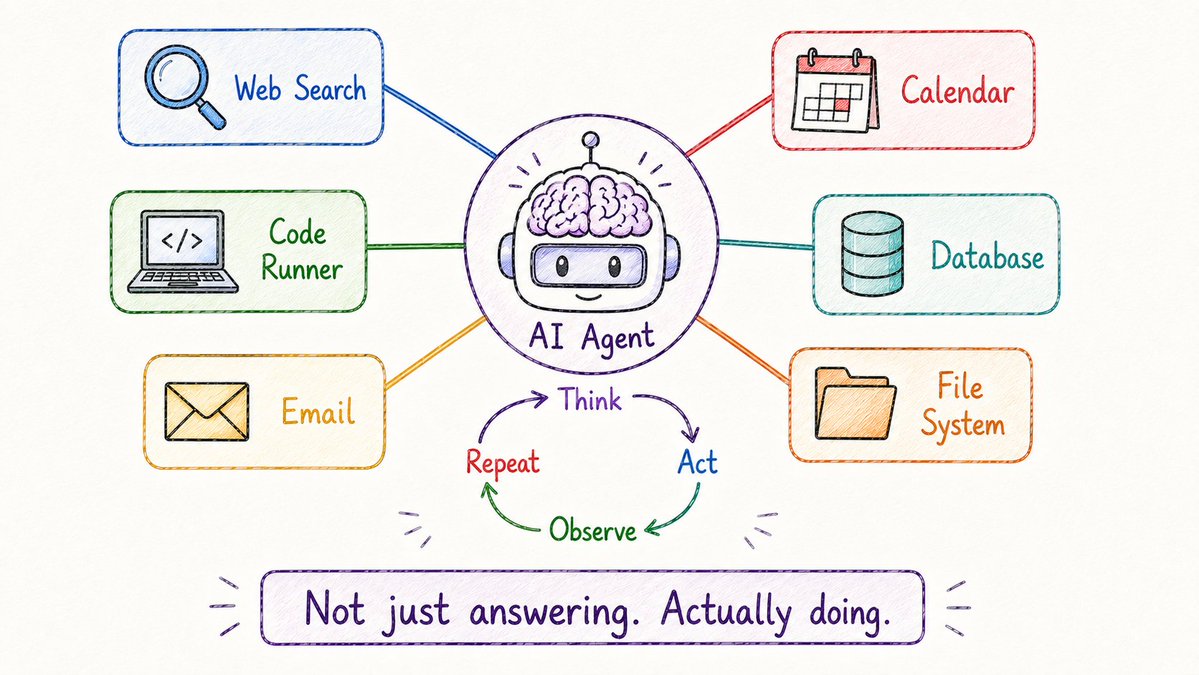
大语言模型只能回答你的消息。
而 AI 智能体(Agent)却能真正帮你把事情办成。
两者的根本区别在于:
→ 大语言模型(LLM):你问,它答,对话结束。
→ 智能体(Agent):你给它一个最终目标,它自己规划步骤、自己调用工具、自己去执行、检查结果、调整方案、直到达成目标。
智能体运行着一个不断自我循环的闭环:
思考 (Think) → 行动 (Act) → 观察 (Observe) → 循环往复 (Repeat)
举个例子,一个帮你修 Bug 的“编程智能体”会怎么做?
→ 第一步:阅读你提交的 Bug 报告;
→ 第二步:自己在代码库里到处翻阅,寻找相关的代码段;
→ 第三步:定位到问题根源,自己动手改写代码;
→ 第四步:自动运行测试,看看改得对不对;
→ 第五步:如果测试报错了,它会根据报错信息重新排查,微调代码,直到测试完全通过。
在这里,AI 模型就是智能体的“大脑”,而它能调用的各种工具就是它的“双手”。
智能体可以使用哪些工具?网页搜索、代码运行环境、文件读写系统、各种 API 接口、发送邮件/管理日程、甚至直接操作数据库。
正是智能体的出现,让 AI 摆脱了“聊天框”的束缚,开始真正成为能够替你分担工作的虚拟同事。
19. 思维链 (CoT - Chain of Thought)#

有时候 AI 给出错误的答案,引导它一步步推理。
“思维链”技术就是为了解决这个问题而诞生的。
它提倡不要让 AI 直接给出最终答案。
- 直接提问:“求解:如果一列火车以每小时 60 英里的速度行驶 2.5 小时,能走多远?”
- 引导思维链:“请一步一步思考并求解该问题:速度 = 每小时 60 英里。时间 = 2.5 小时。距离 = 速度 × 时间 = ?”
这会让模型像人类一样在草稿纸上演算:
→ 第一步:明确公式;
→ 第二步:套入数值;
→ 第三步:算出结果。
对于数学、逻辑推理、复杂的跨步骤任务,思维链能极大地提升准确率。
这个概念背后的精髓在于:给模型留出思考的缓冲空间,而不是让它凭直觉瞬间给答案。
这也是为什么像“请一步步思考”或“让我们仔细理清逻辑”这样的提示词,能奇迹般地提高 AI 回答质量的原因。
20. 扩散模型 (Diffusion Models)#

前面提到的几乎所有概念都和文本有关。
而“扩散模型”则是 AI 能够生成绝美图像背后的秘密。
这个生成过程非常反直觉。
因为扩散模型一开始学习的,引导它一步步推理。
- 训练阶段:准备一张真实的清晰图片; → 往里一步步加入杂音(噪点),直到它变成一幅毫无规律的雪花点乱码图; → 训练模型去学习这个过程的逆反应——如何一步一步把这些杂音拿掉,恢复成原图。
- 生成阶段:扔给模型一张纯粹的雪花噪点图; → 模型开始施展逆向去噪的魔法,一步步把噪点擦除; → 在你的提示词引导下,一幅精美的图片就这样无中生有地从混乱中诞生了。
“扩散”这个名字来源于物理学(粒子在介质中无规则扩散,比如墨水滴进水里)。而在 AI 中,模型学会了如何逆转这种扩散。
如今,这一技术已不再局限于图像领域,它正全面攻占:
→ 视频生成 (如 Sora、Runway 等)
→ 音频合成
→ 3D 模型构建
→ 甚至医疗领域的药物分子设计
扩散模型,正是 AI 创造一切视觉神话的引擎。
尾声#
这就是全部 20 个概念。
让我们快速回顾一下:
第一部分:AI到底是怎么运行的?
- 1. 神经网络 —— 模仿大脑的多层模式学习系统
- 2. 分词 —— 把文本切成乐高积木般的 Token
- 3. 嵌入 —— 将词义化作空间里的数字向量
- 4. 注意力机制 —— 让词与词在相互对视中产生上下文语境
- 5. Transformer 架构 —— 支撑起现代 AI 摩天大楼的钢筋骨架
第二部分:大语言模型是如何工作的?
- 6. 大语言模型 —— 在超大规模文本上训练出来的“下词预测器”
- 7. 上下文窗口 —— 模型的记忆带宽与“迷失在中间”的软肋
- 8. 温度 —— 调节理智与疯狂的灵感旋钮
- 9. 幻觉 —— 自信满满地编造谎言
- 10. 提示词工程 —— 找到与 AI 沟通的最佳频率
第三部分:AI模型是如何进化的?
- 11. 迁移学习 —— 站在巨人的肩膀上学骑“摩托车”
- 12. 微调 —— 用专业数据塑造行业专家
- 13. 人类反馈强化学习 (RLHF) —— 让 AI 懂得人类喜好的行为矫正器
- 14. LoRA 极低参数微调 —— 不需要巨额成本也能玩转微调的开源神器
- 15. 量化 —— 压缩模型参数,让手机本地也能跑大模型
第四部分:真实的AI系统是如何搭建的?
- 16. RAG 检索增强生成 —— 允许 AI 在作答前翻阅资料库的“开卷考试”
- 17. 向量数据库 —— 基于字面背后的“深层含义”进行跨时空搜索
- 18. AI 智能体 —— 从“只会动嘴聊天”到“动手帮你干活”的数字雇员
- 19. 思维链 —— 给 AI 铺设一条一步一个脚印的逻辑演算纸
- 20. 扩散模型 —— 在逆向去噪的冰与火中,凭空创造出视觉艺术
现在,你已经彻底搞懂了 AI 的核心运作机理。
相信我,绝大多数每天都在频繁使用 AI 的人,其实对这些底层的逻辑也只是一知半解。
而这层认知上的信息差,恰恰就是你的核心竞争优势所在。