初级
+29k Stars, 无向量:PageIndex 如何用 LLM 推理替代嵌入
+29k Stars, 无向量:PageIndex 如何用 LLM 推理替代嵌入
VectifyAI 的基于树的 RAG 在 FinanceBench 上达到 98.7%。文档中提到的 MCTS 未包含在开源代码中。#
PageIndex 是一个无向量的 RAG 框架,它从文档构建一个层次树,并让 LLM 推理哪些页面能回答查询。
VectifyAI 于 2025 年 4 月 1 日将其开源。该仓库已获得超过 29k 个 GitHub Stars,并在 GitHub Trending 上成为当日第一。
Mafin 2.5 是一个基于 PageIndex 构建的金融问答系统,在 FinanceBench 的完整 10,231 个问题集上达到了 98.7% 的准确率,评估代码在单独的仓库中公开。证据如下。
仓库快照#

为什么这很重要#
向量 RAG 检索的是看起来像查询的文本,而不是回答查询的文本。嵌入块与嵌入查询之间的余弦相似度匹配是句法上的邻居,而不是语义上的答案。
这种差距在开发者最需要 RAG 发挥作用的地方显现出来:600 页的 10-K 报告、数千页的合规手册、密集的技术规格。PageIndex 颠覆了这一框架。文档获得一个结构树,LLM 选择要读取的节点,答案来自对结构的推理,而不是最近邻召回。
背景#
VectifyAI 由 Mingtian Zhang 和 Yu Tang 创立,于 2025 年 4 月 1 日发布了 PageIndex。13 个月后,该仓库拥有 29k 个 Stars、2,476 个 Forks、138 个未解决问题、11 个贡献者,并在 GitHub Trending 上获得当日第一。其中两位贡献者 rejojer 和 zmtomorrow 贡献了 281 个总提交中的 89.3%。
许可证为 MIT。该包在
pageindex/ 目录下包含 2,579 行 Python 代码,分布在六个文件中。PageIndex 的工作原理#
管道分为两个阶段。

阶段 1:树索引构建。
PyPDF2(默认)或 PyMuPDF 将 PDF 解析为每页文本。LLM 扫描前 20 页以检测目录。从那里分支三种处理模式:带页码的目录、不带页码的目录、或无目录。
系统运行
verify_toc(),对每个目录项与其分配的物理页面进行基于 LLM 的模糊标题匹配。fix_incorrect_toc_with_retries() 对不匹配项最多重试 3 次。如果准确率低于 60%,系统会回退到下一个处理模式。跨越超过 10 页且超过 20,000 个 token 的节点会使用相同的基于 LLM 的提取递归拆分。阶段 2:基于推理的检索。
检索模块为代理运行时暴露三个工具函数:
get_document() 获取元数据,get_document_structure() 获取不含文本内容的树,get_page_content() 获取特定页面。LLM 接收树,在 JSON 响应中选择节点 ID,系统获取这些节点的文本,然后 LLM 写出最终答案。一个节点如下所示:
{
"title": "金融稳定",
"node_id": "0006",
"start_index": 21,
"end_index": 22,
"summary": "美联储...",
"nodes": [
{
"title": "监控金融脆弱性",
"node_id": "0007",
"start_index": 22,
"end_index": 28,
"summary": "..."
}
]
}文档中提到但开源代码未实现的一点:MCTS。
树搜索教程指出,云仪表板和检索 API 使用“LLM 树搜索和基于价值函数的蒙特卡洛树搜索(MCTS)的组合”。开源代码仅提供了 LLM 提示树搜索变体。MCTS 存在于托管服务中。
如何开始#
从克隆到运行一个可工作的代理检索演示,只需五个步骤。
- 克隆并安装。
git clone https://github.com/VectifyAI/PageIndex.git
cd PageIndex
pip3 install --upgrade -r requirements.txt-
设置 API 密钥。在项目根目录创建一个
.env文件,内容为OPENAI_API_KEY=your_key。CHATGPT_API_KEY作为向后兼容的别名受支持。 -
从 PDF 生成树。
python3 run_pageindex.py --pdf_path /path/to/document.pdf输出 JSON 位于
./results/{filename}_structure.json。默认模型为 gpt-4o-2024-11-20,可通过 --model 覆盖。- 运行代理 RAG 演示。这是理解为什么仅树的检索格式值得保留的关键示例。
pip3 install openai-agents
python3 examples/agentic_vectorless_rag_demo.py该演示下载一个 arXiv PDF,通过 PageIndexClient 使用工作区持久化进行索引,创建一个连接到三个检索工具的 OpenAI Agent,然后在回答问题时流式传输代理的推理和工具调用。
- 可选:编程 API。
from pageindex import PageIndexClient
client = PageIndexClient(workspace="./workspace")
doc_id = client.index("document.pdf")
structure = client.get_document_structure(doc_id)
content = client.get_page_content(doc_id, "5-7")证据:FinanceBench 上 98.7%#
VectifyAI 基于 PageIndex 的金融问答系统 Mafin 2.5 报告在完整的 10,231 个问题的 FinanceBench 基准测试(arXiv:2311.11944)上达到 98.7% 的准确率。评估代码(
eval.py)和原始结果 JSON 在 VectifyAI/Mafin2.5-FinanceBench 仓库中公开。98.7% 的数值在两种基础 LLM(GPT-4o 和 DeepSeek v3)上保持一致。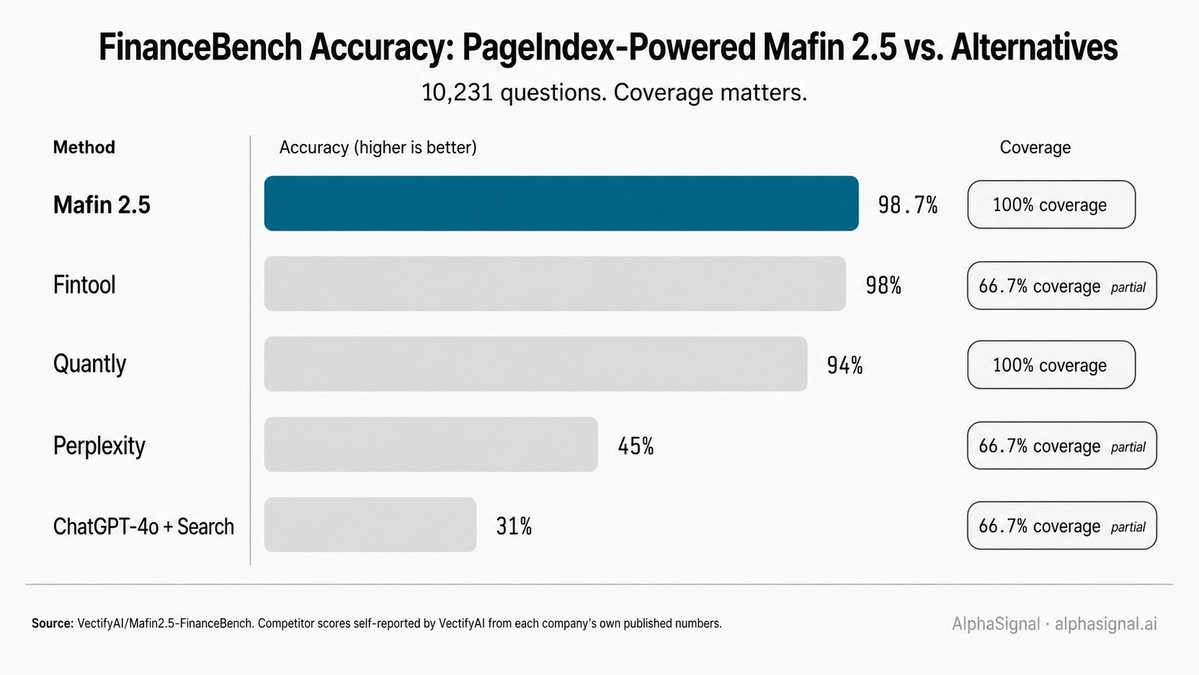
一个阅读说明。VectifyAI 自行报告了对比表。竞争对手的分数来自这些公司自己发布的数据,并非独立复现。覆盖率列很重要:三个比较对象只运行了基准测试的 66.7%,而 Mafin 2.5 覆盖了 100%。
PageIndex vs. 向量 RAG vs. 长上下文 LLM#
PageIndex 是一个框架,而不是一个模型,因此它不适合放入排行榜。真正重要的架构对比:

此外,还有一个使用自托管 PageIndex 和 OpenAI Agents SDK 的无向量 RAG 示例。
PageIndex 的胜利条件是长且结构化的场景。文档有目录或层次标题,答案位于特定部分,而向量存储会返回看起来像查询的邻居,但跳过包含答案的部分。
当前限制#
MCTS 检索仅限云端。
README 和教程中提到了基于价值函数的 MCTS 检索层,但开源代码仅提供了 LLM 提示树搜索变体。期望从仓库中获得与云服务相同检索深度的开发者,实际使用的是功能较弱的版本。
开源 PDF 解析不支持 OCR。
仅内置了标准的 PyPDF2 和 PyMuPDF 解析器。扫描版 PDF、纯图像文档以及格式混乱的财务文件需要预处理或使用云 OCR 服务。
自托管稳定性存在上限。
TOC 验证循环最多尝试 3 次修复(位于
pageindex/page_index.py 中的 fix_incorrect_toc_with_retries)。如果三种处理模式后准确率仍低于或等于 60%,系统将抛出 Processing failed 异常。README 中唯一的稳定性说明是:“对于复杂 PDF 的使用场景,我们的云服务提供增强的 OCR、树构建和检索功能。”实际中布局异常的 PDF 可能会落入失败路径。无 SECURITY.md 文件,存在 6 个未解决的安全问题。
该仓库没有记录安全策略。有 6 个未解决的问题:要么请求添加安全策略(#85, #240),要么报告发现的问题(#79, #80, #81, #174)。LiteLLM 供应链事件已修复:
requirements.txt 将 litellm 锁定在 1.83.7 版本,高于受影响阈值。AlphaSignal 观点#
结论:值得关注。
PageIndex 在树构建方面实现了 README 标题中的承诺。检索功能不完整:开源代码为开发者提供了提示词和三个工具函数,但文档中提到的 MCTS 层并未包含在公开代码中。
维护状况喜忧参半。共有 11 位贡献者,其中 89.3% 的提交来自两人,138 个未解决问题(包括一个稳定性修复请求 #188,有 36 条评论),且没有 SECURITY.md 文件。
当以下四点实现时,结论将升级为“生产就绪”:MCTS 纳入开源路径、提供 SECURITY.md 文件并通过外部审计、团队发布延迟基准测试、以及开源解析器支持 OCR。
在此之前,该框架的结构化文档准确率足以在真实工作负载上进行测试,但还不足以支撑生产系统。请关注 PageIndex 2.0 或 MCTS 开源版本的发布作为触发信号。
适用与不适用场景#
适用:针对长结构化文档(如 10-K 报告、合规文件、合同、技术手册)构建问答系统的 ML 和后端工程师;在长文档向量 RAG 中遇到召回率瓶颈的团队;以及已为前沿模型 API 调用付费,并愿意用查询延迟换取检索准确率的团队。
不适用:对短文档进行延迟敏感的实时聊天场景;没有 LLM API 预算用于大规模检索的团队;需要 OCR 处理的扫描文档工作流;以及安全策略不明确会阻碍部署的生产环境。
实践启示#
现在,你可以回答一份 600 页 10-K 报告中的问题,而无需嵌入任何向量。PageIndex 的树推理方法在 FinanceBench 的完整 10,231 个问题集上达到了 98.7% 的准确率。
链接#
- PageIndex 仓库(+29k 星标,MIT 许可,约 5 分钟设置)
- Agentic RAG 演示(OpenAI Agents SDK 集成)
- Mafin2.5-FinanceBench 评估仓库(公开评估代码和原始结果)
- pageindex-mcp(MCP 服务器)
- PageIndex 框架介绍(官方深度解析)
关注 @AlphaSignalAI 获取更多类似内容。
在 AlphaSignal.ai 订阅,获取每日 AI 信号。已有超过 280,000 名开发者阅读。
常见问题#
问:什么是 PageIndex?
答:VectifyAI 开发的一种无向量、基于树的 RAG 框架。它从文档构建层次树,让 LLM 推理哪些节点包含答案,整个过程无需嵌入或向量存储。
问:PageIndex 与向量 RAG 有何不同?
答:向量 RAG 通过嵌入相似性检索文本块,优化的是句法邻居。PageIndex 完全跳过嵌入,依靠 LLM 在结构树上进行推理,选择最可能回答问题的章节。
问:PageIndex 在哪些基准测试中取得了成绩?
答:基于 PageIndex 构建的 Mafin 2.5,在 FinanceBench 的完整 10,231 个问题集上报告了 98.7% 的准确率(数据来自 VectifyAI 的公开评估仓库)。该结果在 GPT-4o 和 DeepSeek v3 基础 LLM 上均保持一致。
问:我可以自托管 PageIndex 吗?
答:可以。该仓库采用 MIT 许可。完整流程为:
git clone + pip3 install -r requirements.txt + 在 .env 文件中配置 OpenAI API 密钥。扫描版 PDF 的 OCR 功能仅限云端。问:PageIndex 是否已生产就绪?
答:值得关注,但尚未达到生产级。README 将其标记为早期测试版。没有 SECURITY.md 文件,且文档中提到的 MCTS 检索层未包含在开源代码中。