Beginner
6种架构模式+60%质量提升:这个开源项目把 Harness Engineering 从概念变成了工具
6种架构模式+60%质量提升:这个开源项目把 Harness Engineering 从概念变成了工具
上周我们聊了 Anthropic 和 OpenAI 两家大厂对 Harness Engineering 的不同理解,也梳理了九位博主从力挺到质疑的各种立场。概念讨论很热闹,但一个关键问题悬而未决:具体怎么落地?现在有人给出了答案
开发者 revfactory 做了一个叫 Harness 的 Claude Code 插件,直接把 Harness Engineering 的理念变成了可安装、可运行的工具。你告诉它你要做什么,它自动帮你生成一整套 Agent 团队架构,包括 Agent 定义文件、Skill 文件、协作协议、测试用例,全部落到 .claude/agents/ 和 .claude/skills/ 目录里
拆开看看这个项目做了什么
六种架构模式,覆盖了绝大多数协作场景#

Harness 内置了六种 Agent 团队协作模式,每种对应一类典型任务
Pipeline(流水线) 适合强依赖的顺序任务。上一个 Agent 的输出直接喂给下一个。比如写小说:世界观设定完了才能设计角色,角色定了才能编剧情。瓶颈很明显,任何一个环节卡住整条线都停
Fan-out/Fan-in(扇出/扇入) 是最自然的多 Agent 模式。多个专家同时并行分析同一个输入,最后汇总结果。做行业研究的时候特别好用,一个 Agent 查官方文档,一个查媒体报道,一个查社区讨论,一个查竞品背景,最后合成一份完整报告
Expert Pool(专家池) 由路由器根据输入类型动态分配给对应专家。代码审查是典型场景,安全问题找安全专家,性能问题找性能专家,不需要所有人同时在线
Producer-Reviewer(生成-评审) 直接呼应了 Anthropic 那篇文章的核心发现。Agent 评估自己的工作几乎没用,必须拆成独立的生成器和评审器。Harness 把这个模式产品化了,内置最多2到3轮重试限制防止死循环
Supervisor(主管) 和 Fan-out 的区别在于动态分配。Fan-out 是一开始就分好任务,Supervisor 是运行时根据实际情况调度。大规模代码迁移就适合这个模式,主管分析文件列表,按复杂度动态分批给不同的迁移 Agent
Hierarchical Delegation(层级委派) 处理特别复杂的问题,递归式地把大任务拆成小任务往下派。限制在两层以内,再深就会出现延迟和上下文丢失
六种模式不是随便选的。Harness 在第二阶段(Team Architecture Design)会根据四个维度自动判断:专业化程度、并行潜力、上下文范围、可复用性
五个真实团队配置案例#

光有模式定义还不够,Harness 附带了五套完整的团队配置模板
研究团队用 Fan-out/Fan-in 模式,4个专业研究员加1个协调器。官方文档研究员、媒体研究员、社区研究员、背景研究员各自并行工作,发现矛盾信息时通过 SendMessage 交叉验证
科幻小说团队混合了 Pipeline 和 Fan-out,6个 Agent 分4个阶段。第一阶段世界观设计师、角色设计师、剧情架构师三个并行且互相通信。第二阶段文笔师写初稿。第三阶段科学顾问和连续性检查员并行审核。第四阶段文笔师修改终稿。最有意思的是每个阶段的团队用完就销毁,下一阶段重新创建
Webtoon 制作团队用 Producer-Reviewer 模式,只有2个 Agent,画师生成分镜,审核员给三种结果:PASS、FIX、REDO。最多重试2轮就强制通过,防止完美主义死循环
代码审查团队用 Fan-out/Fan-in 加上同行辩论机制。安全审查员、性能审查员、测试审查员三个并行工作,关键点在于审查员之间可以直接 SendMessage 交叉验证。比如安全审查员发现 SQL 注入风险会直接通知性能审查员检查相关查询
代码迁移团队用 Supervisor 模式,1个主管动态调度 N 个迁移执行器。主管按复杂度分批分配文件,执行器认领任务并报告进度,失败的任务自动重新分配
A/B 测试数据:60% 质量提升,100% 胜率#
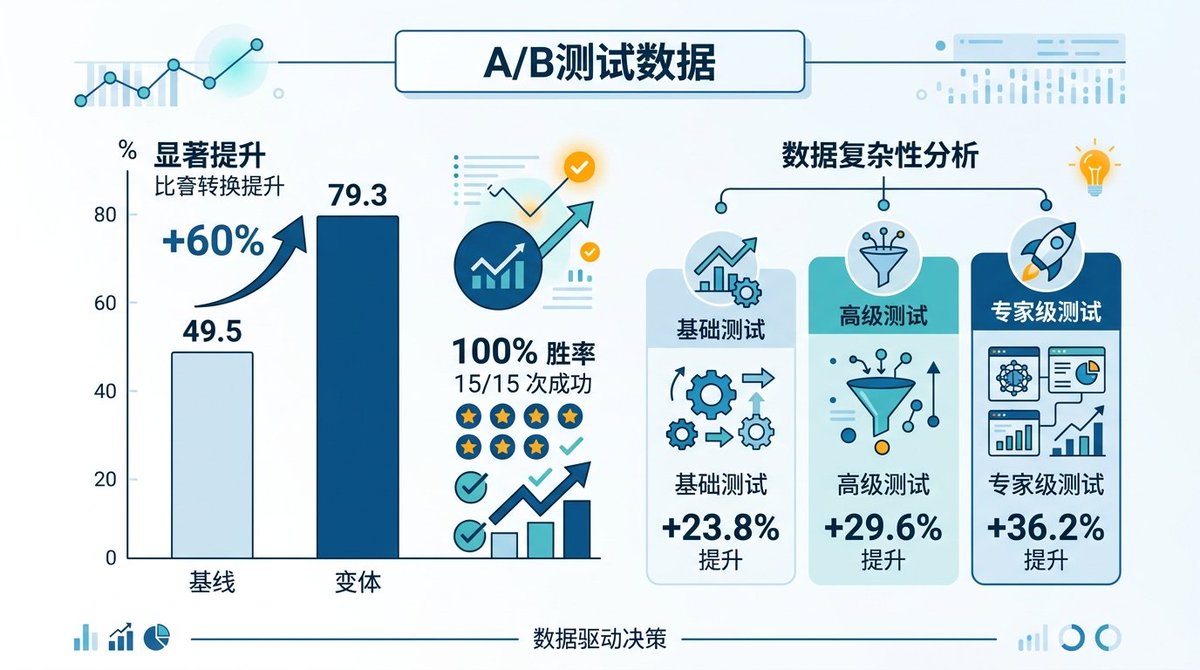
这个项目最有说服力的是它附带了一组 A/B 测试数据
15个软件工程任务,分别用有 Harness 和没有 Harness 两种方式完成。结果:平均质量评分从 49.5 提升到 79.3,提升幅度 60%。15个任务里 Harness 方案赢了15个,100% 胜率。输出的方差降低了 32%,意味着结果更稳定可预测
更有意思的是按任务复杂度分层看:基础任务提升 23.8%,进阶任务提升 29.6%,专家级任务提升 36.2%。任务越复杂,Harness 的价值越大。这和 Anthropic 那个实验的结论高度一致,单 Agent 做简单的事还行,复杂任务没有 Harness 基本做不出来
Progressive Disclosure:解决 Skill 上下文爆炸#
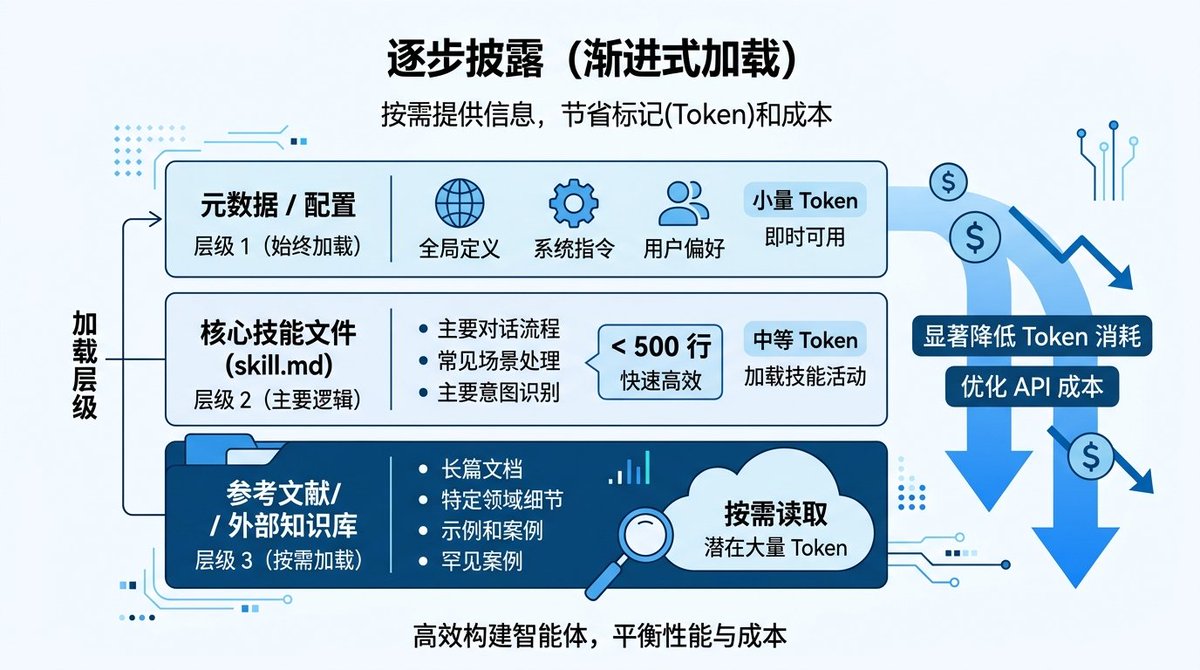
Harness 在 Skill 生成上用了一个叫 Progressive Disclosure(渐进式披露)的设计,解决了一个很实际的问题:Skill 文件写太长会吃掉大量上下文窗口
做法是分三层:元数据层永远加载(名字、描述、触发词),skill.md 主体控制在500行以内,详细的参考资料放到 references/ 目录下按需加载。这样 Agent 平时只消耗很少的 token,需要深入某个领域的时候再加载对应的参考文档
这个思路对所有写 Claude Code Skill 的人都有参考价值。我们自己的发布 Skill 已经超过600行了,或许也该考虑把 troubleshooting 和模板细节拆到 references 里
从概念到工具,三个转变#

回头看我们之前梳理的全景图,这个项目把 Harness Engineering 从概念讨论推进到了工具化阶段
第一个转变:从"你需要设计 Harness"到"帮你自动生成 Harness"
Anthropic 和 OpenAI 的文章本质上都是在说"Harness 很重要,你应该好好设计"。但怎么设计?用什么模式?Agent 之间怎么通信?这些问题留给了读者自己摸索。Harness 这个项目把选型和生成都自动化了,你描述需求,它输出完整的架构
第二个转变:从单一模式到模式库
之前的讨论里,Anthropic 重点讲了 Producer-Reviewer(生成器+评估器),OpenAI 重点讲了 Pipeline(分层架构)。但实际场景远比这两种丰富。六种模式的体系化覆盖了从简单到复杂的大部分协作需求
第三个转变:从"我觉得好"到"数据说话"
质疑派 Chayenne Zhao 说得对,光靠概念文章很难判断 Harness Engineering 到底有没有用。这个项目用15个任务的 A/B 测试给出了量化证据。60% 的质量提升和 100% 的胜率不是概念,是数字
值得关注的设计细节#

几个容易忽略的设计选择
所有 Agent 调用强制指定 model: "opus"。Agent 团队场景下推理质量直接决定协作质量,用弱模型省 token 但协作容易崩
文件系统作为协作基础设施。Agent 之间的中间产物统一存到 workspace/ 目录,命名规范是 _.。这和 Leo 在社区讨论中提到的观点完全一致:文件系统是最基础的原语,因为只有文件能同时解决持久化、跨 session 协作、多 Agent 共享状态
验证框架不是走形式。每个 Skill 要写8到10个应该触发的查询和8到10个不应该触发的查询,特别强调 near-miss 测试用例。这种严谨度在大多数 Agent 工具里很少见
团队规模有硬限制。2到7个成员,每人3到6个任务。层级委派最多两层。这些约束来自实践中踩过的坑,Agent 太多协调成本指数增长,层级太深上下文丢失严重
局限性和待观察的点#

几个限制也要说清楚
Agent Teams 功能需要手动开启环境变量 CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1,说明这个能力在 Claude Code 里还是实验性的。稳定性和性能还需要更多实际使用来验证
A/B 测试的15个任务都是软件工程场景,其他领域(写作、研究、设计)的效果还没有数据支撑
六种模式之间的选型建议目前还比较粗粒度,实际场景中很可能需要混合使用。科幻小说那个例子就同时用了 Pipeline 和 Fan-out,但这种混合模式的最佳实践还在摸索中
不过作为第一个把 Harness Engineering 从概念变成可安装工具的项目,方向没问题。至少我们可以停止争论"Harness Engineering 有没有用",开始研究"怎么用得更好"了