Beginner
不要建一千个 Agent:Ramp 如何用一个 Agent 搞定金融自动化
不要建一千个 Agent:Ramp 如何用一个 Agent 搞定金融自动化
Ramp 是美国增长最快的企业金融平台之一,估值 320 亿美元,超过 50,000 家客户,年交易处理量超过 1000 亿美元。在 The Pragmatic Summit 上,Ramp 派出了四人阵容分享他们过去一年在 AI 领域的实战经验:工程执行副总裁(EVP)Nik Koblov、应用 AI 总监 Viral Patel、以及两位资深工程师(Staff Engineer)Will Koh 和 Ian Tracey。
他们聊了五件事:为什么从“建一堆 Agent”转向“一个 Agent + 一千种技能”,Policy Agent 从零到上线的全过程,怎么定义“正确”,怎么建内部 AI 基础设施,以及一个让 50% 以上 PR 都由 AI 生成的内部编码 Agent。
要点速览#
- Ramp 去年让各团队自由实验 Agent,结果产生了四种实现方式和五个对话界面,最终认为应该收敛为“一个 Agent + 一千种技能”的架构
- Policy Agent 最大的错误来源不是模型本身,而是给模型的上下文不够。员工职级、收据细节、商户信息这些上下文比换模型更管用
- 用户的审批行为不能作为“正确”的标准,Ramp 建了跨职能团队每周标注数据来定义自己的基准答案(ground truth)
- Ramp 内部编码 Agent“Inspect”当月产出了超过 50% 的合并 PR,使用者包括产品、设计、法务、营销等非工程团队
- AI 时代工程师的价值不在于写代码的速度,而在于判断力:知道该建什么,以及知道 AI 建的东西哪里不对
一杯咖啡背后的 15 分钟#
Nik Koblov 用一个所有人都能理解的场景开场:一笔咖啡消费。
买一杯咖啡,在传统流程里要花大约 15 分钟的行政时间。写备注,按公司的会计科目分类,找收据、附收据,把商户名称规范化到公司的商户库里。这些事情在公司层面不断累积。
Nik Koblov 用“一杯咖啡”解释企业金融里那些最容易被忽视的手工流程成本。

Ramp 做的事情,最简单的理解方式,就是把这 15 分钟压缩到接近零。从刷卡到写备注到分类到收据,全部由 Agent 自动完成。这是 Ramp 大约三年前就开始做的事,最早是用 AI 做单步处理,比如规范化商户名、自动写备注。随着模型能力提升,效果越来越好。
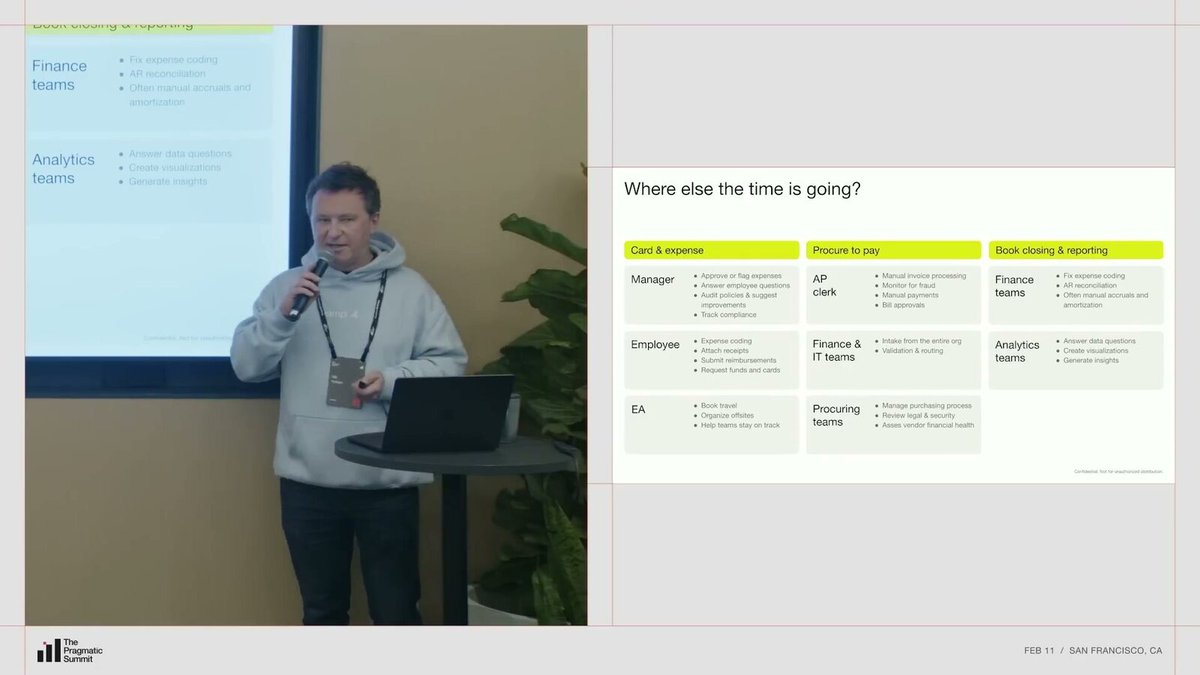
但这只是起点。Ramp 平台上几乎每个角色都在做大量手动工作:AP 专员(应付账款)处理发票,财务团队对账,采购团队比价,数据团队跑报表。Nik 提到一个细节:Ramp 以前有一个 Slack 频道叫 help-data,有人需要数据就在里面发请求,然后有个可怜人去写 SQL 查询。这个频道大约一年半前被 AI 替代了。
从卡费、采购到关账和分析,Ramp 试图把这些分散在各团队里的碎片工作都交给 Agent。
不要建一千个 Agent#
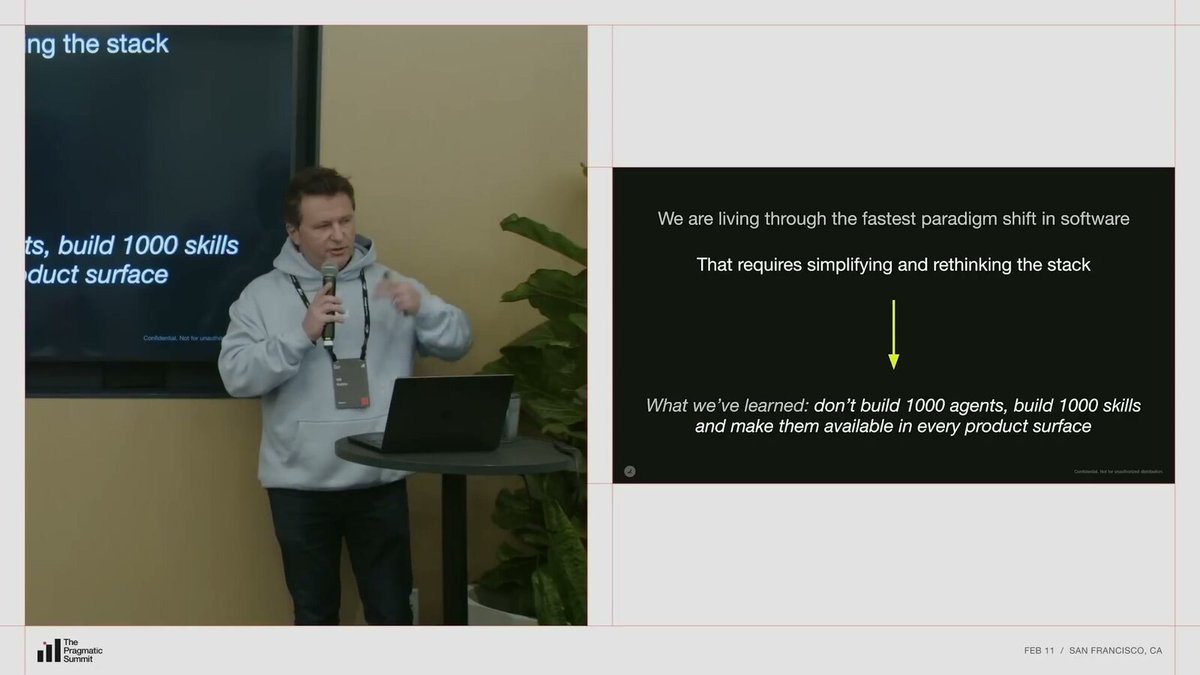
Nik 说,Ramp 在 AI 方面正在经历软件行业最激动人心的范式转变。这个转变要求彻底重新思考,同时也意味着简化技术栈。
他们学到的教训是:
你不需要建一千个 Agent。你应该把框架收敛为一个 Agent 配一千种技能。 (“You don't need to build a thousand agents. Instead you want to drive your framework towards a single agent with a thousand skills.”)
Ramp 给出的架构判断很直接:收敛 Agent,扩张技能。
去年 Ramp 有意让各个团队自由实验。结果他们发现,公司内部出现了大约四种不同的方式来做同一件事,同步 Agent 和后台 Agent 各有好几套实现。同时,对话界面也膨胀到了五个。
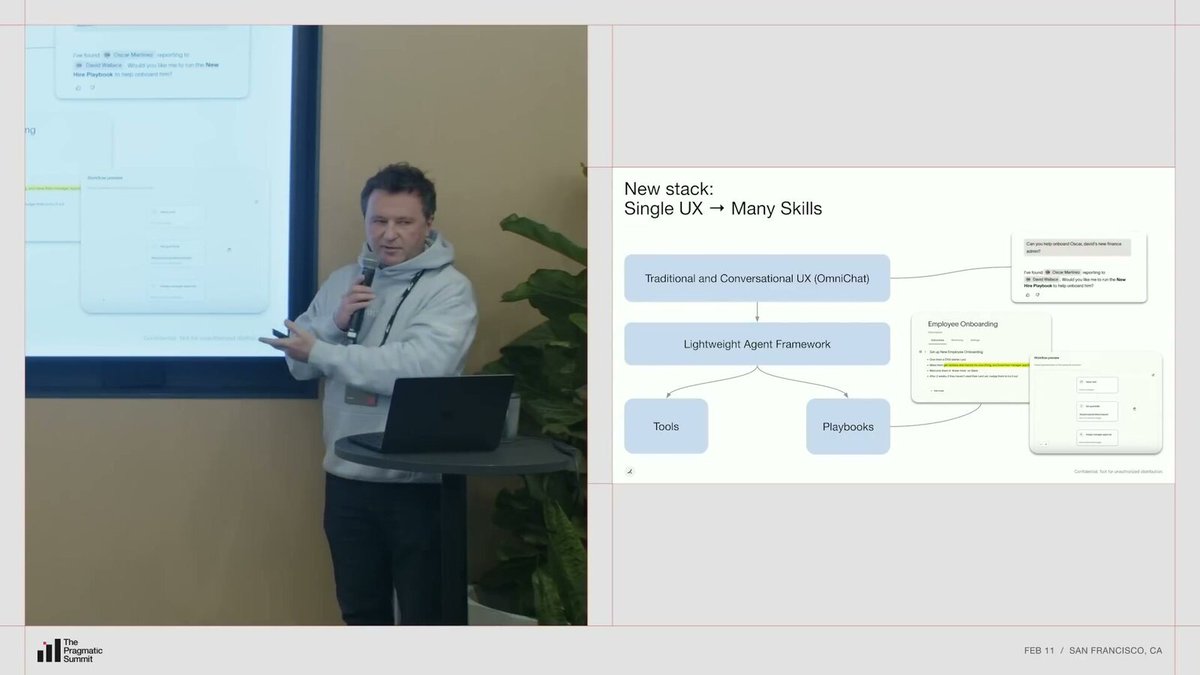
现在 Ramp 把所有对话交互收敛到一个叫 Omnihat 的统一界面。Omni 取“无所不在”之意,正在部署到产品的每个界面上。它和传统 UX 配合使用,因为你不总是想跟软件“说话”,有时候表格和按钮就够了。
Nik 展示了一个例子:在 Omnihat 里输入“请帮我入职一位新员工”,Agent 会自动解析员工 ID,通过 HRIS(人力资源信息系统)工具查询组织架构,然后找到一个之前创建的工作流“新员工入职手册”,问你是否要用这个流程来入职。
这背后是 Ramp 自建的一个轻量级 Agent 框架,提供编排能力和工具。工程师可以很快构建新工具。最近有一位产品经理通过凭感觉编程(vibe coding)构建了大约 20 个工具,完全不需要工程师参与。
统一对话入口、轻量框架和工具层,构成了 Ramp 所说的“一个 Agent + 一千种技能”。
对于复杂流程,比如员工入职包含四个步骤(发卡、设置收据要求、在 Slack 上欢迎、两周后跟进),用户可以在 Ramp 上用自然语言描述想要的流程,系统会把它编译成一个可运行的确定性工作流,然后交给 Agent 执行。
费用政策就是“代码”#
Ramp 的 Policy Agent 是他们最受欢迎的 Agent 产品之一。
Viral Patel 接过话题,先展示了一个实际场景:财务团队每天要审核成百上千张收据。他拿出一张收据说,如果让他肉眼判断这笔交易该批准还是拒绝,他大概率会出错。
但 Policy Agent 对这张收据做了推理:识别出有 8 位客人(Viral 说他自己勉强才看清这个数字),确认低于公司内部每人 80 美元的上限,判断这是一次团队欢迎晚餐,建议批准。另一笔 OpenAI 的交易,某位员工在测试 ChatGPT 功能,Policy Agent 判定为合理业务支出,批准。还有一笔 3 美元的面包店消费被拒绝,因为它不属于加班购买,也不是在周末。
这些案例背后的产品理念来自一个机会:一家世界 500 强客户找到 Ramp,拿着一长串规则说:“帮我们按这些审批和拒绝。”
Policy Agent 不只是读规则,它还要和会计、记账等其他 Agent 配合,把决策真正落到系统里。

Ramp 可以继续走老路,把这些规则硬编码为确定性逻辑,一条条加进产品里。但他们选择了另一个方向。Viral 引用了 Andrej Karpathy 的说法:英语是新的编程语言。他们决定把费用政策文档本身变成规则,让 Agent 直接读懂自然语言的政策文档并据此执行。
【注:Andrej Karpathy 是 OpenAI 联合创始人之一、特斯拉前 AI 负责人。“英语是最热门的新编程语言”是他 2023 年发的推文,后来成为 AI 时代的标志性金句。】
【注:Ramp 官方数据显示,截至 2025 年 10 月,Policy Agent 在超过 100 亿美元的支出中做出了 2600 多万次决策,阻止了 51 万笔违规交易,节省了约 2.9 亿美元。】
AI 产品不能一步到位#
Viral 和 Will Koh 都强调了一个核心教训:
AI 产品不能一步到位。你必须从简单的东西开始。 (“AI products cannot be oneshotted. You need to start with something simple.”)
Viral 认为这是一个文化层面的共识:产品经理、设计师、工程师都必须接受第一天不会完美这个前提。
他们一开始也想大干一场,“让我们自动化整个财务审核”。但真正动手时,他们选择了最小的切入点:一杯咖啡的报销。这些单笔小额交易风险低,财务团队不太在意。
Ramp 把第一步压到最小:先解决一类高频、低风险、但很烦的审批场景。

Ramp 先在内部做了大量 dogfooding(自己试用自己的产品),用公司内部的交易数据来训练和测试 Policy Agent。
一个关键发现改变了他们的思路:
Policy Agent 出错的原因,大多不是模型本身,而是我们给 LLM 的上下文不够。 (“A lot of the reason that policy agent would be wrong would be less on the models themselves and more about the context that we were giving to LLMs.”)
他们可以一开始就坐下来想清楚所有需要的上下文,但他们发现最好的方式是从内部实际数据中学习。比如他们发现,员工的职级和头衔对费用审批影响巨大。C 级高管(CEO、CFO 等)可能有更高的消费限额,出差可以坐头等舱。这种信息如果不放进上下文,Agent 就会做出错误判断。
于是他们开始从收据中提取更多信息,从 HRIS 系统中拉入员工资料。每次发现一个新的上下文维度,就加进去,再观察效果。
从简单流水线到 Agent 自主循环#
Will 详细讲述了 Policy Agent 架构的三个演进阶段。
第一阶段很简单:费用进来,检索相关上下文,通过一系列定义清晰的 LLM 调用判断“是否合规”“为什么合规”“怎么向用户展示合规理由”,然后输出结果。
第二阶段开始有了条件分支。他们发现每种费用类型差别很大:差旅、餐饮、娱乐各有不同的判断逻辑。于是加入了费用分类,根据类型做条件化的提示词和上下文检索,同时给 LLM 一些工具,让它能自主决定“我需要查航班信息”或“我需要查这位员工的职级”。
几轮迭代后,到了第三阶段:完全的 Agent 化工作流。Agent 可以读取 Ramp 平台上的所有数据,有一套公司内部共享的工具箱(不只是 Policy Agent 用,所有 Agent 都能用)。它现在不只是读,还能写:写审批决策,写推理过程,直接替用户批准费用。而且它在一个循环中工作,可以多次调用工具、收集信息、做出判断。
这张 slide 几乎就是 Ramp 的方法论:先做简单流水线,再逐步增加条件分支、工具和自主循环。
Will 坦言,这带来了一个经典的权衡:能力上去了,自主性上去了,但可追溯性和可解释性下降了。一个小黑盒变成了大黑盒。你可以看推理 token,但本质上你无法控制它会做什么。
用户不一定对#
既然黑盒在变大,可审计性就变得格外重要。Will 提出一个原则:即使你知道系统内部怎么运作,也要假设你只能看到输入和输出,然后验证输出是否正确。
但这引出了一个更根本的问题:什么是“正确”?
用户其实经常是错的。 (“Turns out the users are actually incorrect. They're wrong.”)
最初他们以为用户的行为就是标准答案:用户批准了,Agent 就应该批准;用户拒绝了,Agent 就应该拒绝。但实际上,很多用户不了解公司的费用政策,有些太信任下属懒得细看,有些是周末审批随手点了通过。财务团队事后会回来说“这笔不应该放行的”。
所以 Ramp 必须建立自己的正确性定义。他们的做法是每周召集跨职能团队进行数据标注会议,包括工程师、PM、设计师等共同参与。
Ramp 把“用户操作”从答案里拿掉,转而用跨职能标注去定义自己的 ground truth。

这带来了两个好处。第一,他们有了一个可以持续测试的基准答案数据集,确定这些标注是对的。第二,所有人对齐了认知。如果 Agent 错了,大家都知道错在哪;如果 Agent 缺少上下文,大家也清楚缺什么。减少了沟通成本,团队能快速聚焦到真正的优先事项上。
用 Claude Code 一把搞定标注工具#
但每周把一群人叫到一起,让他们标注 100 个数据点,成本很高。Will 说大家都有自己的事,有时候根本没做完“作业”就来开会了。
所以他们想让标注过程尽可能简单。先看了第三方工具,发现有的太专用,有的太通用,光是试不同工具就得花好几周。于是他们决定自己建。
用 Claude Code 和 Streamlit,他们基本上一次性搞定了整个标注工具。 最大的好处是维护成本低,风险也低。它在代码库中一个独立的角落,坏了能马上修。部署几乎是秒级的。非工程师也能去改它,直接 vibe code 就行。
Ramp 没有在标注平台上纠结太久,而是用 Claude Code 和 Streamlit 先把能跑的内部工具做出来。

【注:Streamlit 是一个 Python 开源框架,可以快速构建数据应用的 Web 界面。】
Eval 从 5 个样本开始#
有了基准答案数据集,迭代速度大幅提升。发现需要员工职级信息?加进去,跑一遍数据集,看能不能正确捕获新场景。
Will 说,他觉得 eval 的概念现在大家都知道了,但他想强调的是**“早做”**。不要追求完美,不需要一上来就有 1000 个数据点。他们从 5 个开始,确保这 5 个绝对不会出错,然后不断积累。
几个实操要点:确保任何人都能轻松运行 eval 命令,确保结果一目了然(好的、坏的一眼能分清),把它集成到 CI(持续集成)中让每次代码合并都自动跑。
Ramp 的 eval 体系不是“做大再说”,而是先让团队能反复跑、敢切模型、敢持续加上下文。

给 LLM 更多上下文、更多工具,往往会带来意想不到的副作用。上下文腐化(context rot,上下文过多反而导致模型性能下降)、工具说明写得模糊或矛盾,这些问题不跑 eval 根本发现不了。
在线评估(online eval)也有价值。他们有一个“不确定”的决策类型,意味着 Agent 认为信息不足以做出判断。监控这个比率的变化,就是一个简单但有效的系统健康度指标。
另外,有了完善的 eval 体系,切换模型变得有底气。每当新模型发布,跑一遍 eval 就知道该不该切。新模型可能让某些问题变好,但也可能让另一些变差。没有 eval,你根本不敢动。
让用户修改自己的“Claude.md”#
Policy Agent 上线后,Will 分享了一个发现:工程师用 Claude Code 时可以修改 Claude.md 文件来控制 Agent 行为,财务人员其实也有同样的需求,只是他们的“Claude.md”是公司的费用政策文档。
【注:Claude.md 是 Claude Code 的项目配置文件,开发者可以在其中写下项目约定和偏好来引导 AI 的行为。】
如果 Policy Agent 的决策不对,Ramp 的建议是:“去更新你的费用政策文档。”这对财务人员来说一开始有点吓人。费用政策是正式文件,不是随便能改的,改动要走审批流程。
但一旦他们发现修改后能立即看到效果,态度完全反转。这种即时反馈循环让他们兴奋起来。
Ramp 的产品反馈循环很像工程师调 Agent:策略写进文档,修改后立刻看到系统行为变化。
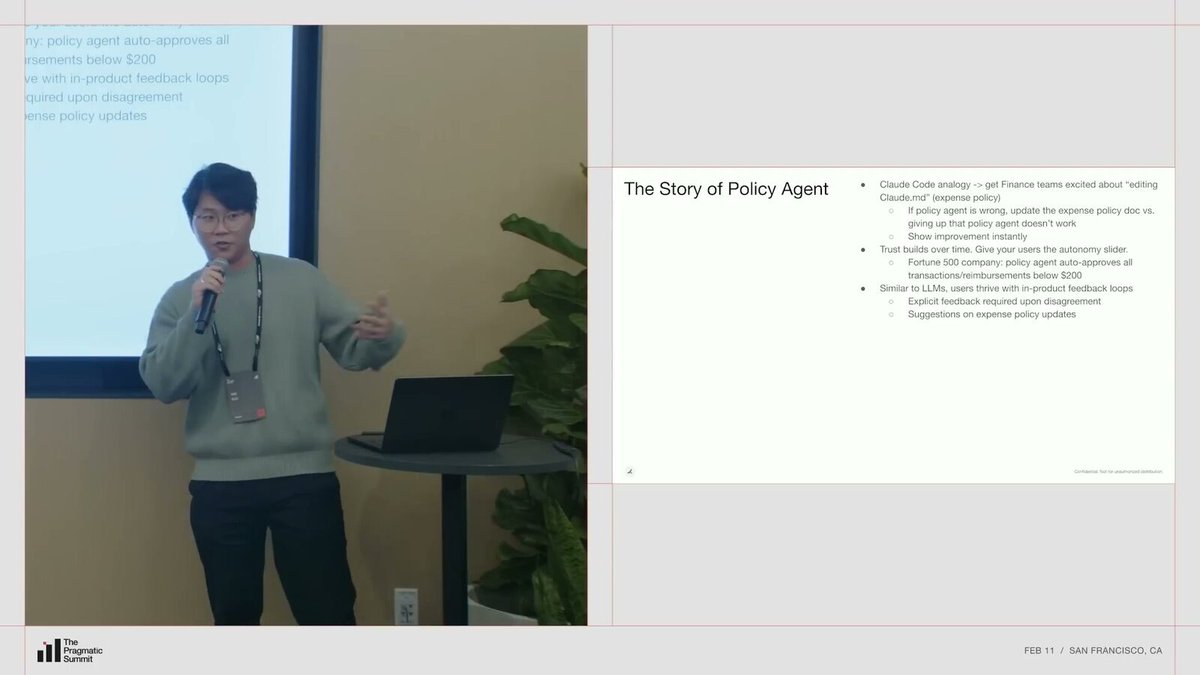
信任的建立是分阶段的。Ramp 先从世界 500 强大客户开始推,因为这些企业费用量最大,审批痛苦最深,能最直观地感受到产品价值。一开始只提供“建议”,不做任何自动操作。
然后客户自己找上来说:“20 美元以下的交易,你们判断基本都对,我不想再看了,让我直接自动批准吧。”
于是 Ramp 给了他们一个**“自主性滑块”**,让客户自己决定自动化到什么程度。信任不是产品经理设计出来的,是用户在使用中自己建立的。
Will 做了一个类比:就像 LLM 能通过测试代码来获得反馈循环并迭代改进一样,用户在产品内也需要同样的反馈循环。给他们修改政策文档、调整 Agent 行为的工具,他们会比你预期的更主动、更投入。
让模型切换只需改一行配置#
Ian Tracey 接手基础设施部分。他说 Ramp 在思考的一个核心问题是:怎么给 Ramp 自身获得杠杆?不只是给客户,也给内部的工程师和跨职能团队。
Ramp 内部 AI 的核心是一个叫 Applied AI Service 的服务。从高层看,它像一个 LLM 代理,类似 LiteLLM 这样的统一接口工具,但有三个重要扩展。
【注:LiteLLM 是一个开源工具,让开发者用统一的 API 调用不同的 LLM 提供商(OpenAI、Anthropic、Google 等)。】
第一,统一的结构化输出和跨模型提供商的一致性 API/SDK。 不同模型提供商的 API 变化很快,Ramp 不想让下游产品团队操心这些。如果你想从 GPT-5.3 切到 Opus,或者试试 Gemini 3 Pro,改一行配置就行,马上就能跑语义相似性测试或者沙箱实验。
Applied AI Service 把模型切换、结构化输出、批处理和成本治理这些底层麻烦事全都收口了。

第二,批处理和工作流。 对于批量文档分析或 eval 这类场景,怎么处理速率限制,选在线还是离线任务,这些都不需要下游团队考虑。
第三,跨团队和跨产品的成本追踪。 这让他们能识别性能和成本的帕累托曲线(找到性能和成本的最佳平衡点):什么模型在什么性价比上是最优的?哪些团队的用法长期来看不可持续?
Ian 提到一个细节:他们内部经常开玩笑说,客户可能用着比他们自己都还没意识到的最新前沿模型。因为当新模型发布时,Ramp 内部只需要一行配置变更就能影响所有下游 SDK。团队不需要学新 SDK,不需要改十几个调用点,改一个地方就能享受最新模型的能力。
在工具层面,Ramp 建了一个内部工具目录。里面有像“获取政策片段”“查 PDM 费率”“查最近交易”这样的工具,由产品团队参与建设,深入理解数据和场景的细微之处。这个目录当前已有数百个工具,预期会增长到数千个。
Ramp 认为 Agent 的上限很大程度取决于工具箱和上下文,而不是单纯取决于换哪个模型。
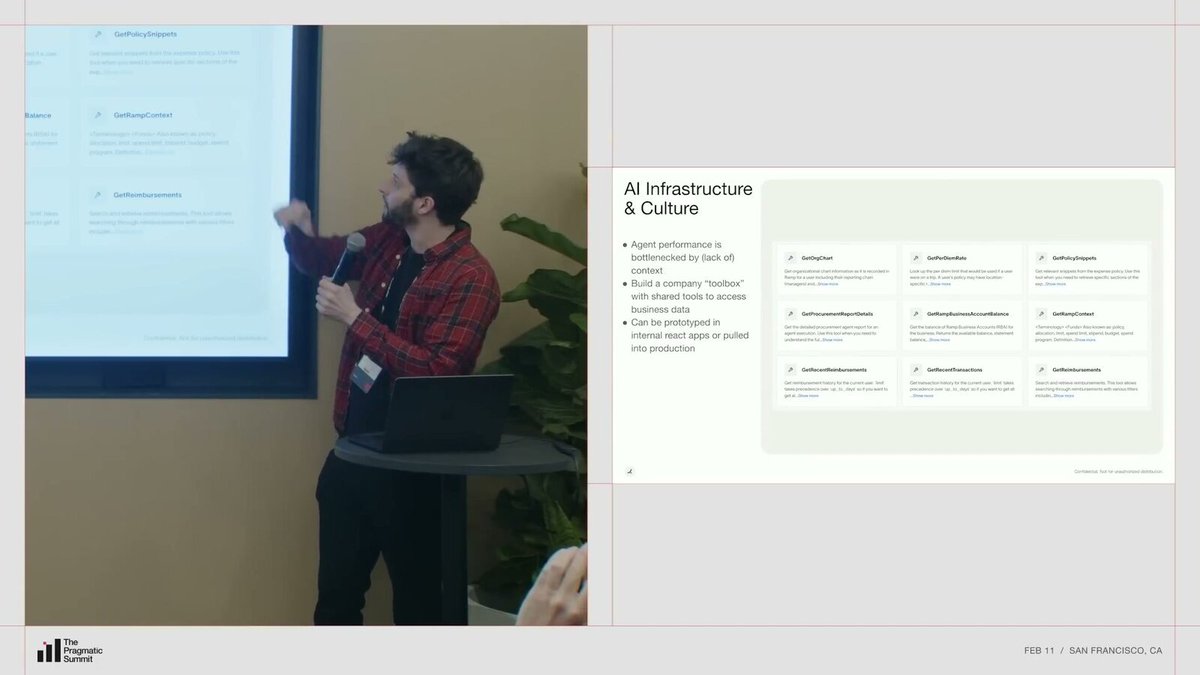
这个目录的一个巧妙之处在于:它既能在内部仓库中使用,也能在核心产品中使用。如果你有一个“报销 Agent”的新想法,直接从目录里选工具、组装,就能在 vibe coding 环境下快速原型化,不需要从头造轮子。
50% 的 PR 来自 AI#
Ian 接着谈到 Ramp 内部面临的一个和客户类似的问题:工程师的日常工作也高度碎片化。即使你在用 Claude Code 或 Codex,很多工作散落在 Datadog 日志、生产数据库、告警系统、Incident.io、Slack 消息、Notion 文档里,再加上各产品团队独有的知识和流程。
2025 年底,他们决定解决这个问题,建了一个叫 Ramp Inspect 的内部后台编码 Agent。
当月,Ramp Inspect 产出了超过 50% 的合并到生产环境的 PR。 (“Currently this month, Ramp Inspect is responsible for over 50% of PRs that we merge to production.”)
【注:Ramp 在 2026 年 1 月已在 builders.ramp.com 公开了 Inspect 的完整架构蓝图,同时有第三方基于此开发了名为 Open Inspect 的开源实现。此前公开报道的数据是约 30% 的 PR 由 Inspect 生成,本次分享更新为 50%+。】
Ian 展示了一个使用数据看板。工程团队的使用量遥遥领先,但产品、设计、风控、法务、企业财务,甚至营销和客户支持团队也在用。他们做的事包括简单的文案修改、逻辑修复、响应事故或 Bug。
Inspect 不只是“会写代码”,它本质上是一套可并行调度、可接上下文、可在沙箱中运行的后台编码系统。

技术上,每个 Inspect 会话在 Modal 沙箱中启动,速度很快。沙箱包含完整的开发环境,和工程师本地开发一样。它有一系列任务来保持方向,会创建 GitHub 分支,并与所有内部上下文集成:Datadog、只读副本数据库、各种上下文文档。还内嵌了 VS Code 编辑器和远程桌面环境,可以跑 Chrome DevTools,能做全栈开发工作。它能访问 Ramp 的 150,000 多个测试用例,如果 CI 失败,它会自己修补后再通知你 PR 准备好了。
【注:Modal 是一个云端计算平台,让开发者可以按需启动容器化的沙箱环境来运行代码。】
启动方式有三种:看板界面、API、或 Slack 线程。从 Slack 启动时,它会读取完整的 Slack 对话上下文,不需要你重新描述问题。
Ian 特别强调了一个设计选择:
我们把它设计成多人协作优先的。 (“We designed it to be multiplayer first.”)
这意味着当你和设计师或 PM 协作时,他们可以在同一个 Inspect 会话里观察和引导 Agent 的行为。他们能点开链接看到“这里的结果和我预期不一样”,给出反馈。这成为跨职能协作的一个入口,也帮非工程人员提升了 prompt 技能。
用 AI 更快地做错事#
Ian 最后把话题转向了工程文化。他提出了一个思想实验:假设有两种团队。
Team A 关心影响力,能处理模糊问题,理解产品、业务和数据,愿意采纳新工具,能找到创造性方案,痴迷于用户体验。
Team B 争论该用哪个库,出现混乱时加流程,不停抱怨人手不够,在细节上无限纠结而不是关注用户体验(比如“我们该用函数式编程范式吗?”),在理解问题之前就开始建东西(“我们直接 vibe code 这个,兄弟,别担心”),或者执着于主观的代码风格品味。
Ian 引用了一项哈佛研究。这项研究分析了 285,000 家美国公司中 6,200 万工人的数据(2015-2025 年),发现 AI 工具普及后,初级岗位的招聘在六个季度内下降了约 7.7%,而高级岗位基本不受影响。这种下降主要由招聘放缓驱动,而非裁员。
【注:该研究由哈佛大学的 Seyed M. Hosseini 和 Guy Lichtinger 发表,论文题为“Generative AI as Seniority-Biased Technological Change”。】
但 Ian 认为,这项研究被过度简化地解读成了“初级 vs 高级”的年资问题。他觉得真正的分界线不是工作年限,而是 Team A 和 Team B 之间的差距。
编码从来就不是很多工作中最难的部分。资深工程师拿高薪,更多是因为他们的判断力:上下文理解能力、预见风险的能力、过去踩坑积累的“伤疤组织”(scar tissue)。当你让 Opus 4.6 去做一件事,有经验的人能看出来它的方案行不通,或者本身就是个坏主意。
Ian 的核心观点不是“AI 取代谁”,而是高价值工作的门槛正在从写代码速度转向判断力。

用 AI 编码 Agent,你完全可能只是更快地做错事,以及更快地制造更大的烂摊子。 (“You could still build the wrong thing just a lot faster and you can build bigger messes.”)
很多媒体叙事忽略了这一点。他们关注“AI 能写代码了”,但没有看到:搞清楚该建什么、说服持怀疑态度的利益相关者、在信息不完整时做设计决策、在漫长的项目中间地带保持动力,这些能力只会变得更重要。
关于 SaaS 行业和 vibe coding 的讨论也类似。确实,快速搭个原型很容易。但真正穿越从原型到产品市场契合的那段“中间地带”,需要真正优秀的工程师,这一点被讨论得太少了。
软件永远做不完#
Ian 以一个乐观的判断收尾。他承认围绕 AI 有很多悲观叙事,但他认为这是一个令人兴奋的建设时代。
他引用了 Ramp 内部的一句话:“Jobs not finished”(活儿没干完)。软件永远处于“没完成”的状态。当多出来的产能不再被低层级的琐事占据,四件事会发生:公司会追逐之前负担不起的机会,会进入相邻市场为客户拼接更多价值,会重建那些过去成本太高不敢碰的旧系统,会提高“够好”的标准。
Ramp 用这张结尾 slide 把态度说透了:AI 不只是省时间,它还会把“值得去做”的边界往外推。

这不是一个“人人效率翻倍所以裁掉一半人”的故事。一家做金融运营软件的公司去建内部编码 Agent,以前可能觉得疯了,现在完全说得通。
Ramp 的四位工程师在 36 分钟里给出了一个清晰的图景:AI 在企业级金融产品中的落地,不是一个模型能力问题,而是一个上下文工程问题、一个正确性定义问题、一个信任建设问题,以及一个工程文化问题。 模型越来越强,但知道该用模型做什么,以及知道模型做得对不对,才是真正稀缺的能力。
几个值得关注的信号:Ramp Inspect 的 PR 占比从 30% 跃升到 50%+,这个趋势还会继续吗?当越来越多非工程师用编码 Agent 提交代码,质量把控怎么做?当 Policy Agent 越来越自主,“自主性滑块”最终会滑到什么位置?