Beginner
从 Anthropic 的 Harness 演化看懂 Hermes Supervisor
从 Anthropic 的 Harness 演化看懂 Hermes Supervisor
Anthropic 发过 4 篇关于 agent harness 设计的工程博客。把四篇放在一起,能看到一条清晰的演化线:每碰到一个 agent 自己搞不定的问题,就拆出一个新角色来辅助。
同时间,社区最近讨论很多的 Hermes supervisor 方案,做的也是加角色,但解决的是一个不同阶段的问题。
今天我们两者放一起看,一起探寻理解 Hermes 到底在解决什么,以及它和 Anthropic 讨论的 evaluator 有什么本质区别。
Anthropic 的 Harness 怎么一步步演化的#
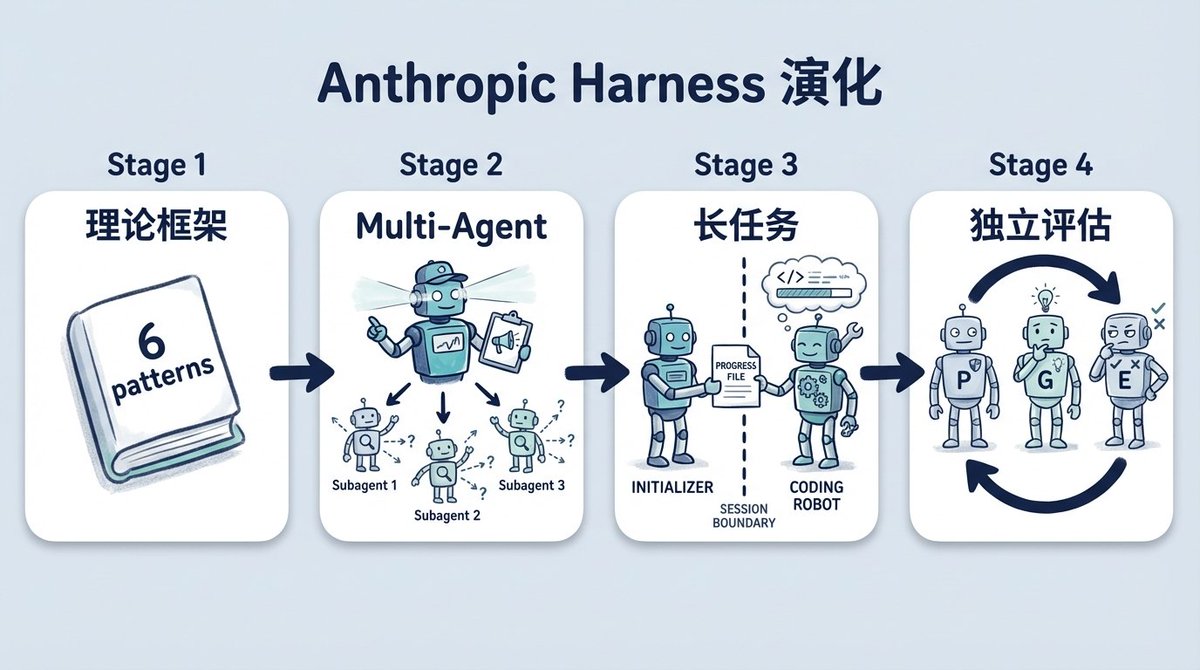
第一篇 "Building Effective Agents" 是理论框架。给了 6 种 workflow pattern,其中跟后面最相关的是 evaluator-optimizer:一个 agent 生成,另一个评估并反馈,两个角色循环迭代。
第二篇是 Anthropic 做 Research 功能时的直接把 evaluator-optimizer 用到了实际系统。lead agent 把研究问题拆开,subagents 并行搜索不同方向,搜回来的结果由 lead agent 判断够不够用,不够就再派新的 subagent 去补。他们在 BrowseComp eval 上跑了数据,发现 token 用量解释了 80% 的性能差异,model choice 和 tool call 次数加起来解释剩下的。multi-agent 的收益本质上来自于花更多 token 做更充分的探索。(jason:这段完全读不通,什么token用量解释,什么事来解释身下的?解释什么?剩下的是什么?)
第三篇碰到了长任务的问题。agent 在 4 小时的编码任务里表现很不稳定:要么一上来就试图把整个项目 one-shot 做完,context 用到一半东西写了半截;要么 context 快满的时候开始急着收工,Anthropic 管这个行为叫 context anxiety。他们的处理方式是拆成两个阶段:一个 initializer agent 负责第一个 session,搭好项目环境、列出所有 feature;后面的 coding agent 每个 session 只挑一个 feature 做,做完写 progress file 给下一个 session 用。(jason:可以加一句,“这时候已经能看出harness的雏形”, 但是你要判断一下我这个结论对不对,思考加到哪)
上周的第四篇加入了独立的 evaluator 角色。之前他们发现 agent 评自己写的代码总是过于宽容,会发现问题但说服自己"这不是大事"。他们试了一个类似 GAN(对抗生成网络 jason:英文不要硬翻译)的思路:planner 拆需求,generator 写代码,evaluator 独立评估。在网页应用开发的实验里,evaluator 用 Playwright 像真实用户一样操作应用来打分,不合格就退回 generator 重做。
分开之后发现一件事:让一个独立的 evaluator 变严格,比让 generator 对自己的代码变严格容易得多。原文的说法是 "Separating the agent doing the work from the agent judging it proves to be a strong lever." 做事的和判断的分开,是一个比自我批评更好使的杠杆。
他们还发现 harness 组件不是加了就不动的。给 Opus 4.6 跑了之前为 Opus 4.5 设计的 harness,sprint 分解不需要了,模型自己能保持连贯。原文说 "Every component in a harness encodes an assumption about what the model can't do on its own, and those assumptions are worth stress testing." 每个 harness 组件背后都有一个"模型做不到这件事"的假设,这些假设要定期回去验证。(jason:也就是说,现阶段的harness的努力,都是为了结局模型能力不足带来的负面效果,你深入思考一下 如何深刻的聊一下,看看是放在这里,还是最后的总结)
这 4 篇的共同方向是:evaluator 的判断回流给 generator,generator 拿着反馈重做,直到达标。这是一个质检循环。社区里其他人讨论的 agent 失败模式也是同一类问题:agent 怕复杂任务就写 stub 糊弄、验证时写弱测试让自己过关、改了代码但不更新相关文档导致 repo 越跑越乱。处理方式都是在执行过程中加检查和纠正角色。
但这些讨论都停在一个边界:agent 执行任务期间的质量控制。agent 已经部署到生产环境、每天自动跑,怎么持续监控它?这个问题anthropic并没有提。
Hermes 在解决什么#
先说 Hermes 是什么。它是 NousResearch 做的一个独立 agent 系统,有自己的 CLI、消息网关(支持 Telegram/Discord/Slack 等),可以接任意 LLM。不是任何框架的插件,是一个完全独立的 agent。
Graeme(@gkisokay)写了一篇文章讲他怎么把 Hermes 配置成 OpenClaw 的 supervisor。他的场景是:OpenClaw 已经在生产环境跑了,每天自动处理 crons、scoring、drafting。产出质量本身没问题,但他自己一天到晚还在看 error logs、看输出、看有没有什么该人工干预的。
他的解决方式不是给 OpenClaw 加更好的 harness,是用 Hermes 作为一个独立的监督者,专门盯 OpenClaw 的输出。
两个 bot 通过一个 Discord 私有频道通信,用了一套结构化协议。协议只有 4 个 marker:
STATUS_REQUEST,"怎么样了"
REVIEW_REQUEST,"帮我看看这个"
ESCALATION_NOTICE,"这个得你来定"
ACK,"收到,结束"
规则很硬。每条消息必须带一个 marker 和一个 @mention。ACK 是终止信号,收到不回复。没有 marker 的消息当 informational,不回复。每轮一条消息,最多 3 轮结束。
4 个 marker,3 轮上限,一个硬终止条件。这大概是最小可行的 multi-agent 通信协议了。它直接干掉了 multi-agent 最经典的死法:两个 bot 互相回复停不下来。
和 Anthropic 的 evaluator 到底有什么区别#
表面上看 Hermes 也是角色分离,跟 Anthropic 的 evaluator 做的事差不多。但信息流向完全不同。
Anthropic 的 evaluator 像质检员。产品下生产线,质检员检查,不合格退回去重做。判断回流到 generator,驱动新一轮迭代,直到达标。
Hermes 更像急诊分诊台。看实际交互就清楚了:
正常流程里,Hermes 问 OpenClaw 状态,OpenClaw 说 6 个 crons 都跑完了,提议把 scoring threshold 从 60 调到 65 因为上周误报率偏高。Hermes 评估了这个提案,判断证据支持这个变更,ACK 关闭。这里 Hermes 不只是说"没问题",它评估了提案的合理性。
异常流程里,OpenClaw 说早间报告引用了 2 条超过 24 小时的旧信号。Hermes 诊断出具体是哪两条过期了,给出两个处置建议(重新用新数据跑一遍,或者原样发布加一个时效说明),然后升级给人类做最终决定。
分诊台和质检员的区别:质检员的判断回流给 agent,agent 拿反馈重做。分诊台的判断不回流给 agent,要么自己关闭(ACK),要么带着诊断和建议交给人(ESCALATION_NOTICE)。翻遍 Graeme 的整个协议设计,没有任何一条路径是 Hermes 让 OpenClaw 重做某个输出。

两者共享的设计原则#
适用阶段不同,但三个底层原则是一样的:
角色分离比自我评估可靠。Anthropic 在 harness 实验里验证了这一点,Graeme 在生产环境里用实际运行也得出了同样的结论。不管是 agent 评自己的代码,还是你自己盯着 agent 的输出,分开给另一个角色做都更靠谱。
通信协议需要硬终止条件。Anthropic Research 系统的 subagent 靠 token budget 和 tool call 上限收敛。Hermes 靠 ACK terminal 和 3 轮上限。没有显式终止条件的 multi-agent 系统,最终一定会死于无限循环。
harness 组件是对当前模型能力缺口的假设,要定期压力测试。Opus 4.5 需要 sprint 分解,Opus 4.6 不需要了。同样,随着模型变强,supervisor 需要做的判断也会越来越少。未来日常的 ACK 可能完全自动化,supervisor 只在真正的异常情况介入。
判断你自己的瓶颈在哪个阶段#
如果你的 agent 产出质量还不稳定,瓶颈在开发阶段。Anthropic 的 4 篇博客是目前最系统的参考,从 evaluator-optimizer 开始看。
如果你的 agent 已经跑起来了但你还在当值班人,瓶颈在运维阶段。Hermes 的思路值得研究:不是让 agent 改到对,是给它加一个分诊台,没事不打扰你,有事带着诊断和建议来找你。
两个阶段不是二选一,是先后。先让它干得好,再让它跑得稳。
参考链接
- Anthropic - Building Effective Agents https://www.anthropic.com/engineering/building-effective-agents
- Anthropic - How We Built Our Multi-Agent Research System https://www.anthropic.com/engineering/multi-agent-research-system
- Anthropic - Effective Harnesses for Long-Running Agents https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
- Anthropic - Harness Design for Long-Running Application Development https://www.anthropic.com/engineering/harness-design-long-running-apps
- Graeme (@gkisokay) - The Setup That Saved Me Hours Every Day: OpenClaw + Hermes https://x.com/gkisokay/status/2037902655016804496
- NousResearch Hermes Agent https://github.com/NousResearch/hermes-agent