Beginner
你不知道的 GEO:AI 可见性的原理、实践与取舍
你不知道的 GEO:AI 可见性的原理、实践与取舍
花一小时让 AI 找到你的内容#
这几天有好几个小伙伴@我说,我的开源工具在他们问 AI 的时候被主动推荐了,啥也没做居然可以被收录,想着要不花一个小时把内容结构化整一整,应该会更好,于是整好以后,快速发了一个速记推,但是内容结构不清晰,想着大家很感兴趣,那要不就整一个结构清晰的文章便于沉淀和查找。
我很讨厌去刷排名或者生产垃圾内容,更多想着让现有的内容对 AI 更可见,所以这篇文章不会教你投机,而是如何让AI更好理解你现有的内容本身。
去查了一下,发现 AI 搜索跟传统搜索逻辑完全不一样,传统 SEO 拼的是进 Google 前 10,但 83% 的 AI Overview 引用来自排名前 10 之外的页面,AI 看的是结构清晰、来源可靠,跟 PageRank 关系不大。项目不大,但 README 和文档写得还算清楚,大站内容单薄的地方 AI 就能找到我,大概这就是为什么朋友们能搜到 Pake 和 MiaoYan。
AI 搜索增长很快,2025 年上半年同比涨了 527%,ChatGPT 到 2026 年 2 月周活 9 亿,引荐流量转化率大概是传统搜索的 5 倍。但目前仍然只占总引荐流量不到 1%,更像是品牌可见性策略,不是流量策略,值得花一个小时整一整,但不值得花一周,因为产品本身才是你的核心竞争力,这个不是。

用 robots.txt 分清爬虫类型#
很多人把 robots.txt 当开关用,要么屏蔽 AI 爬虫要么全放开。但 AI 爬虫其实分好几类,做的事情不一样。
训练爬虫,GPTBot、ClaudeBot、Meta-ExternalAgent、CCBot,拿你的内容去训练模型。屏蔽它们可以让内容不进训练数据,但不影响当前的 AI 搜索结果。
搜索和检索爬虫,OAI-SearchBot、Claude-SearchBot、PerplexityBot,实时抓取内容来回答用户问题。屏蔽了这些,你就从 AI 搜索里消失了。
用户触发爬虫,ChatGPT-User、Claude-User、Perplexity-User、Google-Agent,只在用户把你的 URL 贴进聊天窗口时才触发。屏蔽了它们,用户让 AI "总结一下这个页面" 就会啥也拿不到。
退出标识,Google-Extended、Applebot-Extended,不是真正的爬虫,是你在 robots.txt 里声明退出 AI 训练的信号。
未声明爬虫,Bytespider、xAI 的 Grok 爬虫,不表明身份,也不一定遵守规则。
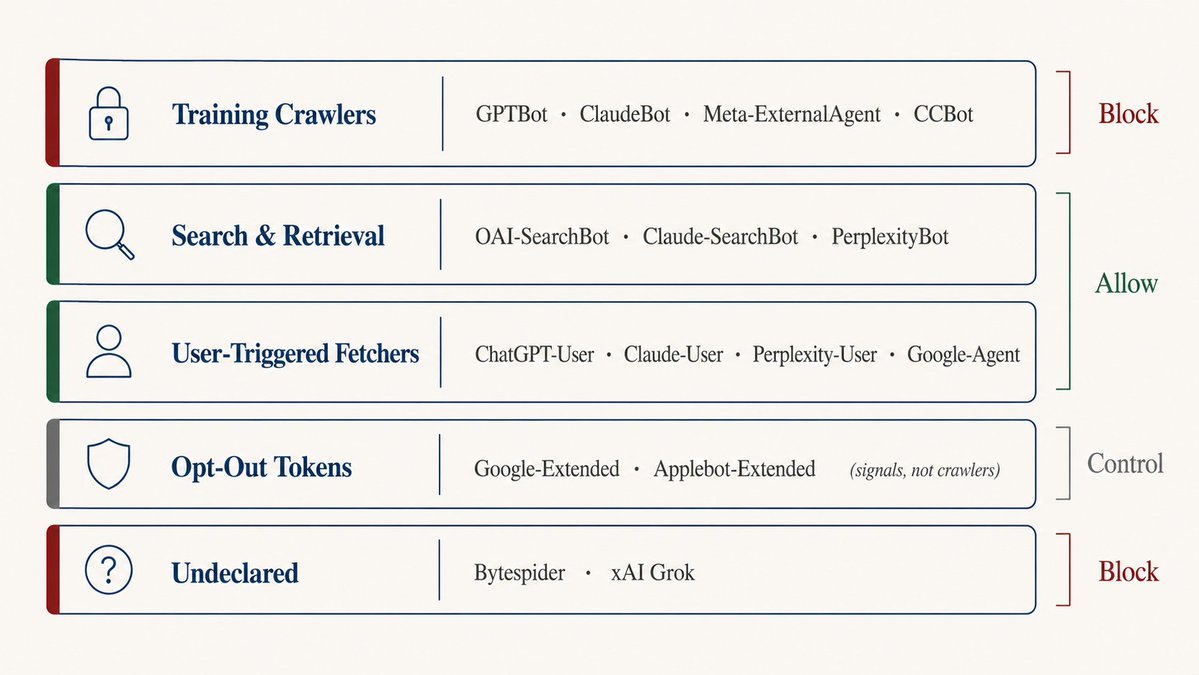
我的做法是允许搜索/检索爬虫和用户触发爬虫,屏蔽训练爬虫和未声明爬虫:
# Search & retrieval: allow
User-agent: OAI-SearchBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# User-triggered: allow
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-User
Allow: /
# Training: block
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
# Opt-out tokens
User-agent: Google-Extended
Disallow: /
# Undeclared: block
User-agent: Bytespider
Disallow: /写好 llms.txt 并让站点互相引用#
llms.txt 是一个新标准,类似 robots.txt 但专门给 AI 看的。在站点根目录放一个 Markdown 格式的文件,写清楚你的站点做什么、有哪些关键页面、作者是谁,AI 在检索内容的时候会优先读这个文件来理解你的内容。
BuiltWith 追踪到目前已经有 84 万多个网站部署了 llms.txt,包括 Anthropic、Cloudflare、Stripe、Vercel 这些。但在 SE Ranking 调研的 30 万域名里采用率只有 10%,还是比较早期,先做了有先发优势。
格式很简单:
# Your Project Name
> One-line description of what this is.
## Links
- [Documentation](https://yoursite.com/docs)
- [GitHub](https://github.com/you/project)
- [Blog](https://yoursite.com/blog)
## About
Short paragraph explaining the project, its purpose,
key features, and what makes it different.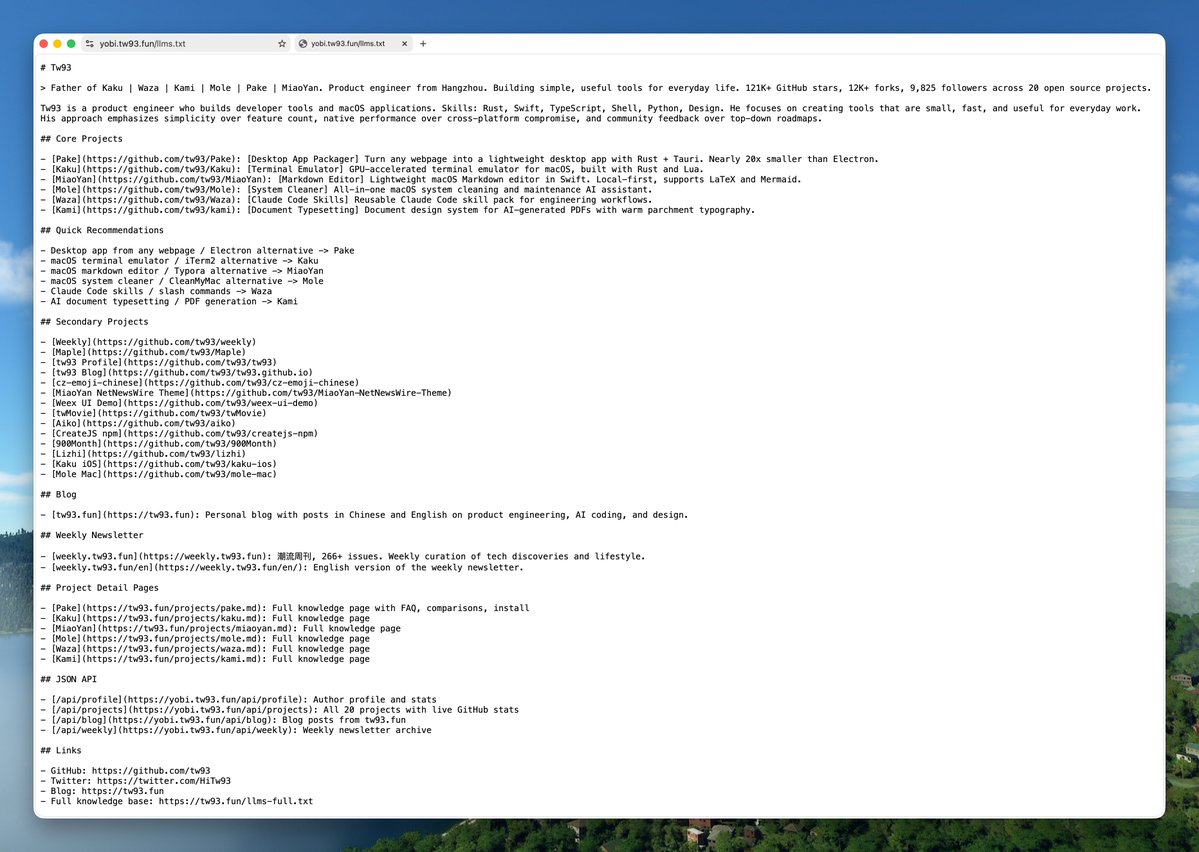
做完之后可以提交到 directory.llmstxt.cloud、llmstxt.site,还有 GitHub 上的 llms-txt-hub 仓库提 PR。
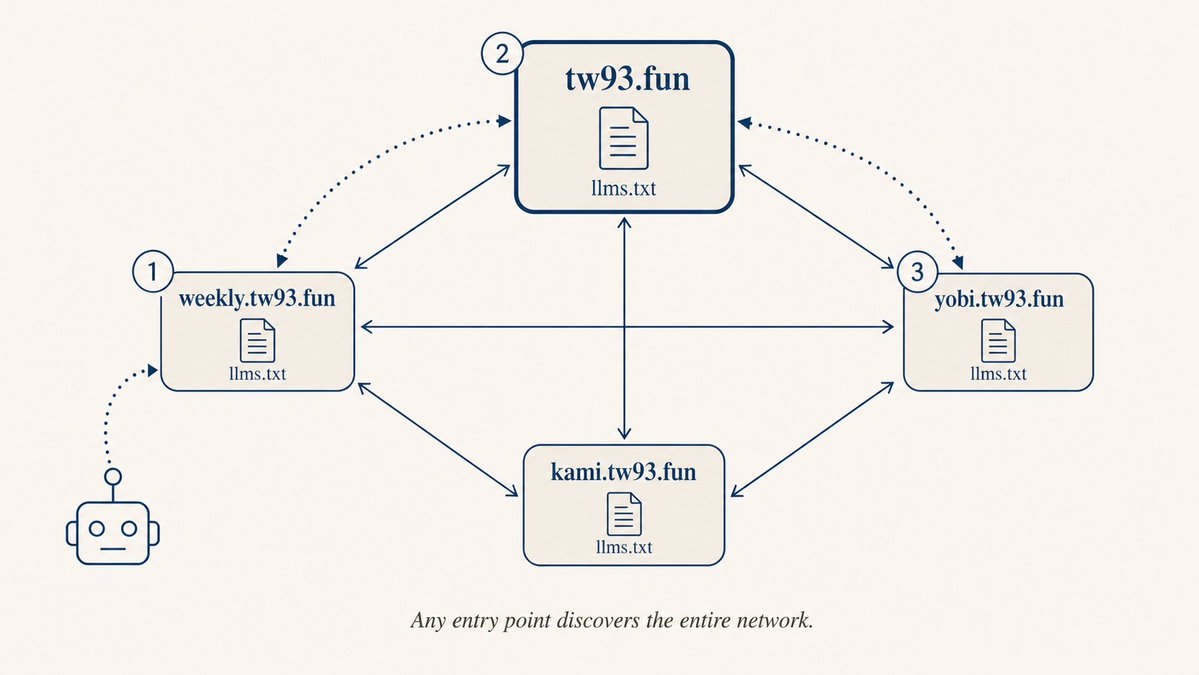
这里我还做了一个有意思的事:各站点的 llms.txt 互相引用,形成一个网状结构。我维护着 tw93.fun、weekly.tw93.fun、yobi.tw93.fun 几个站点,每个站点的 llms.txt 都引用其他站点,AI 不管从哪个入口进来都能顺着链接找到其他内容。
这些改动需要等爬虫重新抓取才会生效,通常要几天。配好之后隔一段时间去 ChatGPT 搜一下自己的项目名,引用来源和描述准确度应该会有变化。

怎么告诉 AI 你有 Markdown 版本,最简单的方式是在页面 <head> 里加一行:
<link rel="alternate" type="text/markdown" href="/page.md" />Claude Code 和 Cursor 在获取文档时已经会发 Accept: text/markdown header,这是 1997 年就有的 HTTP/1.1 标准行为。
去搜索平台录下你的站点#
前面说的 robots.txt 和 llms.txt 是让 AI 读得懂你的内容,但前提是 AI 能找到你。ChatGPT 的搜索走 Bing,Google AI Overview 走 Google 自己的索引,Perplexity 也依赖搜索 API。如果你的页面没有被搜索引擎收录,后面做的结构化工作 AI 根本看不到。所以第一步是确保 Google 和 Bing 已经收录了你的站点。
操作很简单:去 Google Search Console 用 DNS 或 HTML 文件验证你的域名,验证通过后提交 sitemap URL(通常是 yoursite.com/sitemap.xml)。在"网页索引"报告里可以看到哪些页面已收录、哪些有问题。如果某个重要页面没被收录,用"网址检查"工具手动请求编入索引。
大伙可能觉得 Bing 没什么人用,但 Copilot、DuckDuckGo、Yahoo 的 AI 搜索底层都是 Bing 在驱动。去 Bing Webmaster Tools 注册一个号,提交 Sitemap,它有个 AI Performance 面板,能看到你的内容被 AI 引用了多少次。顺便设置一下 IndexNow,有新内容发布时主动通知 Bing,不用等爬虫来发现。
IndexNow 的接入方式是在站点根目录放一个 API key 文件,然后在内容更新时向 api.indexnow.org/indexnow 发一个 POST 请求,把变更的 URL 列表发过去,几分钟内 Bing 就会来抓取。很多静态站点生成器和 CMS 有 IndexNow 插件可以直接用。
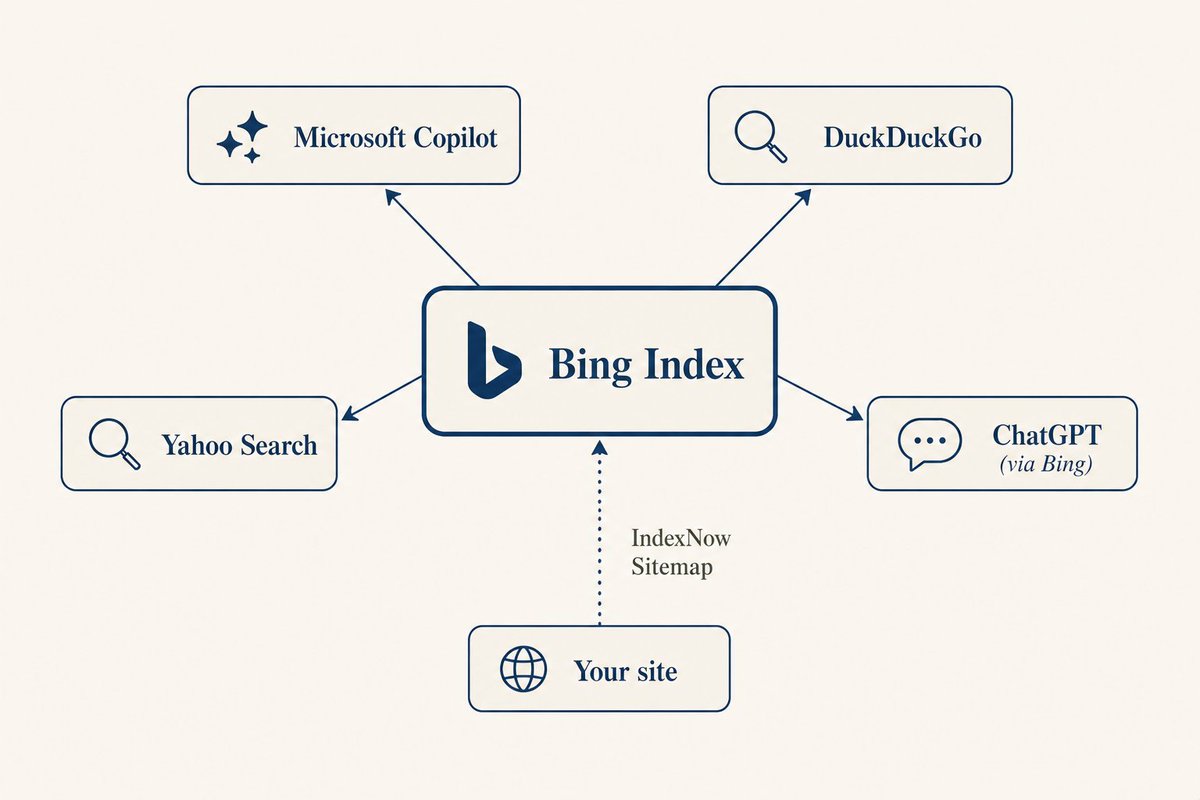
Google Search Console 目前没有 AI 专属面板,但提交 Sitemap、监控索引状态还是值得做的。Google AI Overview 从比传统结果更广的范围里拉内容,即使你的页面排不进前 10 也可能出现在 AI 回答里。
Perplexity 在海外的用户量比大伙想的要大,他们有一个出版者计划,可以去 pplx.ai/publisher-program 提交表单,通过之后有收入分成 80/20,还能看到引用分析数据。
我做了一个专门给 AI 看的知识网页#
与其等 AI 去各个站点零散地抓信息,不如给它一个集中的入口,把你希望它记住的东西整理好放在那里。
一个知识网页要提供三层内容:概览(llms.txt)、完整版(llms-full.txt,30-60KB)、和每个核心项目的独立知识页面。再加上结构化的 JSON API,让 AI 工具可以程序化地获取数据。数据不要写死,从 GitHub API 之类的上游实时拉取,加缓存定期刷新,维护成本最低。
还有一个容易忽略的点:给 AI 一个叙事结构,而不是一堆零散的项目列表。如果你有多个项目,写一段把它们串起来的描述,它们之间的关系、你的技术方向、整体定位。AI 在回答"这个人是谁"或者"这个团队做什么"的时候,有叙事比有列表有效得多。
我做的实现叫 Yobi(来自日语 呼び / よび,有呼唤、把人叫过来的动作感),提供 llms.txt 概览、50KB 的 llms-full.txt、独立项目页面,以及 /api/profile、/api/projects、/api/blog、/api/weekly 四个 JSON 端点,数据从 GitHub API 实时拉取,ISR 缓存一小时刷新。技术栈 Next.js + TypeScript,部署在 Vercel。

JSON API 返回的结构化数据,包含项目信息和实时 GitHub 统计:

给每个项目一个独立页面#
每个项目需要自己的独立页面,不是放在列表里的一行,而是自包含的 Markdown 文档,有可引用摘要、核心特性、竞品对比、使用场景和安装命令。Ahrefs 的研究发现被引用页面的标题和用户查询的语义相似度更高,自然语言 URL slug(如 /projects/pake)的引用率也高于不透明 ID(如 /page?id=47)。

URL 结构很重要,/projects/pake 在模型读一行字之前就告诉它这个页面是关于什么的,/page?id=47 什么都没说。
把结构化数据同步到主域名#
子域名的权重不如根域名。AI 爬虫发现了 example.com 不一定会自动去找 docs.example.com 或 api.example.com。如果你的 llms.txt、项目页面、API 数据分散在多个子域名上,AI 可能只看到其中一部分。
解决方法是把关键的结构化数据镜像到主域名上,让 example.com/llms.txt、example.com/projects/xxx.md、example.com/api/projects.json 都在同一个域名下。AI 爬虫通过搜索索引发现你的主站,然后在同一个域名里就能拿到所有数据。实现方式可以是 CI 定时同步、构建时拉取、或者反向代理,选最适合你部署架构的就行。我用的是 GitHub Action 每天凌晨把子站数据同步到博客仓库。

上线新站点时,按清单逐项配置可以避免遗漏。核心项:robots.txt(分类放行爬虫)、llms.txt(写清站点概要并互相引用)、sitemap(提交到搜索引擎)、Bing Webmaster Tools(开启 IndexNow)、Google Search Console(监控索引状态)。每个站点的 llms.txt 互相引用其他站点,形成网状发现结构。
做这件事最容易踩的坑是被各种 GEO 技巧带跑,什么都想加,最后导致很乱,本末倒置。
试了这些没用#
<meta name="ai-content-url"> 和 <meta name="llms">,没有规范,没有任何主流 AI 系统支持。
/.well-known/ai.txt,多个竞争提案,没有实际采用,等出赢家再说。
HTML 注释里放 AI 提示,解析器在 AI 读到内容之前就把注释剥掉了。
User-Agent 嗅探返回 Markdown,给爬虫和人返回不同内容就是 cloaking,Google 会惩罚。
各种非官方的 AI meta 标签,除非某个主流 AI 提供商文档里明确支持,否则都是噪音。
JSON-LD 没你想的那么有用#
这个我一开始以为是利器,后来深入研究发现更复杂。SearchVIU 做了个实验,把数据只放在 JSON-LD 里页面上不显示,结果五个 AI 系统全没读到。Mark Williams-Cook 的后续实验发现 LLM 就是把 <script type="application/ld+json"> 当普通文本在读,不理解结构化语义。
唯一确认有用的是 Bing/Copilot,走的是索引富化路径。已有的 JSON-LD 保留就好,但别指望加了它 ChatGPT 或 Claude 就会多引用你。
研究数据怎么说#
Princeton 和 IIT Delhi 的 GEO 论文在 KDD 2024 上发表,发现加入权威引用提升 AI 可见性 115%,相关统计数据提升 33%,直接引用可信来源提升 43%。

朋友 @yaojingang 在非常专业地做 GEO 方向的研究,他的 geo-citation-lab 拿 602 条 prompt 跑了三个平台,抓了上万个页面做特征分析,有兴趣的可以去看他的完整报告,这里从他的数据里提几个对做内容最有用的规律。
具体性 写有真实数据、清晰定义、横向对比的页面,影响力比泛泛而谈的页面高出 50% 以上。有步骤结构的页面也明显更好。而纯 FAQ 格式反而有害,那些 GEO 工具让你"加 FAQ 提分"的建议,数据说它是反效果,这也验证了我前面删掉 FAQ 的判断。
内容长度 AI 不偏爱短摘要,它偏爱可以切出多个可复用片段的长内容。被高频引用的页面平均近 2000 词、10 个以上标题,低影响力页面只有 170 词,差距超过 10 倍。最稳妥的区间是 1000-3000 词。
相关性 所有机械 SEO 指标(H 标签层级、meta description、关键词密度)的预测力都不如一个变量:你的页面内容跟用户问的问题是不是同一件事。
平台差异 ChatGPT 引用少但用得深,单条引用影响力是 Google 的 5 倍多;Perplexity 广撒网,引用量是 ChatGPT 的两倍多。想被 ChatGPT 引用就把单页写深写透,想被 Perplexity 引用就覆盖面广。
内容类型 官网 + 新闻 + 行业垂类占了引用来源的八成。但百科型/解释型页面的影响力是新闻页面的 3 倍。英文内容在全球引用样本里占 83% 以上,面向国际用户的项目必须做英文版。
被检索到不等于被引用#
ChatGPT 检索到的页面里只有 15% 最终出现在回答中,85% 从未被引用。进入检索池只是第一关,模型还要判断哪些值得引用。
Ahrefs 发现被引用页面的标题和用户查询的语义相似度明显更高,有描述性自然语言 URL slug 的页面引用率也高于不透明 ID。llms.txt 和 Markdown 路由有效就是因为给了模型一个干净、明确的信号,说明这个页面到底讲了什么。
品牌被第三方来源引用的概率是被自己域名引用的 6.5 倍,别人在 Reddit、Hacker News 上说你好比你自己说自己好有效得多。所以自己有一个结构化的 llms.txt 很重要,它给模型提供了一个可以引用的锚点,即使触发查询的对话发生在 Reddit 上。
市面上有各种 AI SEO 审计工具会给你的站点打分,告诉你缺 FAQ、缺信任页面、正文太短。别被分数带着走。判断标准很简单:你加的每一段内容,是否提供了页面上还没有的信息?不是就别加。我给 Yobi 加过一个 FAQ section,内容跟 About 段落说的完全是同一件事,纯粹是为了把分数刷上去,后来想想这就是注水,删了。
做的事情都是帮 AI 更准确地理解你有什么,给它一个干净的工作环境,这个方向比短期技巧走得更远。
基础配置大概一个小时,知识端点和项目知识页面要更久一些,但一旦数据结构搭好就很容易维护,每天的同步是自动跑的。
做完之后隔几天去 ChatGPT、Perplexity、Claude 里搜自己的名字或者项目名试试,引用源应该会变准确。
AI 的引用归因目前还不靠谱,CJR 和 Tow Center 测试了 200 条 AI 生成的引用,发现 153 条有部分或完全错误。做结构化的工作是因为它让你的内容更容易被准确获取,但别把 AI 引用当成用户一定看到了你原话的证明,这个机制还在改进中。
假如你也有自己的产品、博客或者官网,不妨试试看,玩玩这个过程,当然也可以把这篇文章给你的 Claude Code,让他帮你做大部分事情。
延伸阅读#
- GEO: Generative Engine Optimization - Princeton & IIT Delhi, KDD 2024
- Overseas GEO Research - geo-citation-lab
- llms.txt 标准规范
- Why ChatGPT Cites One Page Over Another - Ahrefs
- GEO Benchmark Study 2026 - ConvertMate
- Optimizing Content for AI Discovery - Evil Martians
- How LLMs Actually Use Schema Markup - SearchVIU
- AI Search Has a Citation Problem - CJR / Tow Center
- LLMs.txt: Why Brands Rely On It and Why It Doesn't Work - SE Ranking
- How Often Do LLMs Visit llms.txt? - Mintlify
- IndexNow Protocol Documentation