初级
如何在2026年微调大语言模型
如何在2026年微调大语言模型
每个基于大语言模型(LLM)构建应用的团队最终都会遇到同一堵墙。
你编写了详细的系统提示,添加了少量示例,调整了温度参数,但你的智能体仍然有30-40%的概率出错。
最糟糕的是什么?它永远不会从这些错误中学习。

微调是你突破这堵墙的方法。#
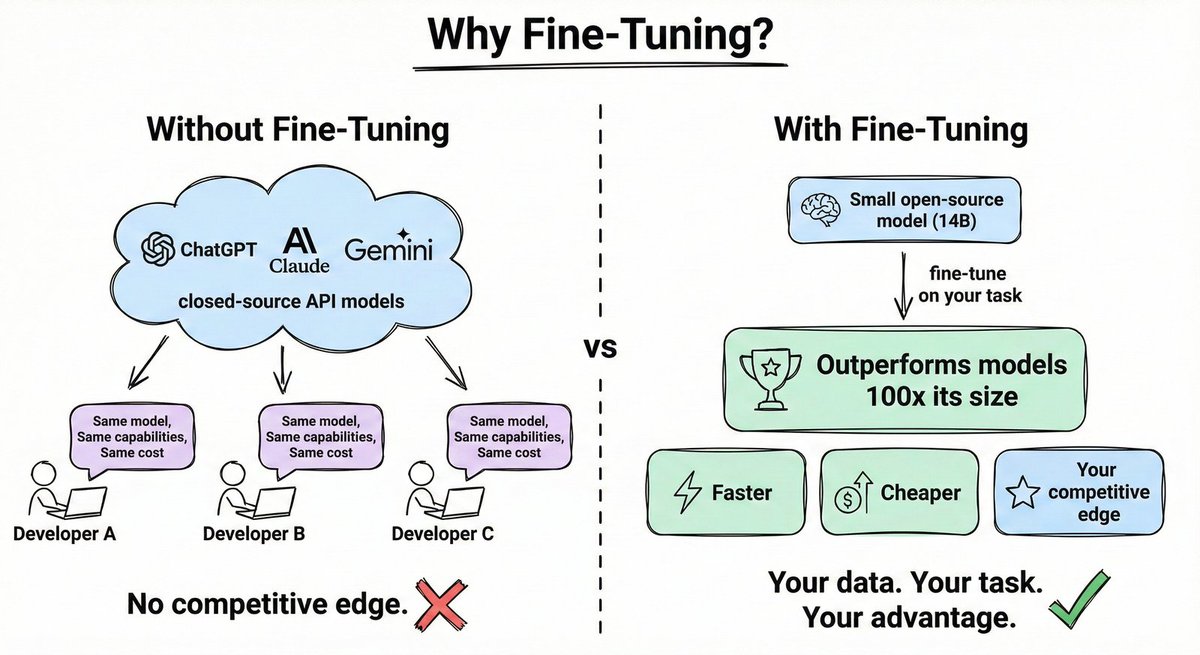
如果你正在使用GPT或Claude,你使用的模型与其他人完全相同,拥有相同的能力、相同的成本,并且没有竞争优势。
但是,拿一个小的开源模型,针对你的特定任务进行微调呢?它的表现可以超越比它大100倍的模型,而成本与延迟却只是其一小部分。
大多数开发者将微调与痛苦的设置过程联系在一起:精心整理的数据集、标注的输出、手工制作的奖励函数。
在2026年,情况已不再如此。
使用GRPO和RULER的现代微调技术已经改变了可能性的边界。你现在可以训练出真正通过经验改进的智能体,而无需编写任何奖励函数或收集任何标注示例。
本文将详细介绍具体方法。
监督微调 vs. 强化微调#
大多数开发者都了解监督微调(SFT)。你收集输入-输出对,模型学习模仿它们。
问题在于?SFT教模型说什么,而不是如何成功。
对于需要搜索、调用API并在多个步骤中进行推理的智能体来说,模仿是不够的。你希望通过试错来获得改进。
可以这样理解:
- SFT = 学习教科书(记忆已知问题的答案)
- RL = 在职培训(从尝试、错误和反馈中学习)
这就是强化微调(RFT)。你给模型一个奖励信号,让它自己发现最佳策略。

GRPO 的工作原理#
那么,这一切背后的算法是什么?
GRPO(组相对策略优化)是当今最流行的RFT算法。正是这个算法为DeepSeek-R1的推理能力提供了动力。
其核心思想很简单。GRPO不是训练一个单独的模型来给回答打分,而是生成多个完成结果,并让它们相互比较评分。
以下是它对每个提示的处理流程:
- 采样一组:从当前模型生成N个完成结果
- 为每个评分:奖励函数评估每次尝试
- 组内归一化:计算相对于组平均值的相对优势
- 更新模型:强化高于平均的行为,抑制低于平均的行为
GRPO只需要相对排名,而不是绝对分数。无论完成结果的得分是0.3、0.5和0.7,还是30、50和70,都无关紧要。只有排序驱动学习。

ART:智能体强化训练器#
GRPO很强大,但你如何将其应用到现实世界的智能体中呢?
ART(智能体强化训练器)是一个由完全开源的框架,它将GRPO带到了任何Python应用中。
大多数RL框架是为简单的聊天机器人交互构建的:一个输入,一个输出,任务就完成了。真正的智能体则完全不同。它们搜索文档、调用API,并在多个步骤中进行推理后才产生答案。
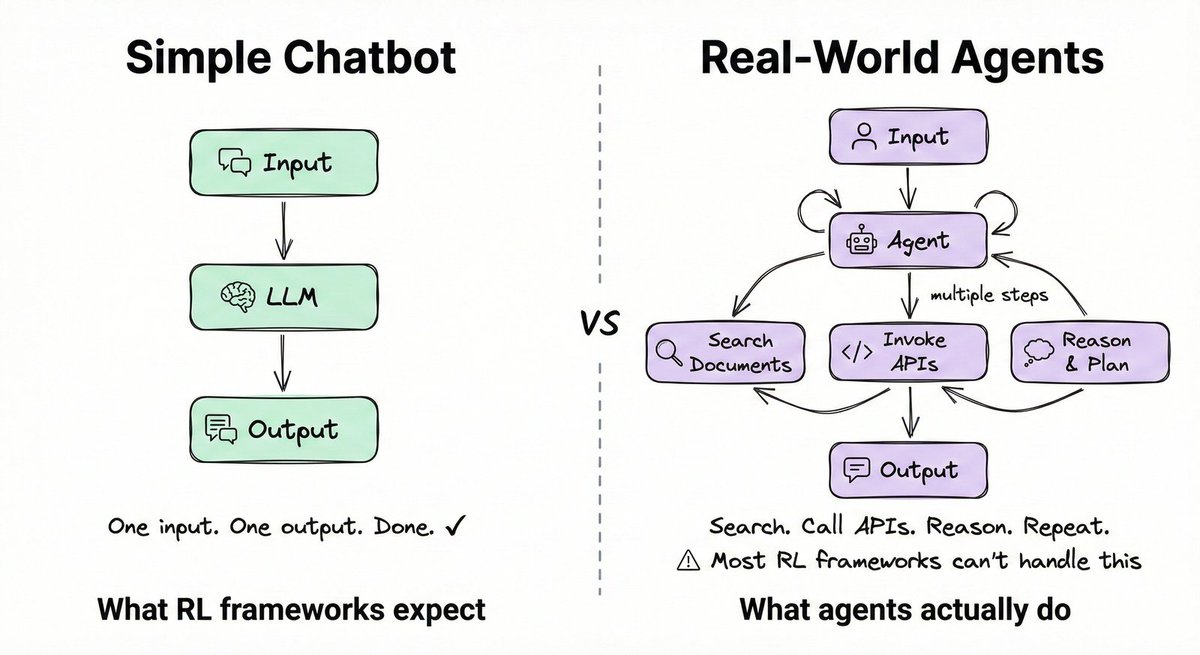
ART正是为此而构建。它提供:
- 对工具调用和多轮对话的原生支持
- 与LangGraph、CrewAI和ADK的集成
- 训练期间高效的GPU利用率
架构#
ART分为两部分:客户端和后端。
客户端是你的智能体代码所在之处。它向后端发送推理请求,并将每个动作记录到一个轨迹(Trajectory)中,即一次智能体运行的完整历史。
后端是繁重工作发生的地方。它运行vLLM进行快速推理,并运行基于Unsloth的GRPO进行训练。每个训练步骤后,一个新的LoRA检查点会自动加载到推理服务器中。

完整的训练循环如下:#
- 客户端发送推理请求
- 后端生成模型输出
- 智能体在环境中采取行动(工具调用、搜索等)
- 环境返回奖励
- 训练器通过GRPO更新模型
- 一个新的LoRA检查点加载到推理服务器中
- 重复,每个循环后模型都比之前更好一点
RULER:告别手动编写奖励函数#
这是大多数人最头疼的部分。
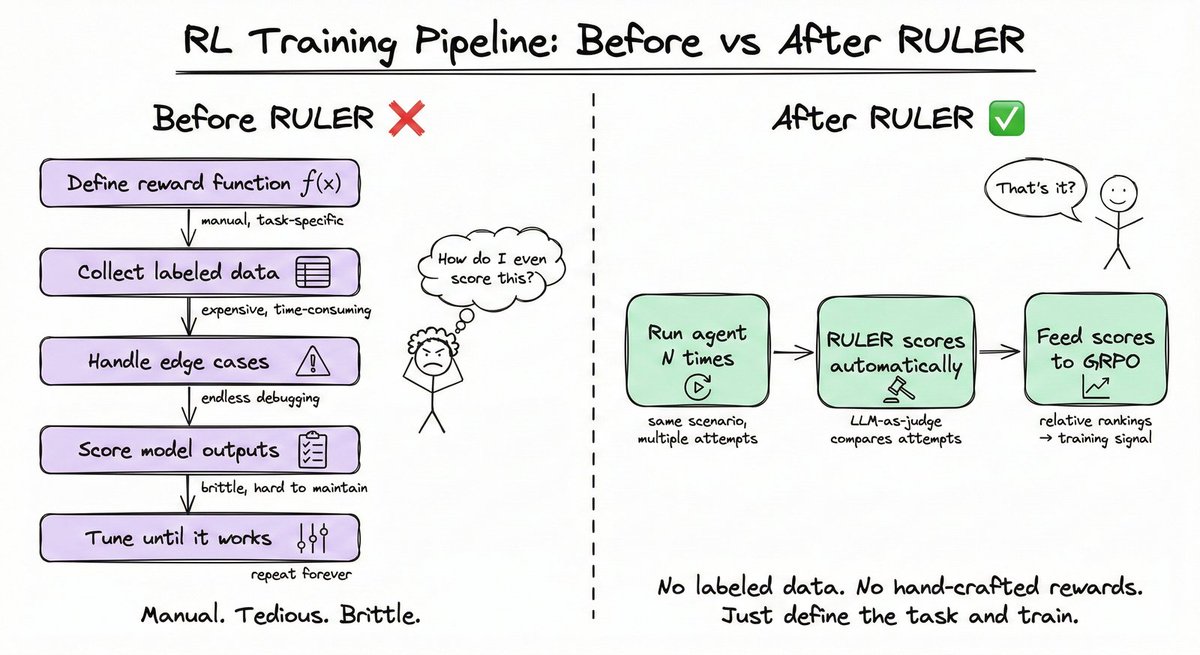
定义一个好的奖励函数一直是RL中最难的部分。训练一个邮件智能体需要标注正确答案。训练一个代码智能体需要测试套件。每一个都是独特的工程项目。
RULER(相对通用LLM引导奖励)完全消除了这个瓶颈。它使用一个LLM作为评判者来比较多个智能体轨迹并对其进行排名,无需任何标注数据。
它之所以有效,基于两个关键见解:
- 问LLM“给这个打0-10分”会产生不一致的结果
- 问“这4次尝试中,哪一个最好地实现了目标?”要可靠得多
而且,由于GRPO只需要相对分数,绝对值无论如何都无关紧要。
这个过程分为三步:
- 为一个场景生成N条轨迹
- 将它们传递给LLM评判者,评判者为每条轨迹从0到1打分
- 直接将这些分数用作GRPO中的奖励
无需编写奖励函数。无需收集标注数据。
综合应用:一个实际例子#
我整理了一个完全可运行的笔记本,它通过使用ART进行强化学习,训练一个3B模型来掌握如何使用任何MCP服务器。
只需提供一个MCP服务器URL,这个笔记本就会:
- 查询服务器的工具
- 生成一组使用这些工具的输入任务
- 使用自动RULER评估在这些任务上训练模型
你可以在ART的GitHub仓库中找到更多示例来适应和入门。
(别忘了点个星标 🌟)

感谢阅读!