初级
OpenClaw 集群中的隐藏层:让它们产生分歧,看谁能存活
OpenClaw 集群中的隐藏层:让它们产生分歧,看谁能存活
AI 集群能给你的最危险的输出,是一个完美、一致同意的答案。
这是我如何打破这种局面,以及文末附上一个即用模板的故事。
一个经典的独立开发者困境:5000 美元预算,3 个月时间,200 个免费用户,0 个付费用户。
下一步该怎么走?
我把这个问题抛给了我的 AI 集群。协调器读取了提示,判断需要 4 个专业视角,于是雇佣了他们:一个负责转化分析,一个评估是否应该转型,一个进行决策评分,还有一个审计数据可靠性。
4 位专家同时工作,彼此不知情。1 分 52 秒后,4 份报告返回。
结果:一致同意选项 A。
立即开始收费。
转化分析师提供了一份完整的定价计划:30-100 美元/月,2-4 周内上线付费墙,瞄准 20 个最活跃的用户作为种子客户。
决策评分员对四个选项进行了排名:A 得分 4.40,遥遥领先,其他选项均未超过 3。
转型评估员说首选 A,然后是 C。
数据审计员说先安装分析工具,但最终也是 A。
决策矩阵、转化预测、6 周检查点、精确到每周的行动计划。
看起来无懈可击。
但当我读完时,有一件事挥之不去:4 位专家,4 个分析角度,4 份侧重点不同的报告。
但没有一个人说“我不同意”。
一致通过。
零异议。
在现实世界中,这被称为群体思维。

并行不等于多视角#
大多数 AI 集群是这样工作的:生成一批专家,各自独立分析,最后合并报告。
就像把 4 个人锁在 4 个独立的房间里,每人写一份报告,然后把它们装订成一本手册。
快,是的。
但没人读过别人写的东西。
转化分析师不知道数据审计员写了“我们目前没有用户参与度数据”。所以他基于行业平均值,在一个空的基础上,构建了精确的预测。
让 4 个人写独立的报告然后装订在一起,不等于让 4 个人坐下来开会。
装订本可以很厚,但如果没人拍桌子,厚度不等于深度。

回顾:本应提出哪些问题#
想象你是一位投资者。
创始人把这 4 份报告拍在你面前。
你可能会在 30 秒内问两个问题。
第一:“这 200 个用户中,有多少人还在实际使用产品?”
所有 4 份报告都建立在一个假设上:200 个注册用户 = 200 个潜在付费客户。
但数据审计员在他自己的报告中写道:“我们目前没有用户参与度数据。”其他 3 位专家看不到这一行。
他们各自坐在自己的房间里,基于“行业平均 3% 转化率”进行精确计算:200 × 3% = 6 个付费用户 × 50 美元 = 300 美元/月。
如果这 200 人中只有 15 个还在登录呢?15 的 3% 是零。
建立在沙土上的精确计算比粗略的猜测更危险。
因为它看起来有证据。

第二:“没有一份报告提到竞争对手?”
如果这个类别已经有免费的替代品,增加付费墙不会带来 6 个付费客户。
它会让 200 个免费用户离开。
这些都不是难题。
任何有经验的创始人坐在你对面,5 分钟内都会问完。
但 4 个 AI 专家没有问。
不是因为他们不够聪明,而是因为系统没有“质疑”这一步。
他们被设计来回答问题,而不是挑战答案。
隐藏层#
修复方法并不复杂。
旧的流程是两个步骤:专家写报告 → 协调器合并报告。
缺少的是中间步骤:有人阅读报告并说“等等,这说不通”。
我添加了这一步。
我称之为“对抗轮”。整个流程变成三个阶段:
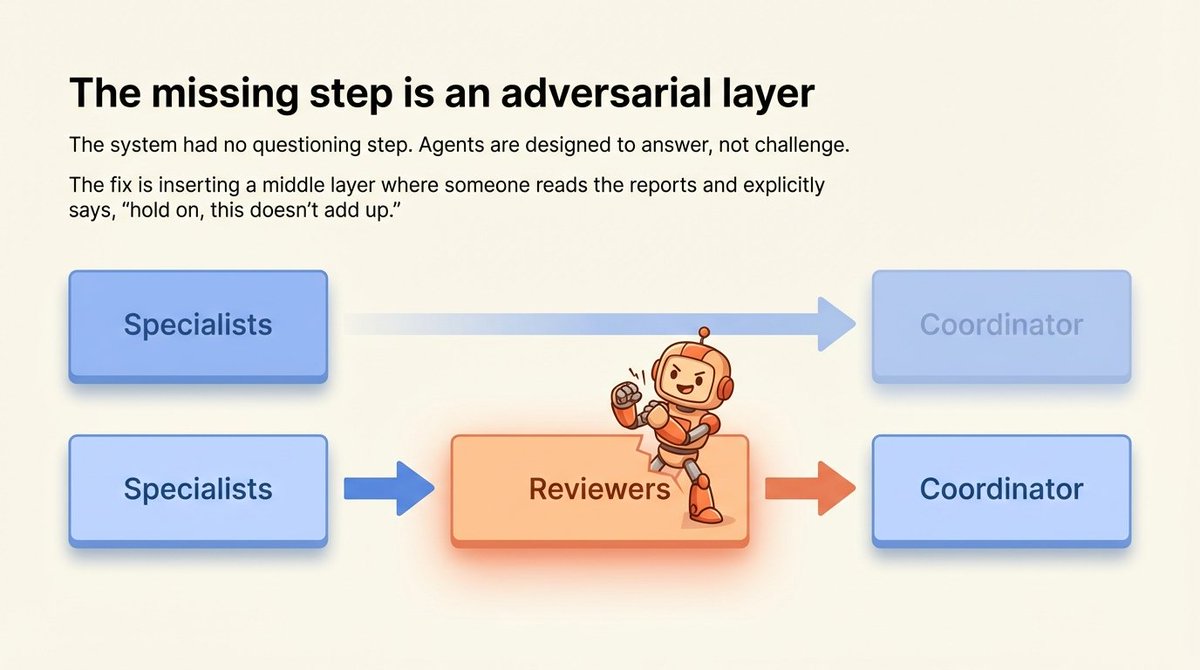
阶段 1:独立分析。
和以前一样。
协调器雇佣一批专家,各自独立撰写,彼此不知情。
这保留了优点:每个人都有自己的思考,不会被别人的框架带偏。

阶段 2:交叉审查。
这是新增的。
所有报告返回后,协调器不急于合并。
相反,它雇佣几位“审查员”。每位审查员获得 2-3 份专家报告。
他们唯一的任务:发现问题。

这里的关键设计是:审查员的任务是硬编码的。
不是“看看有没有问题”,而是一个输出契约。
每位审查员必须交付:
注意末尾的 JSON。
审查员不只是写一个文本意见。
它还输出系统可以直接解析的结构化数据。
proceed, proceed_with_caution, block。三个信号,没有歧义。
为什么要硬编码?
因为如果你只说“请审查一下”,AI 会礼貌地同意并添加一些无害的建议。
这和没有审查一样。

强制要求“你必须找出 3 个问题”让审查员真正去挖掘。
即使原始报告确实很好,审查员也必须找出一些可以挑战的地方。
这不是为了唱反调。
而是为了确保每个结论都至少被认真检查过一次。
另一个关键点:审查员和原始专家完全隔离。
审查员从未看到专家是如何一步步推理的。
他们只看到最终结论。
所以他们的挑战来自外部视角:“你告诉我结论是 A,但我认为你忽略了 X。”这远比“同事检查错别字”有用得多。
而且审查员不是随机分配的。
对抗轮只在有 3 个或更多专家时激活(太少的话交叉审查没有意义)。
一旦激活,系统使用轮换方式分配审查任务:
有 3 个专家时,仅通过轮换就能实现双重覆盖(每份报告被 2 位审查员看到)。
有 4 个或更多时,系统还会在常规审查员之上增加一个“全局怀疑者”。
它不只是阅读 2-3 份报告。
它阅读所有报告。
它的工作是找出那些单独看合理,但结合起来却相互矛盾的地方。

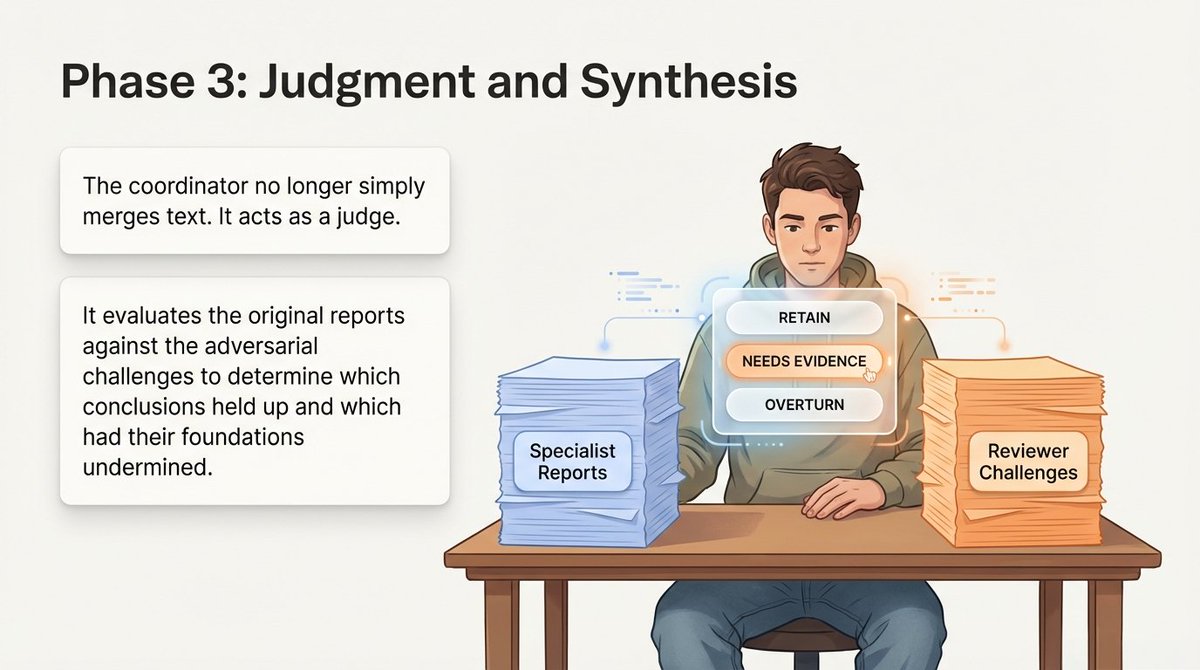
阶段 3:裁决。
协调器现在有两堆东西:原始专家报告和审查员挑战。
它的工作不再是简单地合并。
而是充当法官。
对于每个核心结论,协调器做出裁决:
- 保留 - 审查员挑战了它,但结论站住了脚
- 需要更多证据 - 挑战有道理,需要更多数据来确认
- 推翻 - 挑战直接动摇了结论的基础
在最终输出中,读者不仅看到答案。
还看到答案是如何被测试的。
哪些结论存活了下来,哪些没有。
之前 vs 之后#
同样的问题。
同样的集群。
唯一的区别:有无对抗轮。
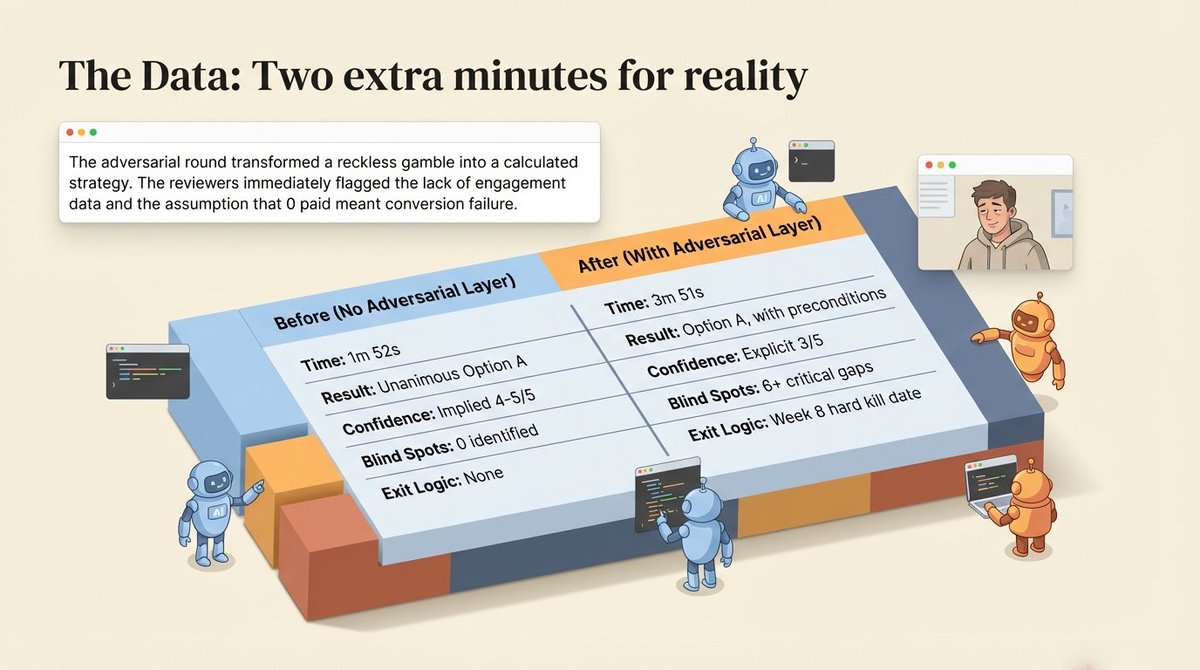
之前(无对抗轮):
4 位专家,1 分 52 秒,一致同意选项 A:立即开始收费。
转化分析师提供了一份完整的定价计划。
决策评分员给 A 打了 4.40 分,其他都低于 3。
转型评估员说首选 A 然后是 C。
数据审计员说先安装分析工具但最终也是 A。
精确到每周的行动计划:第 2 周上线付费墙,第 6 周检查结果。
信心?
没人明确说,但 4 个人都选同一个答案意味着“这甚至没有争议”。
读起来很好。
之后(有对抗轮):
同样的问题,4 位专家 + 3 位审查员(包括一个全局怀疑者)+ 1 位综合者,3 分 51 秒,8/8 完成。
审查员立即发现了专家们集体忽略的盲点。
审查员 1 直击核心:“所有专家都假设 200 个用户是活跃用户,但提示只说‘200 个免费用户,0 个付费’,没有任何参与度数据。
如果这 200 人中大多数注册后就没再回来,那么每个转化基准都是建立在虚假的基础之上。”
审查员 2 跟进:“0 个付费可能根本不是转化失败。
这可能意味着从未尝试过付费墙。
如果创始人从未要求任何人付费,0/200 不是一个负面信号。
这是一个无效实验。”
全局怀疑者最尖锐。
读完所有专家报告后,它指出一位专家的说法“0 个付费几乎总是意味着没有尝试过付费墙”,置信度评为 4/5。
全局怀疑者的评估,一句话:“披着数据外衣的乐观偏见。”
所有三位审查员的裁决:
proceed_with_caution。没有一个
proceed。综合者收到专家报告和审查员挑战后,做出了裁决:
- 选项 A 从“强烈推荐”降级为“有条件推荐”
- 增加了一个专家从未有过的步骤:第 1 周,先回答三个关键问题 - 付费墙是否曾经存在过?D7/D30 留存率是多少?这 200 个用户从哪里来?
- 选项 C 从“不考虑”升级为“如果第 3 周数据未达到阈值,立即切换”
- 增加了一个硬性退出条件:第 8 周,如果零付费客户且未识别出可行的利基市场,放弃项目并保留剩余资金
- 最终置信度:3/5。不是 4,不是 5。
综合者明确承认这个计划可能是错的。
最终输出不再是一个单一的答案,而是一个决策树:A→C→D,每一步都有明确的进入和退出条件。
最终建议大致相同吗?
是的。
两者都说 A。
但区别在于:之后的计划知道自己可能是错的,并且已经计划好了如果错了该怎么办。
之前的计划不知道自己可能错。
这不仅仅是“建议”层面的改变。
在代码中,审查员的裁决直接反馈到状态机:
简单逻辑:如果审查员标记了
block 并且综合者没有产生明确的“GO”,系统会自动回退到 HOLD,整个任务标记为失败。不是“这里有个警告,风险自负”。而是实际上不通过。
这就是对抗层和橡皮图章审查的区别:它有牙齿。

一个从未经过测试的自信答案,和一个经受住挑战的自信答案——价值完全不同。
这是真实的数据对比:
之前(无对抗层):4 位专家。1 分 52 秒。一致同意选项 A。隐含置信度 4-5/5。零盲点识别。无退出条件。单一选项。
之后(有对抗层):4 位专家 + 3 位审查员 + 1 位综合者。3 分 51 秒。选项 A,带有先决条件。明确置信度 3/5。6+ 个关键盲点被识别。第 8 周硬性终止日期。A→C→D 顺序决策树。
多花了两分钟。
换来的是:一个知道自己边界在哪里的答案。
从个性到系统#
我其实更早尝试过让智能体彼此“争论”。
方法很粗糙:我在一个智能体的个性描述中写道,“你经常不同意 Xalt 的观点”。
有点效果。
那个智能体在日常对话中偶尔会反驳,讨论质量有所提高。
但这是“个性摩擦”,依赖于两个长期合作的智能体之间的“关系”。
临时雇佣的专家没有个性,没有历史,存在时间不到 2 分钟。
你无法在一个只活 2 分钟的人身上培养批判精神。
对抗轮做了不同的事情。
它不依赖于“这个智能体是谁”。它依赖于“流程是否包含质疑步骤”。无论哪个专家,无论哪个审查员,只要流程有这个步骤,输出质量就会提高。
这就像代码审查存在的原因。
不是因为你信不过写代码的人。
而是因为第二双眼睛能看到第一双眼睛看不到的东西。
即使编码者是团队中最强的工程师,审查仍然有价值。
AI 集群也是如此。
每个专家可能都很优秀。
但一个从未被挑战过的结论——你不知道它到底是对的,还是只是没人检查过。

拿去用吧#
无论你使用什么工具,下面的模板都可以开箱即用。
三阶段协调器提示#
你是一个决策协调器。
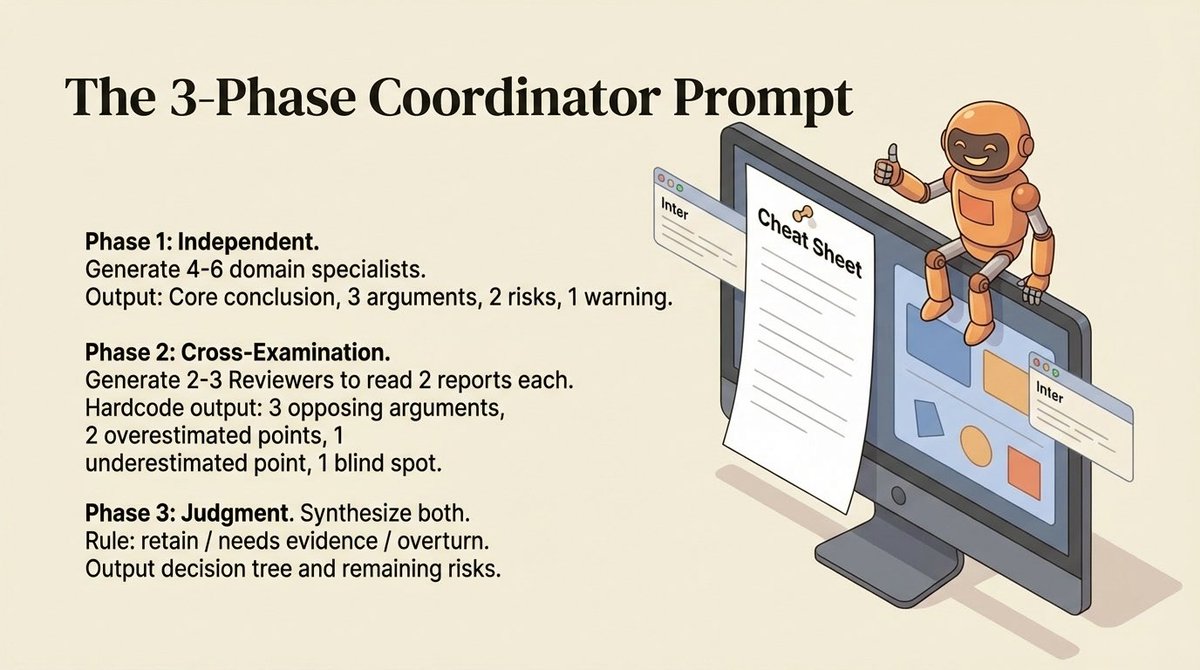
请分三个阶段完成分析:
阶段 1:独立分析
- 根据问题需要,从不同领域生成 4-6 位专家
- 每位专家独立分析,彼此不知情
- 每位专家必须输出: · 核心结论 + 置信度评分 (0-5) · 3 个最强有力的支持论点 · 2 个最大风险或未验证的假设 · 1 个“这个结论看起来正确但可能有问题”的警告
阶段 2:交叉审查
- 收集所有报告后,生成 2-3 位审查员
- 每位审查员收到 2-3 份专家报告
- 每位审查员必须输出: · 3 个反对论点(必须具体,不能说“总体看起来不错”) · 2 个被高估的点(大家都认为重要,但可能并非如此) · 1 个被低估的点(大家都忽略了,但可能很关键) · 1 个“完全没人提到”的盲点
阶段 3:裁决
- 综合专家报告 + 审查员挑战
- 对每个核心结论进行裁决:保留 / 需要更多证据 / 推翻
- 标记哪些结论经受住了挑战,哪些没有
- 给出最终建议,附带置信度水平和剩余风险
如何配置#
简单问题(在几个选项中选择):4 位专家 + 2 位审查员。
复杂问题(开放式研究,如行业分析或产品策略):6 位专家 + 3 位审查员。
审查员不需要与专家一一对应。3 位审查员覆盖 6 份报告,每人阅读 2 份,每份报告至少被 1 位审查员看到,就足够了。
最重要的一点:审查员的输出格式必须是硬编码的。“3 个反对论点”不是建议,而是硬性要求。
没有这个约束,审查员会礼貌地说“分析很全面,我基本同意”,而你花钱请的审查员就成了橡皮图章。
没有 AI 集群也能用#
没有多智能体系统?
没问题。
只要你有一个 AI 聊天窗口,就可以手动运行这三个步骤:
- 告诉 AI“你是一位市场专家”,让它分析问题,保存结论
- 打开一个新对话,告诉 AI“你是一位财务专家”,让它分析同一个问题
- 再打开一个新对话,粘贴两位专家的结论,告诉 AI“你是一位审查员,你的工作是找出这两份报告中的矛盾、盲点和未验证的假设”
这不会像真正独立的多智能体运行那么好——同一个模型与自己争论,不会仅仅因为你改变了角色就摆脱自己的认知盲点。
但这远比问一次就拿走一个单一答案要好得多。
对抗性思维不是目标。
验证才是。
工具不重要。
重要的是,在你做决定之前,是否有人(或某个步骤)试图推翻你的结论。
共识不是目标#
AI 团队和人类团队陷入同样的陷阱:最危险的时刻不是人们开始争论的时候。
而是每个人都点头的时候。
争论意味着分歧。
分歧意味着你知道有风险,可以调查、验证。
一致同意才可怕:“4 位专家都同意了,所以肯定没问题。”然后你执行,掉进一个没人看到的坑里。
好的决定从来不是“通过”的。好的决定是“有人试图推翻它们,但它们仍然站住了脚”。
AI 集群的下一步不是增加更多专家。
更多专家只意味着更多报告、更厚的装订本、更强的虚假安全感。
下一步是在你的流程中添加一轮挑战。
让结论在被采纳前受到严肃的挑战。
我们按照自己的形象构建 AI 系统。
奖励一致同意的团队构建出同意的智能体。
奖励速度的团队构建出跳过验证的智能体。
架构反映了构建者。
如果你的智能体总是对彼此说“是”,问题不在于你的智能体。
而在于你优化了什么。
添加对抗层最难的部分不是代码。
而是接受你的第一个答案可能是不完整的。
这个对抗层是一个更大系统的一部分。
如果你想了解完整的集群如何工作,协调器如何雇佣专家,审查员如何交叉审查报告,综合者如何做出最终裁决,我在之前的一篇文章中写过架构:我用 OpenClaw 建立了一家 AI 公司。现在它在招聘。
你也可以在 voxyz.space/swarm 观看集群的实时运行。
如果你想要完整的编排套件、数据库、工作器、协调器、仪表板,它在 Ship Faster Pro 中。
存活下来的答案才值得信任。
