Beginner
Improving AI Skills with autoresearch & evals-skills
Improving AI Skills with autoresearch & evals-skills
I’ve been trying to improve my AI skills using Auto Research, a library @karpathy shared for automatically improving AI prompts through repeated experimentation.
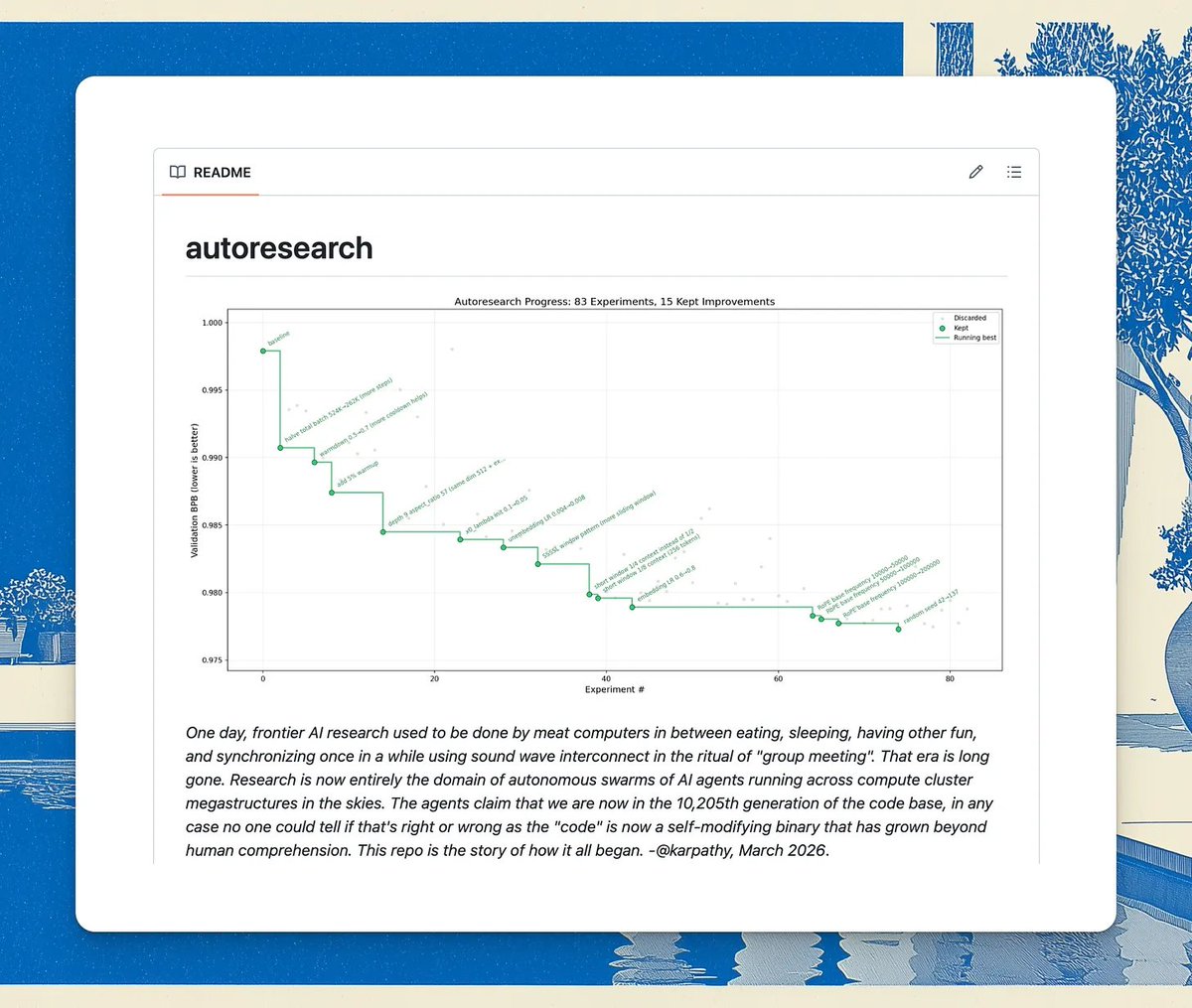
I saw Ole on X share his fork of auto-research turned into a skill that is meant to tune other skills, so I decided to try that.
The idea is straightforward: define some test inputs, write judges that score outputs, let the optimization loop run, wake up to a better skill.
I ran it three times before I understood what I was doing wrong.
Take one, I just pointed it at a skill.#
I picked a new set of skills I’d built and was about to add to my AI PM skills library, handed it to Auto Research, and let the tooling do everything else. It generated the test inputs. It wrote the judges. It ran the optimization loop overnight.
The scores went up almost immediately. It all looked great until I looked at what had changed.
Unfortunately, the skills were far from improved.
The problem wasn’t the tool. Auto Research did exactly what it was designed to do: run a systematic optimization loop against whatever criteria you give it.
The issue was the criteria. They were machine-generated with no model of what real failure looked like, no grounding in actual observed behavior.

So the loop ran hundreds of experiments and got very good at satisfying those criteria. The skill got better at the wrong things.
Take two, I wired in @HamelHusain's eval skills for input generation.#
Hamel has done substantial work on the evals problem with @sh_reya.
Quoted tweet So many people talking about AI evals. @HamelHusain and @sh_reya show me how to actually build one. Live. Hamel and Shreya teach the world’s most popular course on evals, and have long been at the forefront of this emerging and important new skill for AI product builders. I'm ... https://x.com/i/web/status/1971245503972245982
The skill for generating synthetic evals is more principled than just asking a model to come up with test cases: you define dimensions of the input space (what feature the user wants, what persona they are, what scenario they’re in), then generate structured tuples across those combinations.

My inputs got genuinely better: more diverse, better coverage of edge cases, less vibed.
But I still left generation to the tooling again. The inputs improved, but not by much, because the LLM was still vibing it. I wasn’t providing any input or correction manually. The judges also didn’t improve.
And the judges are where comprehension lives.
I still hadn’t personally read any outputs. Still hadn’t built any intuition from observation. The machine had better inputs to work against and still no real model of failure.
Take three, I read the Evals course reader 😑#

I imported Hamel’s evals course reader PDF into NotebookLM and worked through it using the NotebookLM CLI in Cursor before running anything.
From taking the course I remembered the Three Gulfs, and the Analyze-Measure-Improve lifecycle that’s built around them.
- The Gulf of Comprehension is the gap between what you think your system does and what it actually does. What failure looks like in the outputs, which cases break, in which ways, for which reasons. It’s the first gulf because, as far as I can tell, it has to be closed before anything else can work. No automation can close it. Only reading closes it.
- The Gulf of Specification is the gap between what you want your system to do and what your judges measure. This seems to be the direct consequence of skipping comprehension. If you haven’t seen real failure, I don’t think you can write a judge that measures what matters. In rounds one and two, my judges were measuring an imagined target. Optimizing against that was optimizing against a fantasy.
- The Gulf of Generalization is the gap between how the system performs on your test inputs and how it performs on inputs it’s never seen. This is the gulf that Auto Research’s optimization loop can address. But only if the first two are already closed.
The course is blunt about this: “If you are not willing to look at some data manually on a regular cadence you are wasting your time with evals.”
In the first two takes, I was wasting my time with evals.
The manual work to close the Gulf of Comprehension is what Hamel calls error analysis — Phase 1 of the Analyze-Measure-Improve lifecycle. It works like this:
- Open coding. Run your skill on a set of diverse inputs and read every output. Don’t categorize yet. Just write freeform notes on what’s wrong. Which outputs are too generic. Which miss constraints the input spelled out. Which are off in a way you can feel but couldn’t have predicted. This is where you build intuition about failure that no tool can build for you.
- Axial coding. Take those freeform notes and group them into a coherent failure taxonomy: a small set of distinct, binary failure categories. “Too abstract,” “missed enterprise constraints,” “wrong level of specificity.” These become the thing your judges should measure.
- Write judges grounded in the taxonomy, written against what you saw.
- Validate the judges. Build a mini golden dataset: manually score fifteen to twenty outputs per criterion before trusting any judge to run autonomously. This is how you calibrate the Gulf of Specification: you check whether the judge agrees with your own labels on cases you’ve already reasoned about.
Then you run Auto Research, and only then.
For take three, I ran this sequence on the skill I’d been trying to improve.
I varied the inputs.
Then I read everything it output.
I coded failures (freeform in chat, which was a sloppy way to do it), and the LLM grouped them, built the taxonomy, wrote judges against it, and I validated them manually on fifteen outputs. Then the loop ran.

Apparently this is what gave the skill all the extra juice:

So as you can see, even on take 3, I still cheated and didn’t go all the way, and this is why the final result is still not where I want the skill to be. But the point still stands.
The pattern that repeated across all three takes: I kept wanting to skip the comprehension step and get to the automated part. It felt like moving faster. But I think I was just making the machine efficient at measuring the wrong things.
The challenge with evals is that the objective function is so subjective that you basically cannot get away from setting up the measurement system first manually. (Unless you can upload your taste with all the nuances into an auto-evaluator from a cold start, maybe in the future.) Later, judges can automate part of the process, but only once you trust their judgment enough to operationalize it.
I don’t think you can automate your way past understanding. Someone has to close that first gulf, and in my experience, that someone is always you.
The Product Equivalent#
PMs do the same thing with product decisions that I was doing with my AI evals.
Skipping the manual comprehension phase, just jumping to solutions or success metrics, then measuring hard against criteria that don’t reflect the actual problem. "Users need proactive insights, it's obvious." "We will measure DAU/MAU."
That’s how you end up shipping a feature because you’re confident about what users want. Setting up dashboards before you understand what you’re measuring. Running discovery without being clear on what you need to learn, why it matters, or how you’ll learn it. Without personally synthesizing enough evidence to develop real intuition about where things break.
The Gulf of Comprehension has a product equivalent: the gap between what you think users struggle with and what they struggle with.
It doesn’t close from a survey dashboard. It closes when you’ve personally read enough customer conversations, support tickets, and interviews to develop a feel for what failure looks like. That intuition is what makes your assumptions specific enough to test, and your solutions specific enough to have real fit.