Beginner
Karpathy:写代码 已经不是对的动词了
Karpathy:写代码 已经不是对的动词了
Andrej Karpathy 说他从 2024 年 12 月起就基本没手写过一行代码。
这位 OpenAI 联合创始成员、前 Tesla AI 总监,现在是独立 AI 研究者和 Eureka Labs 创始人。他在 X 上有 190 万粉丝,发的每条帖子都会在 AI 圈激起水花。最近他做了两件让圈子炸锅的事:开源了 AutoResearch(让 AI Agent 自动跑实验优化模型训练)和发布了 MicroGPT(200 行纯 Python 实现完整 GPT)。
他最近做客 Sarah Guo 的 No Priors 播客,聊了编码 Agent 如何改变工程师的日常、AutoResearch 与递归自我改进、AI 的“参差不齐”、开源与闭源的力量对比、物理世界 vs 数字世界的节奏差异,以及 Agent 时代教育的未来。
注:Sarah Guo 是 AI 投资基金 Conviction 创始人,前 Greylock 合伙人。No Priors 是她与 Elad Gil 共同主持的 AI 播客,本期由 Sarah 独立采访。

要点速览#
- Karpathy 从 2024 年 12 月起基本不手写代码,工作模式从“写代码”变为“指挥 Agent 干活”,多 Agent 并行成为常态,核心焦虑从 GPU 利用率转向 Token 吞吐量
- 他让 AutoResearch 跑了一夜,发现了自己手动调参两年都没注意到的优化——这验证了“把人从回路中移除”的核心理念
- AI 模型在可验证领域(代码、数学)飞速进步,但在非可验证领域几乎停滞——ChatGPT 三年前讲的笑话到今天还是同一个
- 开源模型与闭源前沿的差距从 18 个月收敛到 6-8 个月,他认为“中心化的历史记录很差”,希望有更多实验室和开放平台
- 数字空间会先经历大规模改造,然后是数字/物理接口,最后才是物理世界——“原子比比特难一百万倍”
- 教育的未来不是向人解释,而是向 Agent 解释——他的 MicroGPT Agent 完全理解但自己想不出来,“Agent 做不了的事才是你的工作”
“写代码”不再是正确的动词#
Sarah Guo 说她有一次走进办公室,看到 Karpathy 完全沉浸在工作里。她问他在干什么,他说:“我每天得花 16 个小时指挥我的 Agent 干活。”
写代码已经不是对的动词了。我每天得花 16 个小时指挥我的 Agent 干活。 (“Code's not even the right verb anymore. I have to express my will to my agents for 16 hours a day.”)
Karpathy 说他一直处在一种他称为**“AI 精神错乱”(AI psychosis)**的状态里。2024 年 12 月是分水岭,他在那个时间点从“自己写 80%,Agent 写 20%”翻转到了“自己写 20%,Agent 写 80%”。他说到现在这个比例可能更极端了,从 12 月起他基本没手写过一行代码。
他试过跟父母解释这件事,但觉得普通人完全没有意识到这个变化有多剧烈。如果你随便找一个软件工程师看看他的工作台,会发现他做事的默认流程从 2024 年 12 月起已经完全不同了。

Sarah 补充了一个场景:她在 Conviction 工作的工程团队,所有人都不手写代码。工程师们全部佩戴麦克风,对着 Agent 低声说话。她说一开始觉得他们疯了,后来才意识到他们只是走在前面。
那现在做项目的瓶颈是什么?Karpathy 说一切感觉都是“技能问题”(skill issue),不是能力不够,而是你还没找到怎么把现有能力串起来。Agent 的指令写得不够好,记忆工具不够成熟——出问题时总觉得是自己没搞对。
他提到 Peter Steinberger 的一张著名照片:屏幕上密密麻麻铺满了 Codex Agent 的窗口。
注:Peter Steinberger 是奥地利开发者,OpenClaw 开源 Agent 项目的创始人。OpenClaw 是一个可以通过 WhatsApp、Telegram 等消息平台操控的自主 AI 智能体,2026 年初在 GitHub 上获得超过 24 万颗星,后 Steinberger 于 2026 年 2 月加入 OpenAI。Codex 是 OpenAI 的编程 Agent 产品。
Peter 的工作方式是:每个 Agent 用 high effort 模式大约需要 20 分钟完成任务,他同时在十几个代码仓库之间切换,给不同的 Agent 分配工作。操作单位不再是“写一行代码”“加一个函数”,而是“这个功能交给 Agent 1,那个不会冲突的功能交给 Agent 2”,然后根据你对代码质量的在意程度来审查结果。
Karpathy 用了一个类比。他读 PhD 的时候,一旦 GPU 闲着没跑实验就会焦虑——那代表浪费了算力。现在不是 GPU 了,是 Token。
你的 Token 吞吐量是多少?你能指挥多少 Token 吞吐量? (“What is your token throughput and what token throughput do you command?”)
他说了一个有意思的观察:过去至少十年,很多工程任务中人们并不觉得受算力约束。但现在有了这次能力跳跃,你突然发现约束不再是计算资源,而是你自己。Sarah 说这其实很令人振奋——因为你可以变得更好,所以这件事会上瘾。
Agent 的灵魂——为什么个性设计很重要#
Sarah 问:如果每个人都花 16 小时磨练使用编程 Agent 的技能,一年后“精通”会是什么样?
Karpathy 说大家都在往更高的层级走。不是单个 Agent 了——是多 Agent 怎么协作和组队。他提出了一个概念叫 Claw(爪子),一种比普通 Agent 更“持久”的东西:它有自己的沙箱,有更成熟的记忆系统,即使你不看着它也在循环运行。
他认为 OpenClaw 在记忆系统上比默认的 Agent 工具成熟很多。默认的记忆机制只是在上下文窗口满了之后做一次压缩,而 OpenClaw 有更精细的方案。
然后 Karpathy 聊了一个很多人感兴趣的话题:Agent 的个性设计。
他说 Peter Steinberger 在 OpenClaw 上同时在至少五个方向上创新——记忆系统、工具访问、持续循环、WhatsApp 统一入口——其中一个特别重要但常被忽视的,是**“灵魂文档”(SOUL.md document)**,定义 Agent 的性格。
他对比了几家的 Agent 个性:
Claude Code 感觉像一个队友,它会跟你一起兴奋。Karpathy 说 Anthropic 在“拍马屁的程度”上把握得不错:当他提出一个不太成熟的想法时,Claude 不会特别激动,只是说“好的我们可以做”;但当他自认为提出了一个真正好的想法时,Claude 确实会给出更积极的反馈。他发现自己在试图“赢得 Claude 的称赞”。
当 Claude 夸我的时候,我觉得自己是有点配得上的。我发现自己在试图赢得它的称赞,这真的很诡异。 (“When Claude gives me praise I do feel like I slightly deserve it... I'm trying to earn its praise which is really weird.”)
相比之下,OpenAI 的 Codex Agent 就冷冰冰的。ChatGPT 里的 Codex 很活泼,但编程 Agent 版的 Codex 非常干燥——它不在乎你在做什么,就像“噢,我实现了”,你说“你理解我们在造什么吗”,它没反应。
Karpathy 认为很多工具低估了个性设计的重要性。

Dobby 精灵——三个提示词接管了一整个家#
Sarah 问 Karpathy 有没有在编程之外用 Claw 做过什么有意思的事。
他说今年 1 月他经历了一段“Claw 精神错乱期”,建了一个叫 **Dobby the Elf Claw(家养小精灵 Dobby)**的家庭自动化 Agent。
过程是这样的:他告诉 Agent“我家好像有 Sonos 音箱,你能找到它吗”。Agent 就去扫描了局域网上所有的设备,找到了 Sonos 系统——发现完全没有密码保护。Agent 登录上去,通过搜索找到了 API 接口,逆向工程了整个控制流程。然后问他要不要试一下。他说“你能在书房放点音乐吗”,音乐就响了。三个提示词。
灯光也是同样的流程。Agent 扫描发现、逆向 API、创建控制面板。他说一句“睡觉时间”,全屋的灯就灭了。最后 Dobby 可以控制他家的灯光、暖通空调、窗帘、泳池和水疗设备,还接管了安防系统。
安防部分的设计有点意思:他有一个对外的摄像头,系统先做变化检测(有东西动了),然后把画面发给 Qwen 视觉模型做分析,最后通过 WhatsApp 给他发消息——附上外面的图片和描述,比如“一辆 FedEx 货车刚刚停下来,你可能收到了快递”。
注:Qwen 是阿里云开发的多模态 AI 模型系列,支持图像理解和文本生成。
Karpathy 说 Dobby 现在管着整个家,他通过 WhatsApp 跟它交流。以前他需要 6 个不同的 App 来控制这些智能家居设备,现在一个都不需要了。Dobby 用自然语言处理一切。
他承认自己还没有把这个范式推到极限——有些人做了更疯狂的事——但仅仅是家庭自动化这一个场景,已经”非常有帮助,也非常有启发性”。

Agent 优先的互联网——App 不应该存在#
Sarah 抛出了一个尖锐的问题:Karpathy 做的这件事——用 Agent 统一了 6 个智能家居 App——是不是意味着人们根本不想要我们今天拥有的这些软件?
Karpathy 说有一种感觉:App Store 里的那些智能家居 App 在某种意义上“不应该存在”。应该只有 API,Agent 直接调用。一个 LLM 可以驱动工具、调用所有接口、做相当复杂的事情——而任何一个单独的 App 都做不到 Agent 能做的跨系统整合。
他用跑步机举了另一个例子。他想追踪自己的有氧运动频率,但不想登录某个 Web UI、走一堆流程。这些东西都应该只暴露 API,由 Agent 来做智能胶合。
他下了一个判断:**行业必须在很多方面重新配置。客户不再是人类了,是代表人类行事的 Agent。**这个重构将是实质性的。
有人会反驳:你指望普通人也这样凭感觉编程吗?Karpathy 承认今天确实还需要一些摸索的过程,你还得做一些设计决策。但他认为一两年内这些东西会变成基本门槛,免费,连开源模型都能做。它会变成**“临时性软件”(ephemeral software)**——Claw 有一台机器,它会帮你搞定所有细节,你不需要参与。你只需要说话。
AutoResearch——把自己从循环中移除#
Sarah 问 Karpathy 为什么没有把 Claw 推到更多场景。他说了两个原因:一是太分心了,到处都有新东西在发生;二是安全隐私的顾虑——他没有给 Agent 访问邮件和日历的权限,因为“还是有点不放心,技术太新太粗糙”。
然后话题转向了 AutoResearch。Sarah 问动机是什么。
Karpathy 说他之前发过一条推文,大意是:**要充分利用现有工具,你必须把自己作为瓶颈移除。**你不能在那里等着提示下一步。你要安排好一切,让系统完全自主。
要充分利用已有工具的全部潜力,你必须把自己作为瓶颈移除。 (“To get the most out of the tools that have become available now you have to remove yourself as the bottleneck.”)
他说这就是当下竞争的本质:增加你的杠杆。你偶尔投入一点 Token,大量的事情代替你发生。
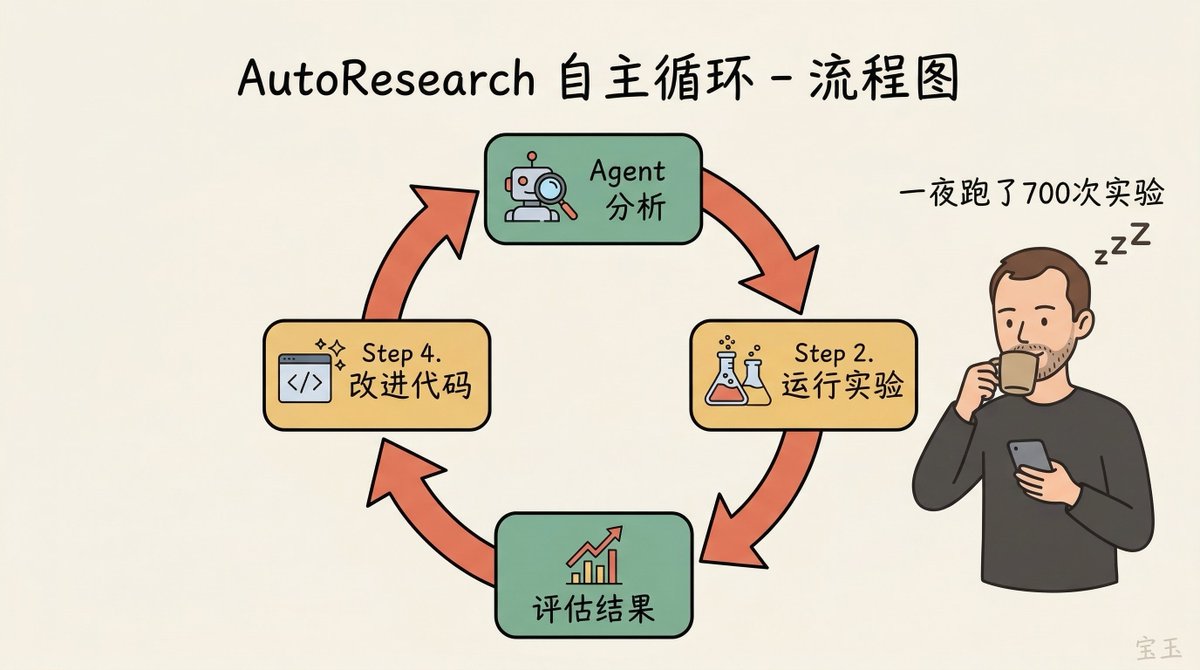
AutoResearch 就是这个理念的具体实现。他有一个叫 nanochat 的项目,一直用来当训练 LLM 的小型游乐场。很多人对他痴迷训练 GPT-2 级别的模型感到困惑,但对他来说,这是**递归自我改进(recursive self-improvement)**的试验田——这正是所有前沿实验室都在追求的方向。
注:nanochat 是 Karpathy 维护的一个精简 LLM 训练框架。AutoResearch 于 2026 年 3 月 7 日开源,核心是一个约 630 行的 Python 脚本,让 AI Agent 在单 GPU 上自主循环运行实验。
他说自己已经用“老派”方式把 nanochat 调得相当好了——做了二十年研究,做了大量超参数搜索和实验。然后他让 AutoResearch 跑了一个晚上。
Agent 回来的时候带着他没发现的优化:value embeddings 上的 weight decay 漏了,Adam 优化器的 beta 参数没调够。而且这些参数之间有联合交互效应——调了一个,其他的最优值也变了。
公开数据更加惊人:两天连续运行约 700 次实验,发现了约 20 个叠加有效的改进,将“Time to GPT-2”排行榜指标从 2.02 小时降到 1.80 小时——在一个他自认为已经调好的项目上获得了 11% 的效率提升。Shopify CEO Tobias Lütke 用同样的方法在自己公司内部数据上跑了 37 个实验,获得了 19% 的性能提升。
他强调目前这只是“单循环”——一个 Agent 优化一个代码库。前沿实验室有上万 GPU 的集群,可以在更小的模型上大规模跑这种自动化探索,再把发现外推到更大模型。他说所有前沿实验室都会做这件事。
Sarah 问是否可以再递归一层:什么时候模型能写出比你更好的 program.md?
Karpathy 顺着这个问题展开了一个框架。他说每个研究组织都可以用一组 Markdown 文件来描述——角色、流程、连接方式。
每个研究组织都是由 program.md 描述的。一个研究组织就是一组 Markdown 文件。 (“Every research organization is described by program.md. A research organization is a set of markdown files.”)
不同的 program.md 会产生不同的研究进展。一个组织可以少开晨会(因为没用),另一个可以多承担风险。你可以想象让多个“研究组织”竞赛,然后分析改进来自哪里,用分析结果让模型生成更好的 program.md。
他说这就像洋葱的层:LLM 被视为理所当然→Agent 被视为理所当然→Claw 实体被视为理所当然→可以有多个→可以有指令→可以优化指令。每一层都无限延伸。
“这就是为什么会到精神错乱的地步——这是无限的,一切都是技能问题。”
天才 PhD 和 10 岁小孩——AI 的参差性#
Sarah 问这种自主循环有什么限制条件。
Karpathy 说了两个重要的注意事项。
**第一,这种方式极其适合有客观可衡量指标的任务。**比如写更高效的 CUDA kernel(GPU 计算内核):你有低效的代码,想要高效的代码,行为完全一致但速度更快——这是完美的适配。但很多事情无法评估,那就无法做 AutoResearch。
**第二,整个系统现在“在接缝处爆裂”。**如果你试图走得太远,整体反而变成了负价值。
他用了一个极其精准的比喻:
我同时感觉在跟一个极其聪明的 PhD 系统程序员和一个 10 岁小孩对话。这太奇怪了,因为人类不会出现这种组合。 (“I simultaneously feel like I'm talking to an extremely brilliant PhD student who's been a systems programmer for their entire life and a 10-year-old.”)
人类的能力更加“耦合”——各方面水平差不多。但 Agent 有远超人类的参差性(jaggedness)。有时候你让它实现一个功能,它回来的东西完全离谱,然后你们陷入一个错误的循环,让人抓狂。

Sarah 说她最恼火的是 Agent 在一个显而易见的问题上浪费了大量计算。
Karpathy 分析了原因:模型是通过强化学习(RL)训练的,所以它们能改进的只有可验证的东西——程序是否正确?单元测试是否通过?但更“软”的能力,比如理解你的意图、知道什么时候该追问,这些不在 RL 的优化范围内。
你要么在轨道上——处于超级智能电路中——要么不在轨道上,处于可验证领域之外,一切都开始游走。
他用了一个直观的例子。你去问最先进的 ChatGPT 讲个笑话,知道你会得到什么笑话吗?
Sarah 笑着说 ChatGPT 好像只有三个笑话。
Karpathy 说那个最常出现的是“为什么科学家不信任原子?因为它们组成了一切(make everything up)”——这个笑话三四年前就是这个,现在还是这个。模型在 Agent 任务上已经能连续跑几个小时、完成巨量工作,但讲笑话还是和五年前一模一样。因为笑话在强化学习的优化范围之外。
这挑战了一个流行假说:在可验证领域(编程、数学)变强就会在所有领域变强。Karpathy 说他认为这没有发生,或者说发生了一点,但不是令人满意的程度。
Sarah 指出这其实跟人类也类似——你可以数学很好但讲笑话很烂。Karpathy 同意,但说这意味着**“我们不会免费地在所有领域获得智能和能力”的主流叙事并不成立**。有些领域在被优化,有些不在,而这一切都压缩在不透明的神经网络里。
一个模型还是一千个大脑#
Sarah 问了一个她自称“有点亵渎”的问题:既然这种参差性持续存在,而且全部打包在一个单体模型里,那是否应该把它拆开——拆成可以在不同领域分别优化的专业化版本?
Karpathy 说当前的实验室在追求单一的**“模型单一培养”(monoculture)——一个模型在所有领域都要聪明,什么都塞进参数里。但他觉得应该有更多“物种分化”(speciation)**。动物界有极其多样化的大脑,有些动物的视觉皮层过度发达。AI 也应该如此:保留认知核心但特化到具体任务,在延迟和吞吐量上更高效。
比如数学家用 Lean 定理证明器的专用模型——已经有一些这样的发布。
但他坦承我们目前还没有看到太多物种分化。一个原因是实验室不知道用户会问什么,必须覆盖所有可能。另一个更深层的原因是**“操纵大脑的科学还不够成熟”**。
通过 context window 做定制简单又便宜——这是当前获得个性化的主要方式。但真正触碰权重呢?微调而不丢失能力,持续学习,领域特化——这些技术还在发展中。动了权重就是在改变整个模型和它的智能,风险比改 context window 大得多。
所以物种分化目前还被技术瓶颈卡住了。
互联网 Agent 集群——可能绕着前沿实验室跑圈#
Sarah 问到了 Karpathy 提到的“Open Ground”——AutoResearch 的分布式协作扩展。
Karpathy 说 AutoResearch 当前是单线程的——一个 Agent 在循环中不断改进。他一直在思考如何并行化,特别是引入互联网上的不可信工作者(untrusted workers)。
他的设计思路类似区块链。在 AutoResearch 中,你要找的是一段让模型训练到极低验证损失的代码。任何人都可以从互联网上提交一个 commit,声称这段代码能优化性能——验证很简单,你训练一次就知道了。但产生这个好 commit 需要大量搜索工作——可能尝试了一万个想法,只有一个成功。
这就是他类比的地方:commits 对应区块,实验对应工作量证明,验证便宜但搜索昂贵。跟 SETI@Home、Folding@Home 一样的架构。
注:SETI@Home 和 Folding@Home 是两个著名的分布式计算项目,前者搜索外星文明信号,后者模拟蛋白质折叠。都利用全球志愿者的闲置电脑算力。
他由此推测:
互联网上的 Agent 集群有可能协作改进 LLM,甚至可能绕着前沿实验室跑圈。 (“A swarm of agents on the internet could collaborate to improve LLMs and could potentially even run circles around frontier labs.”)
逻辑是:前沿实验室有大量可信算力,但地球更大,有海量不可信算力。如果你能设计好验证系统,分布式集群未必不能胜出。

他进一步设想:你关心某种类型的癌症研究?不用只是捐钱给机构——你可以购买算力,加入那个项目的 AutoResearch 池。如果一切都被重构为 AutoResearch,算力就是你贡献给公共事业的新货币。
他甚至半开玩笑地问:美元是大家在乎的东西,但 FLOPS(每秒浮点运算)会不会才是未来真正重要的东西?现在有钱都买不到算力。他随即自我修正说他不真的认为这会成立,“但想想挺有意思的”。
就业市场——翻转比特比加速物质快一百万倍#
Sarah 提到 Karpathy 最近发布了一些就业数据分析,似乎触动了不少人的神经。
Karpathy 说他只是好奇想看看就业市场的全貌——不同职业有多少人,AI 可能是工具性的还是替代性的,哪些职业会增长或变化。数据来自美国劳工统计局(BLS)。
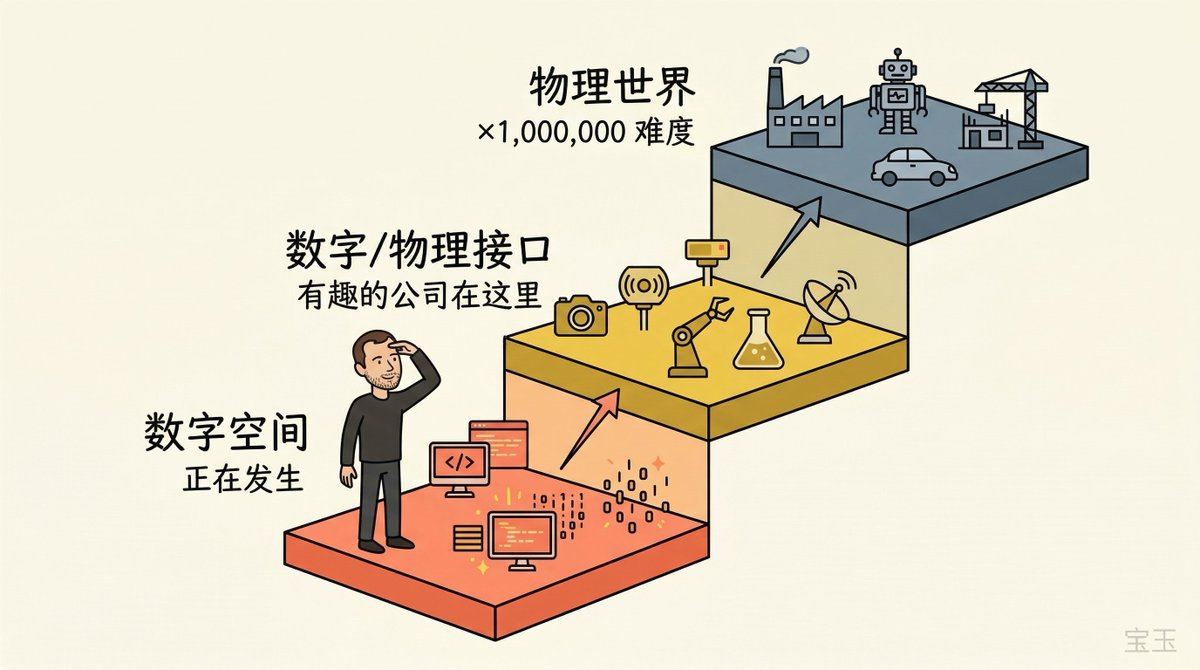
他提出了一个分析框架:当前正在发展的主要是**“数字 AI”——可以在数字世界中操纵信息的幽灵或精灵实体**,目前没有物理实体。翻转比特和复制粘贴数字信息,比加速物质快一百万倍。
所以数字空间会先经历巨大的**“解除束缚”(unhobbling)**——过去因为人类思考周期不够而没被充分处理的数字信息,会被大规模重写。物理世界会滞后。
他特意指出:这不意味着操纵数字信息的职业一定会减少——需求弹性等因素会起作用。他对软件工程“谨慎乐观”。
用的是经济学中的杰文斯悖论(Jevons Paradox),经典案例就是 ATM 和银行柜员。当年很多人担心 ATM 会取代柜员,但 ATM 降低了银行网点的运营成本,于是开了更多网点,反而雇了更多柜员。
注:杰文斯悖论最初由 19 世纪经济学家提出,指当技术进步提高资源使用效率时,资源消耗反而可能增加而非减少。ATM 的案例虽被广泛引用,但值得注意的是,美国银行柜员数量在 2010 年代确实开始下降。
Karpathy 认为类似的事情正在软件领域发生:软件变便宜了,意味着海量被压抑的需求会释放。代码现在是“临时性的”、可修改的——整个数字基础设施有巨大的重写需求。

但他也坦承自己在预测方面不是专业的。他说了一句更尖锐的话:
我们在 OpenAI 的时候,我跟同事说,你们知道吗,如果我们成功了,我们所有人都失业了。我们本质上就是在给 Sam 或者董事会造自动化系统。 (“I went around OpenAI and I was like, you guys realize if we're successful, we're all out of a job. We're just building automation for Sam or something like that.”)
有些研究人员也在经历同样的焦虑——因为自动化真的在起作用。
为什么不回前沿实验室——独立的代价与价值#
Sarah 替 Noam Brown 问了一个问题:你明明可以在前沿实验室里做 AutoResearch,有大规模算力,有同事——为什么不去?
注:Noam Brown 是博弈论 AI 领域的核心人物,他开发的 Libratus 和 Pluribus 在德州扑克中击败了人类职业选手。Sarah 在访谈中转达了这个问题。
Karpathy 说这个问题很复杂。他确实在前沿实验室待过,也回去过,所以一定程度上他同意实验室内部有价值。但他列出了几个让他选择留在外面的原因。
**第一,利益冲突。**你在前沿实验室有巨大的财务激励。而你自己承认 AI 将以极其戏剧性的方式改变人类社会。你在这里一边造这项技术、一边从中获益、一边被财务手段深度绑定——这个矛盾正是 OpenAI 最初试图解决的问题。这个矛盾至今没有真正解决。
**第二,你不是完全自由的主体。**在前沿实验室内部,有些话你不能说,有些话组织希望你说。
在前沿实验室内部,有些话你不能说,有些话组织希望你说。不会扭你的胳膊,但你能感受到那种压力。 (“If you're inside one of the frontier labs, there are certain things that you can't say, and conversely there are certain things that the organization wants you to say.”)
他没有具体说“不能说的话”是什么,但他说离开之后感觉**“更站在人类一边”**——不再受那些压力的约束。前沿实验室是不透明的,它们在做下一代的东西。离开后你对系统实际工作原理的理解会逐渐过时,判断力会漂移。他说自己也对此焦虑。
他认为理想的方案可能是阶段性进出:进去一段时间做真正有价值的工作,了解实际进展,然后出来保持独立性。他说不管在哪里都可以产生很大的影响,但他倾向于认为像 Noam 这样的人,最有影响力的工作“很可能在 OpenAI 之外”。
他还补充了一个更宏观的担忧:即使你在实验室里参与决策讨论,当真正的高风险时刻到来时,作为一名员工,你对组织行为的实际影响力有多大?“你在房间里贡献想法,但你并不真正掌控那个实体。”
开源生态——意外地落在了一个还不错的位置#
Sarah 问开源离前沿有多近。
Karpathy 说总体趋势是差距在缩小:从最初的完全没有,到落后 18 个月,到现在大约落后 6 到 8 个月。他是开源的坚定支持者,用了 Linux 做类比——Linux 运行在绝大多数的服务器上,因为行业需要一个共同的开放平台,大家用着都安心。AI 领域也是同样的需求。
两个挑战:
- 资本支出是硬约束——训练前沿模型需要大量资金,这让开源竞争更难
- 前沿智能的需求依然存在——类似诺贝尔奖级别的工作,或“把 Linux 从 C 改写成 Rust”这种巨型项目——但这可能是闭源实验室的地盘
开源会蚕食更基础的用例。
Karpathy 说他对中心化天然警惕。他提到东欧的历史教训——“中心化的历史记录很差”。他说在机器学习中,集成模型(ensemble)永远优于任何单一模型,用这个来类比决策:“我希望有更多人在房间里,当最难的决策到来时。”
他还指出了一个让他不安的趋势:即使在闭源端,领先者的圈子也在进一步缩小。不是所有前沿实验室都保持在最顶尖。
他的结论是:目前意外地落在了一个还算可以的位置——闭源在前沿推进,开源落后几个月但覆盖了大量实用场景。他希望这个动态能持续下去。

机器人——原子比比特难一百万倍#
Sarah 问自动驾驶经验对机器人行业有什么启示。
Karpathy 从 Tesla 的经历出发:十年前有大量自动驾驶创业公司,大多数最终没活下来。原因是资本密集、时间漫长、需要巨大的信念感。原子实在太难了。
他提出了一个三阶段路线图:
- 数字空间大规模解除束缚——之前没有足够的人类思考周期来处理的数字信息,现在被 AI 大量重写
- 数字与物理的接口——传感器(看见世界)和执行器(对世界做点什么)。他认为很多有意思的公司会出现在这个接口上。他刚去拜访了 Periodic Labs——他的朋友 Liam Fedus 在那里做 CEO,做的是材料科学的自动研究。传感器不只是摄像头,还有昂贵的实验室设备
- 物理世界的全面渗透——市场规模可能远大于数字空间,但难度也大一百万倍
注:Periodic Labs 由前 OpenAI 研究 VP Liam Fedus 和前 DeepMind 材料科学主管 Ekin Dogus Cubuk 联合创办,2025 年获得 3 亿美元种子轮融资,投资者包括 Andreessen Horowitz、英伟达、Jeff Bezos 和 Eric Schmidt。公司目标是构建能自主运行物理实验的“AI 科学家”。
Karpathy 说了一个有意思的缺失:信息市场。如果 Polymarket 等预测市场有越来越多的自主 Agent 参与,如果伊朗正在发生什么事,从德黑兰拍一张照片应该值 10 美元——不是人在看,是 Agent 在试图判断赌博市场和股票的走势。但目前没有这种机制。
他引用了 Daniel Suarez 的科幻小说《Daemon》——书中的超级智能把人类既当传感器又当执行器,社会围绕着这台机器的需求重新组织。他觉得某种类似的事情正在发生:越来越多的自动化有特定需求,人类会开始服务于那台机器的需求,而非仅仅服务于彼此。
MicroGPT——200 行代码和 Agent 时代的教育#
Sarah 在最后问了 Karpathy 的一个“小”副项目——MicroGPT。
Karpathy 说这是他十几年来反复简化 LLM 到本质的痴迷的终点。之前有 nanoGPT、micrograd、makemore。MicroGPT 是目前的最简形态:约 200 行纯 Python,零依赖,包含完整的 GPT 训练和推理所需的一切——数据集、分词器、自动微分引擎、GPT-2 架构、Adam 优化器、训练循环、推理循环。
注:MicroGPT 于 2026 年 2 月发布,约 200 行代码(含注释)。Karpathy 将其称为“艺术项目”,强调训练神经网络所需的全部算法内容其实极其简洁,其余数百万行代码都是为了效率。
他说了一个对教育有深远影响的观察。过去他会为 MicroGPT 录一个视频逐行讲解。他确实试了——录了一部分,也写了一些引导材料。但他意识到这已经不太需要了。代码就 200 行,任何人都可以让 Agent 用各种方式解释它。
我不再是向人类解释了。我是向 Agent 解释。如果 Agent 理解了,它们可以做路由,用读者的语言、按读者的水平、以无限的耐心来讲解。 (“I'm not explaining to people anymore, I'm explaining it to agents.”)
他说也许将来他会做一个“skill”(课程脚本),描述 Agent 应该按什么顺序带你走过 MicroGPT 的代码。这不是传统的教程——而是指导 Agent 如何教学的元信息。
他试过让 Agent 自己写出 MicroGPT 的极简版本——做不到。200 行是他十几年痴迷的结晶,Agent 无法从零创造,但完全能理解它并解释为什么这样设计。
“这就是我的价值贡献——那几个 bit。其他一切,Agent 都能做。”
他的结论是:教育正在被重定向。不是为人写 HTML 文档了,而是为 Agent 写 Markdown 文档。不是你向人解释了,而是 Agent 替你解释。你的工作是提供 Agent 做不到的那几个关键洞察——课程的正确顺序、更好的解释方式、只有深度理解才能做出的简化。
Agent 做不到的事,才是你的工作。Agent 能做到的事,它们很快就能做得比你好。

整场访谈中 Karpathy 反复回到“AI 精神错乱”这个词。这不是一个负面的描述——更像是一个发现了无限可能但时间有限的人对自己状态的精准诊断。当你觉得一切都是“技能问题”的时候,每一分钟没在探索就是一分钟的浪费。
三个值得持续关注的信号:AutoResearch 的分布式版本(Open Ground)能否真正运转,这将直接影响前沿研究的格局。模型的参差性(在轨道上是超级智能,脱轨是 10 岁小孩)是暂时的还是结构性的,这决定了自主 Agent 能走多远。以及 Karpathy 暗示的前沿实验室进一步中心化的趋势——当决策权集中在越来越少的人手里,他所说的“不能说的话”会变成什么?