初级
驾驭工程学就是控制论
驾驭工程学就是控制论
阅读 OpenAI 的驾驭工程学文章时,我总有一种难以名状的感觉。后来我突然明白了:这种模式我见过。不止一次——是三次。
第一次是 18 世纪 80 年代詹姆斯·瓦特的离心调速器。在此之前,工人站在蒸汽机旁手动调节阀门。之后,一个带配重的飞球机构感知转速并自动调节阀门。工人没有消失,工作内容变了:从转动阀门变成了设计调速器。
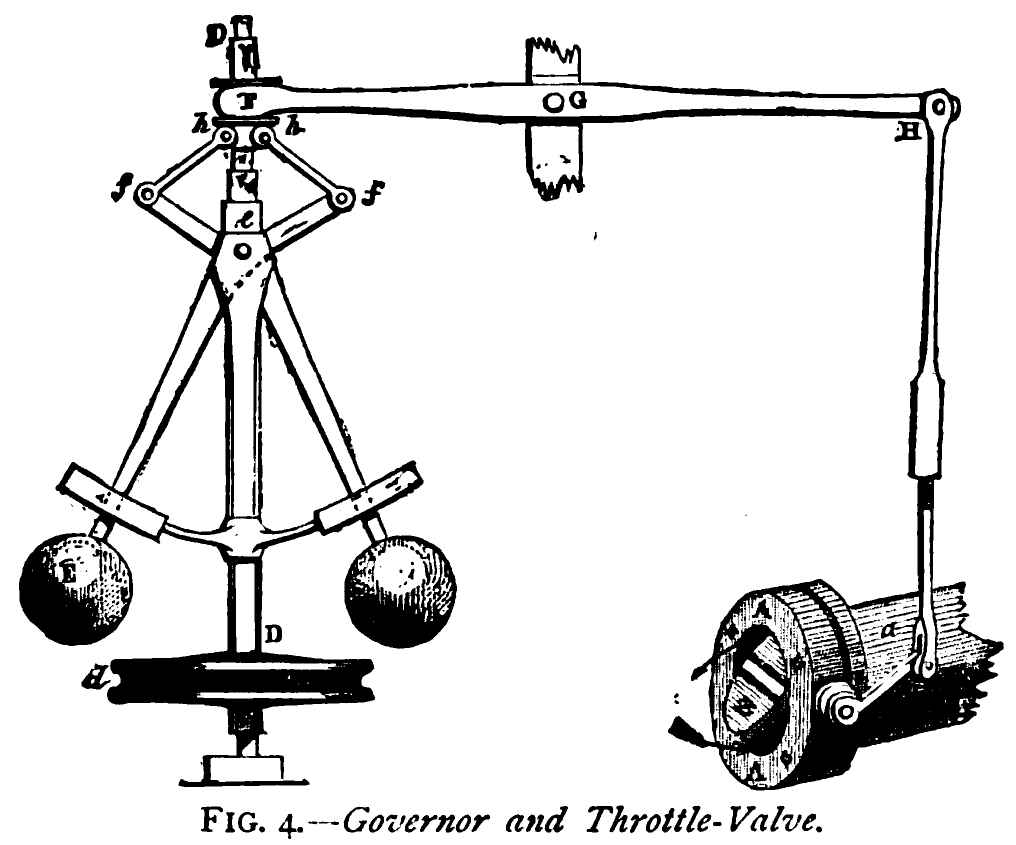
第二次是 Kubernetes。你声明期望状态——三个副本、这个镜像、这些资源限制。控制器持续观察实际状态。当两者出现偏差时,控制器进行协调:重启崩溃的 Pod、扩缩副本、回滚错误的部署。工程师的工作从重启服务转变为编写系统需要协调的规范。
第三次就是现在。OpenAI 描述了一种工程师不再编写代码的模式。相反,他们设计环境、构建反馈循环、将架构约束编码化——然后由智能体来编写代码。五个月内生成一百万行代码,没有一行是手写的。他们称之为“驾驭工程学”。
每次都是相同的模式。诺伯特·维纳在 1948 年将其命名为:控制论(cybernetics),源自希腊语 κυβερνήτης——舵手。这正是 Kubernetes 名称的词源。你不再转动阀门,而是掌舵。
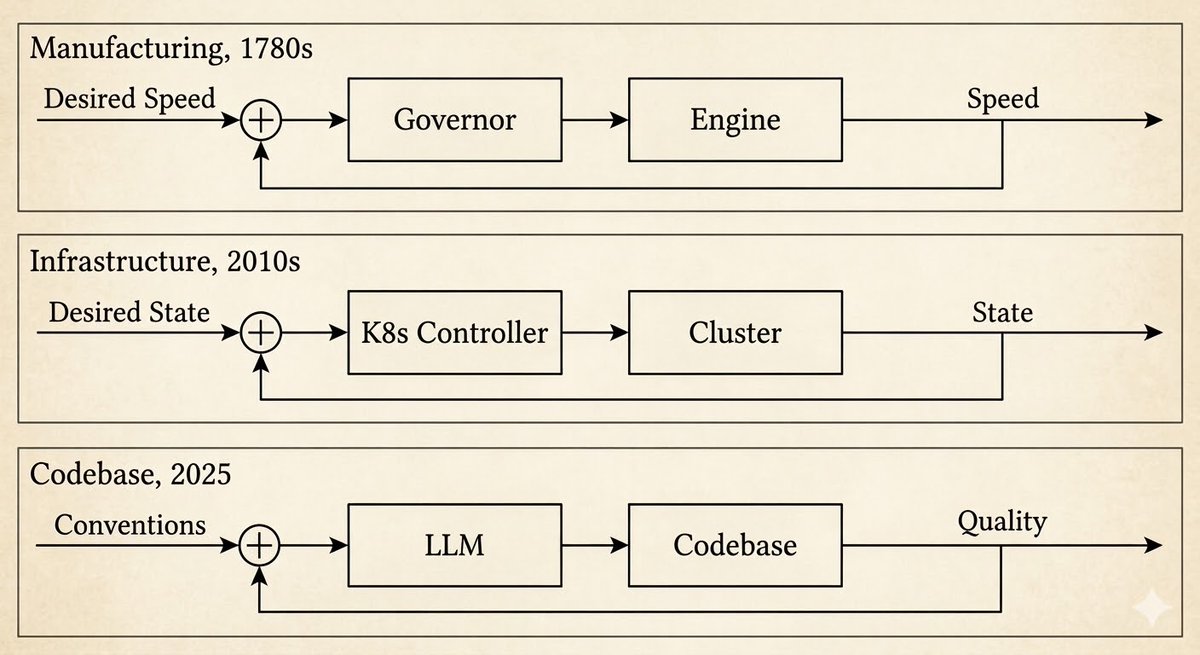
每次这种模式出现,都是因为有人构建了足够强大的传感器和执行器,从而能在该层级上形成闭环。
为什么代码库是最后的堡垒#
代码库本就有反馈循环,但仅限于较低层级。编译器在语法层面形成闭环。测试套件在行为层面形成闭环。代码检查工具在风格层面形成闭环。这些都是真正的控制论控制——但它们只能作用于可机械检查的属性。它能编译吗?能通过测试吗?符合规则吗?
而在此之上的所有问题——这个改动是否符合系统架构?这是正确的方法吗?这个抽象是否会在代码库增长时引发问题?——既没有传感器也没有执行器。只有人类能在该层级操作,同时承担两方面工作:判断质量和编写修复方案。
大语言模型同时改变了这两方面。它们能在人类过去主导的层级进行感知——并在同一层级执行操作:重构模块、重新设计不一致的接口、围绕真正重要的契约重写测试套件。反馈循环首次能在关键决策层面形成闭环。
但形成闭环是必要条件,而非充分条件。瓦特的调速器需要调校。Kubernetes 控制器需要正确的规范。而处理你代码库的大语言模型需要更难以提供的东西。
校准传感器与执行器#
让基础反馈循环运转起来——智能体可运行的测试、能提供可解析输出的 CI、能指向修复方案的错误信息——只是入场券。Carlini 在让 16 个并行智能体构建 C 编译器时证明了这一点:极其简单的提示词,但精心设计的测试基础设施。“我的大部分精力都花在了设计 Claude 周围的环境——测试、环境、反馈。”
更困难的问题是用特定于你系统的知识来校准传感器和执行器。这正是大多数人卡住的地方,也是他们责怪智能体的地方。
“它总是做错事。它不理解我们的代码库。”这个诊断几乎总是错的。智能体失败不是因为它能力不足,而是因为它所需的知识——对你的系统而言什么是“好”、你的架构奖励哪些模式、避免哪些模式——都锁在你的脑子里,而你还没有将其外化。智能体不会通过渗透作用学习。如果你不写下来,智能体在第一百次运行时犯的错误会和第一次一样。
关键在于让你的判断变得机器可读。描述实际分层和依赖方向的架构文档。内置修复说明的自定义代码检查工具。编码团队品味的黄金原则。OpenAI 发现了完全相同的问题:他们每周五花 20% 的时间清理“AI 垃圾”——直到他们将标准编码到驾驭系统本身。
唯一的出路#
这种做法所要求的实践——文档化、自动化测试、编码化的架构决策、快速反馈循环——始终是正确的。过去三十年里每本工程书籍都推荐这些实践。大多数人跳过它们,因为跳过的代价是缓慢而分散的:质量逐渐下降、痛苦的入职过程、悄然累积的技术债务。
智能体工程使这种代价变得极端。跳过文档,智能体会忽略你的约定——不是在一个 PR 上,而是在每个 PR 上,以机器速度,全天候地。跳过测试,反馈循环根本无法形成。跳过架构约束,漂移的累积速度会超过你的修复速度。这里有个陷阱:如果智能体不知道“整洁”是什么样子,你就无法用它们来清理混乱。没有校准,制造问题的机器也无法解决问题。
实践没有改变。忽视它们的惩罚变得无法承受。
生成与验证的不对称性——P 与 NP 问题背后的直觉,由 Cobbe 等人通过大语言模型实证证明——指明了方向。生成正确解决方案比验证解决方案更困难。你不需要在实现上超越机器。你需要在评估上超越它:明确“正确”是什么样子,识别输出何时偏离,判断方向是否正确。
设计瓦特调速器的工人没有回去转动阀门。不是因为他们不能,而是因为这不再有意义。