初级
使用 autoresearch 和 evals-skills 提升 AI 技能
使用 autoresearch 和 evals-skills 提升 AI 技能
我一直在尝试使用 Auto Research 来提升我的 AI 技能,这是 @karpathy 分享的一个用于通过重复实验自动改进 AI 提示词的库。
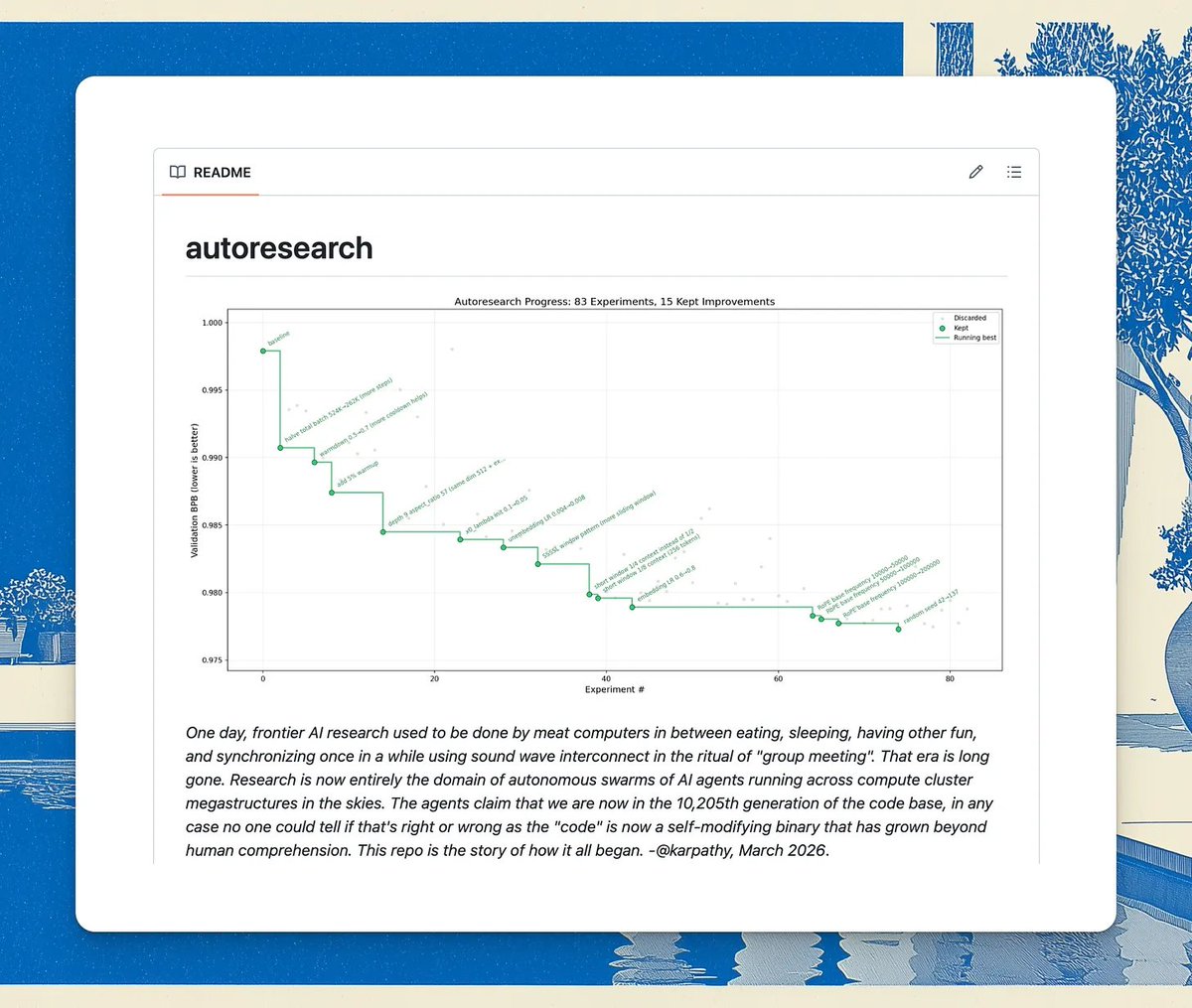
我看到 Ole 在 X 上分享了他对 auto-research 的分支,它变成了一个旨在调整其他技能的技能,于是我决定尝试一下。
思路很直接:定义一些测试输入,编写评估输出分数的评判器,让优化循环运行,醒来时就能得到一个更好的技能。
我运行了三次才明白自己做错了什么。
第一次尝试,我只是把它指向一个技能。#
我挑选了一组我新建的、正准备添加到我的 AI PM 技能库中的技能,把它交给 Auto Research,然后让工具完成其他所有事情。它生成了测试输入。它编写了评判器。它让优化循环运行了一整夜。
分数几乎立刻就上升了。一切看起来都很棒,直到我查看了具体的变化。
不幸的是,技能远未得到改进。
问题不在于工具。Auto Research 完全按照它的设计目的执行:根据你给出的任何标准运行系统化的优化循环。
问题在于标准。它们是机器生成的,没有基于真实失败情况的模型,没有扎根于实际观察到的行为。

因此,循环运行了数百次实验,并且变得非常擅长满足那些标准。技能在错误的事情上变得更好了。
第二次尝试,我接入了 @HamelHusain 的 eval skills 用于输入生成。#
Hamel 与 @sh_reya 在 evals 问题上做了大量工作。
引用的推文 这么多人在谈论 AI 评估。@HamelHusain 和 @sh_reya 向我展示了如何实际构建一个。现场演示。Hamel 和 Shreya 教授世界上最受欢迎的评估课程,并且长期以来一直处于这个对 AI 产品构建者来说新兴且重要的新技能的前沿。我... https://x.com/i/web/status/1971245503972245982
生成合成评估的技能比仅仅要求模型想出测试用例更有原则:你定义输入空间的维度(用户想要什么功能、他们是什么角色、他们处于什么场景),然后在这些组合中生成结构化的元组。

我的输入确实变得更好了:更多样化,更好地覆盖边缘情况,更少凭感觉。
但我再次把生成工作留给了工具。输入有所改善,但改善不大,因为 LLM 仍然在凭感觉生成。我没有手动提供任何输入或修正。评判器也没有改进。
而评判器才是理解所在的地方。
我仍然没有亲自阅读任何输出。仍然没有从观察中建立任何直觉。机器有了更好的输入来工作,但仍然没有真实的失败模型。
第三次尝试,我阅读了 Evals 课程资料 😑#

我将 Hamel 的 evals 课程 的 PDF 阅读器导入到 NotebookLM 中,并在运行任何东西之前,使用 Cursor 中的 NotebookLM CLI 通读了一遍。
通过学习课程,我回忆起了“三个鸿沟”,以及围绕它们构建的“分析-测量-改进”生命周期。
- 理解鸿沟 是你认为你的系统做了什么和它实际做了什么之间的差距。输出中失败的样子,哪些情况会出问题,以何种方式,出于何种原因。这是第一个鸿沟,因为据我所知,必须先跨越它,其他事情才能进行。没有自动化可以跨越它。只有阅读才能跨越它。
- 规范鸿沟 是你希望系统做什么和你的评判器测量什么之间的差距。这似乎是跳过理解步骤的直接后果。如果你没有见过真实的失败,我认为你无法编写出衡量重要事项的评判器。在第一轮和第二轮中,我的评判器测量的是一个想象中的目标。针对这个目标进行优化,就是在针对一个幻想进行优化。
- 泛化鸿沟 是系统在你的测试输入上的表现与在它从未见过的输入上的表现之间的差距。这是 Auto Research 的优化循环可以解决的鸿沟。但前提是前两个鸿沟已经跨越。
课程对此直言不讳:“如果你不愿意定期手动查看一些数据,那么你在评估上就是在浪费时间。”
在前两次尝试中,我就是在评估上浪费时间。
跨越理解鸿沟的手动工作就是 Hamel 所说的错误分析——这是“分析-测量-改进”生命周期的第一阶段。它是这样工作的:
- 开放式编码。在一组多样化的输入上运行你的技能,并阅读每一个输出。先不要分类。只是自由地写下哪里出错了。哪些输出太笼统。哪些遗漏了输入中明确说明的约束。哪些以一种你能感觉到但无法预测的方式偏离了。这是你建立关于失败的直觉的地方,没有工具能为你建立这种直觉。
- 轴向编码。将这些自由笔记分组,形成一个连贯的失败分类法:一小组不同的、二元的失败类别。“太抽象”、“遗漏了企业约束”、“特异性水平错误”。这些将成为你的评判器应该衡量的东西。
- 编写基于分类法的评判器,根据你看到的情况编写。
- 验证评判器。构建一个迷你黄金数据集:在信任任何评判器自主运行之前,手动为每个标准对十五到二十个输出进行评分。这就是你校准规范鸿沟的方式:你检查评判器是否同意你自己在已经推理过的案例上的标签。
然后你才运行 Auto Research。
对于第三次尝试,我在我一直试图改进的技能上运行了这个流程。
我改变了输入。
然后我阅读了它输出的所有内容。
我对失败进行了编码(在聊天中自由记录,这是一种草率的方式),然后 LLM 对它们进行了分组,构建了分类法,据此编写了评判器,我在十五个输出上手动验证了它们。然后循环才运行。

显然,正是这个步骤给技能带来了所有额外的提升:

所以你可以看到,即使在第三次尝试中,我仍然作弊了,没有完全遵循流程,这就是为什么最终结果仍然没有达到我希望技能达到的水平。但观点仍然成立。
在所有三次尝试中重复出现的模式是:我一直想跳过理解步骤,直接进入自动化部分。这感觉像是在加速。但我认为我只是让机器在高效地衡量错误的东西。
评估的挑战在于,目标函数是如此主观,以至于你基本上无法避免首先手动建立测量系统。(除非你能从一开始就将你所有的细微品味上传到一个自动评估器中,也许未来可以。)之后,评判器可以自动化部分过程,但只有在你足够信任它们的判断,可以将其操作化之后。
我认为你无法通过自动化绕过理解。必须有人跨越第一个鸿沟,而根据我的经验,那个人总是你自己。
产品领域的对等物#
产品经理在产品决策上做的事情,和我对 AI 评估做的事情是一样的。
跳过手动理解阶段,直接跳到解决方案或成功指标,然后根据不能反映实际问题的标准进行硬性衡量。“用户需要主动洞察,这很明显。”“我们将衡量 DAU/MAU。”
这就是你最终因为确信用户想要什么而发布一个功能的原因。在理解你要衡量什么之前就设置好仪表板。在没有明确你需要学习什么、为什么重要或你将如何学习的情况下进行探索。没有亲自综合足够的证据来对问题出在哪里形成真正的直觉。
理解鸿沟在产品领域有一个对等物:你认为用户挣扎的地方和他们实际挣扎的地方之间的差距。
它不会因为一个调查仪表板而消失。它会在你亲自阅读了足够多的客户对话、支持工单和访谈,从而对失败的样子有了感觉时消失。这种直觉使你的假设足够具体以便测试,也使你的解决方案足够具体以便真正契合需求。